Aumentar la velocidad del punto de control y reducir el costo con Nebula
Obtenga información sobre cómo aumentar la velocidad de los puntos de control y reducir el coste de los puntos de control para modelos grandes de entrenamiento de Azure Machine Learning usando Nebula.
Información general
Nebula es una herramienta de punto de control rápida, sencilla y sin disco en Azure Container para PyTorch (ACPT). Nebula ofrece una solución sencilla y de alta velocidad de creación de puntos de control para trabajos de entrenamiento distribuido de modelos a gran escala mediante PyTorch. Mediante el uso de las últimas tecnologías informáticas distribuidas, Nebula puede reducir los tiempos de punto de control de horas a segundos, lo que podría ahorrar de un 95 % a un 99,9 % de tiempo. Los trabajos de entrenamiento a gran escala pueden beneficiarse enormemente del rendimiento de Nebula.
Para que Nebula esté disponible para los trabajos de entrenamiento, importe el paquete de Python nebulaml en el script. Nebula es completamente compatible con diferentes estrategias de entrenamiento distribuidas de PyTorch, como PyTorch Lightning, DeepSpeed, etc. Nebula API ofrece una forma sencilla de supervisar y ver los ciclos de vida de los puntos de control. Las API admiten varios tipos de modelos y garantizan la coherencia y confiabilidad de los puntos de control.
Importante
El paquete nebulaml no está disponible en el índice público de paquetes de Python PyPI. Solo estará disponible en el entorno mantenido de Azure Container para PyTorch (ACPT) en Azure Machine Learning. Para evitar problemas, no intente instalar nebulaml desde PyPI ni use el comando pip.
En este documento, aprenderá a usar Nebula con ACPT en Azure Machine Learning para establecer de forma rápida puntos de control en los trabajos de entrenamiento de modelos. Además, aprenderá a ver y administrar los datos de los puntos de control de Nebula. También aprenderá a reanudar los trabajos de entrenamiento de modelos desde el último punto de control disponible si sufriera interrupciones, errores o finalizaciones de Azure Machine Learning.
¿Por qué es importante la optimización de puntos de control para el entrenamiento de modelos grandes?
A medida que los volúmenes de datos crecen y los formatos de datos se vuelven más complejos, los modelos de aprendizaje automático también se han vuelto más sofisticados. El entrenamiento de estos modelos complejos puede ser complicado debido a los límites de capacidad de memoria de GPU y a tiempos de entrenamiento largos. Como resultado, el entrenamiento distribuido se suele usar al trabajar con grandes conjuntos de datos y modelos complejos. Sin embargo, las arquitecturas distribuidas podrían experimentar errores inesperados y errores de nodo, lo que podría resultar cada vez más problemático a medida que aumente el número de nodos de un modelo de aprendizaje automático.
Los puntos de control pueden ayudar a mitigar estos problemas guardando periódicamente instantáneas del estado completo del modelo en un momento dado. En caso de error, esta instantánea se podría usar para volver a generar el modelo en su estado en el momento de la instantánea para que el entrenamiento pueda reanudarse desde ese punto.
Cuando las operaciones de entrenamiento de modelos grandes experimenten errores o finalizaciones, los científicos de datos e investigadores podrán restaurar el proceso de entrenamiento desde un punto de control guardado anteriormente. Sin embargo, cualquier progreso realizado entre el punto de control y la finalización se pierde, ya que los cálculos deberán volver a ejecutarse para recuperar los resultados intermedios no guardados. Los intervalos de punto de control más cortos podrían ayudar a reducir esta pérdida. En el diagrama se muestra el tiempo desperdiciado entre el proceso de entrenamiento de puntos de control y la finalización:

Sin embargo, el proceso de guardar puntos de control en sí podría generar una sobrecarga significativa. Guardar un punto de control de tamaño de TB a menudo podría convertirse en un cuello de botella en el proceso de entrenamiento, con el proceso de punto de control sincronizado bloqueando el entrenamiento durante horas. En promedio, las sobrecargas relacionadas con los puntos de control podrían causar el 12 % del tiempo total de entrenamiento y podrían aumentar hasta un 43 % (Maeng et al., 2021).
En resumen, la administración de puntos de control de modelos de gran tamaño implica un almacenamiento intensivo y sobrecargas del tiempo de recuperación de los trabajos. Los procesos de guardar puntos de control de forma frecuente, combinados con reanudaciones de trabajos de entrenamiento a partir de los puntos de control disponibles más recientes, se convierten en un gran problema.
Nebula al rescate
Para entrenar con eficacia modelos distribuidos grandes, es importante contar con una forma confiable y eficiente de guardar y reanudar el progreso del entrenamiento que minimice la pérdida de datos y el desperdicio de recursos. Nebula ayuda a reducir los tiempos de ahorro de puntos de control y las demandas por hora de GPU para trabajos de entrenamiento de Azure Machine Learning de modelos grandes, ya que proporciona una administración de puntos de control más rápida y sencilla.
Con Nebula es posible:
Aumentar la velocidad de los puntos de control hasta 1000 veces con una API sencilla que trabaja de forma asincrónica con el proceso de entrenamiento. La nebulosa puede reducir los tiempos de los puntos de control de horas a segundos (una potencial reducción del 95 % al 99 %).
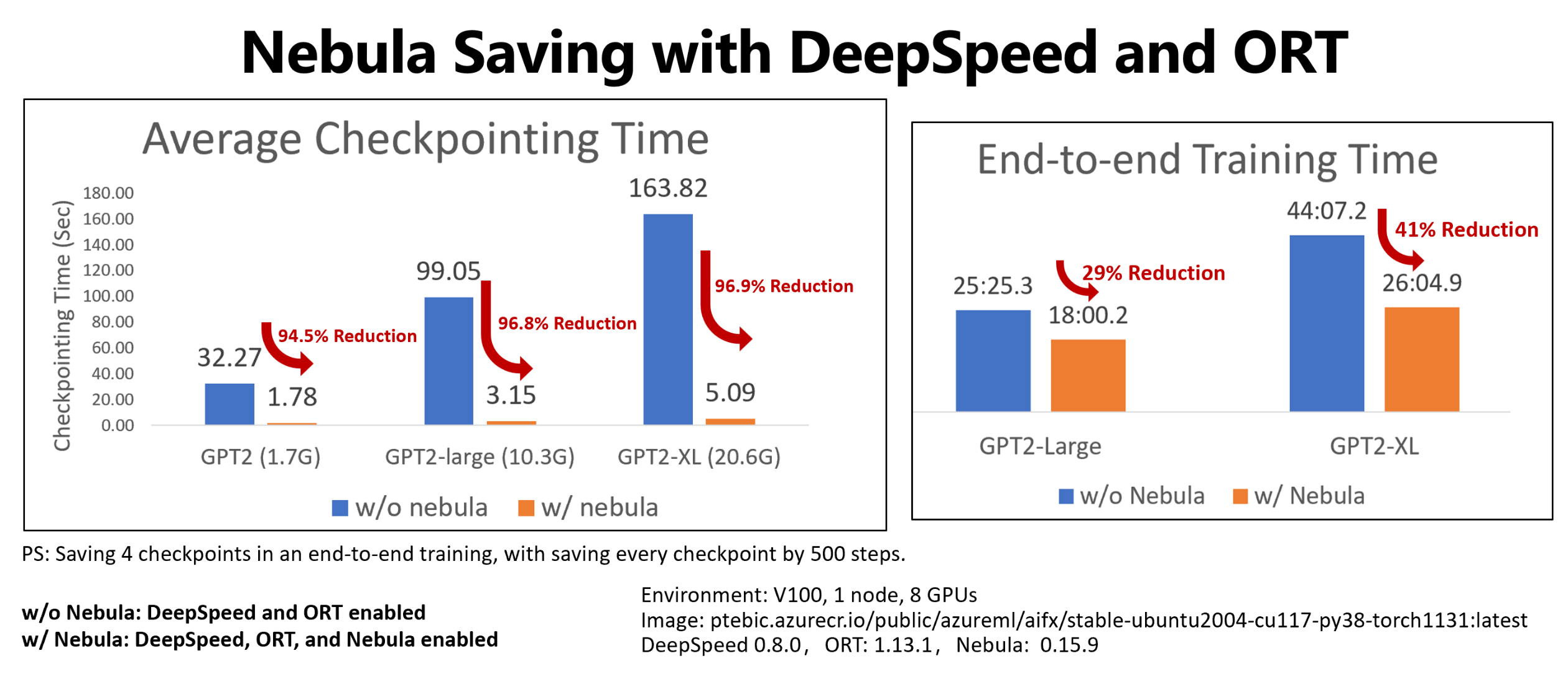
En este ejemplo se muestra la reducción tanto del tiempo de entrenamiento de un extremo a otro como del punto de control al guardar cuatro puntos de control de los trabajos de entrenamiento Hugging Face GPT2, GPT2-Large y GPT-XL. Al guardar el punto de control Hugging Face GPT2-XL de tamaño mediano (20,6 GB), Nebula alcanzó una reducción de tiempo del 96,9 % para un punto de control.
La ganancia en cuanto a velocidad del punto de control se puede aumentar aún más con el tamaño del modelo y el números de GPU. Por ejemplo, la prueba un ahorro de un punto de control en un punto de entrenamiento ahorra 97 GB en 128 GPU A100 Nvidia puede reducirse de 20 minutos a 1 segundo.
Reduzca el tiempo de entrenamiento de un extremo a otro y los costes de cálculo de modelos grandes al minimizar la sobrecarga del punto de control y reducir el número de horas de GPU desperdiciadas en la recuperación de trabajos. Nebula guarda los puntos de control de forma asincrónica y desbloquea el proceso de entrenamiento, lo que reduce el tiempo de entrenamiento de un extremo a otro. También permite guardar puntos de control de forma más frecuente. De este modo, puede reanudar el entrenamiento desde el punto de control más reciente después de cualquier interrupción y ahorrar el tiempo y dinero desperdiciados tanto en la recuperación de trabajos como en el entrenamiento de GPU.
Proporcionar compatibilidad completa con PyTorch. Nebula ofrece compatibilidad completa con PyTorch y ofrece una integración completa con marcos de entrenamiento distribuido, como DeepSpeed (>=0.7.3) y PyTorch-Lightning (>=1.5.0). También puede usar el servicio con diferentes destinos de proceso de Azure Machine Learning, como proceso de Azure Machine Learning o AKS.
Administrar fácilmente los puntos de control con un paquete de Python que ayuda a enumerar, obtener, guardar y cargar los puntos de control. Para mostrar el ciclo de vida de los puntos de control, Nebula también proporciona completos registros en Estudio de Azure Machine Learning. Puede elegir guardar los puntos de control en una ubicación de almacenamiento local o remota, como:
- Azure Blob Storage
- Azure Data Lake Storage
- NFS
Y posteriormente acceder a ellos en cualquier momento con unas algunas líneas de código.

Requisitos previos
- Una suscripción a Azure y un área de trabajo de Azure Machine Learning. Para más información sobre la creación de recursos para áreas de trabajo, consulte Creación de recursos para áreas de trabajo.
- Un destino de proceso de Azure Machine Learning. Consulte Administración de procesos de entrenamiento e implementación para obtener más información sobre la creación de destino de proceso.
- Un script de entrenamiento que use PyTorch.
- Un entorno mantenido de ACPT (Azure Container para PyTorch). Para obtener la imagen de ACPT, consulte Entornos mantenidos. Obtenga información sobre cómo usar el entorno mantenido.
Uso de Nebula
Nebula permite usar los puntos de control de forma rápida y sencilla en el script de entrenamiento existente. Los pasos del inicio rápido de Nebula incluyen:
- Uso del entorno de ACPT
- Inicialización de Nebula
- Llamadas API para guardar y cargar puntos de control
Uso del entorno de ACPT
Azure Container para PyTorch (ACPT) es un entorno mantenido para el entrenamiento de modelos de PyTorch que incluye Nebula como paquete de Python dependiente preinstalado. Consulte Azure Container para PyTorch (ACPT) para ver el entorno mantenido y Habilitación del aprendizaje profundo con Azure Container para PyTorch en Azure Machine Learning para más información sobre la imagen de ACPT.
Inicialización de Nebula
Para habilitar Nebula con el entorno de ACPT, solo tiene que modificar el script de entrenamiento para importar el paquete nebulaml y, a continuación, llamar a las API de Nebula en los lugares adecuados. Puede evitar la modificación del SDK o la CLI de Azure Machine Learning. También puede evitar la modificación de otros pasos para entrenar el modelo grande en la plataforma de Azure Machine Learning.
Nebula necesita inicialización para ejecutarse en el script de entrenamiento. En la fase de inicialización, especifique las variables que determinan la ubicación y la frecuencia de guardado de los puntos de control, como se muestra en este fragmento de código:
import nebulaml as nm
nm.init(persistent_storage_path=<YOUR STORAGE PATH>) # initialize Nebula
Nebula se ha integrado en DeepSpeed y PyTorch Lightning, lo que ha simplificado y facilitado la inicialización. En estos ejemplos se muestra cómo integrar Nebula en los scripts de entrenamiento.
Importante
El ahorro de puntos de control con Nebula requiere memoria para almacenar puntos de control. Asegúrese de que la memoria sea mayor que al menos tres copias de los puntos de control.
Si la memoria no fuera suficiente para contener puntos de control, se recomienda configurar una variable de entorno NEBULA_MEMORY_BUFFER_SIZE en el comando para limitar el uso de la memoria por cada nodo al guardar puntos de control. Al establecer esta variable, Nebula usará esta memoria como búfer para guardar los puntos de control. Si el uso de memoria no estuviera limitado, Nebula usará la memoria tanto como sea posible para almacenar los puntos de control.
Si varios procesos se ejecutasen en el mismo nodo, la memoria máxima para guardar puntos de control será la mitad del límite dividido por el número de procesos. Nebula usará la otra mitad para la coordinación multiproceso. Por ejemplo, si deseara limitar el uso de memoria por cada nodo a 200 MB, podría establecer la variable de entorno como export NEBULA_MEMORY_BUFFER_SIZE=200000000 (en bytes, alrededor de 200 MB) en el comando. En este caso, Nebula solo usará 200 MB de memoria para almacenar los puntos de control en cada nodo. Si hubiera 4 procesos ejecutándose en el mismo nodo, Nebula usará 25 MB de memoria por cada proceso para almacenar los puntos de control.
Llamadas API para guardar y cargar puntos de control
Nebula proporciona API para controlar los procesos de guardado de puntos de control. Estas API se pueden usar en los scripts de entrenamiento, de forma similar a la API torch.save() de PyTorch. En estos ejemplos se muestra cómo usar Nebula en los scripts de entrenamiento.
Visualización de los historiales de los puntos de control
Cuando finalice el trabajo de entrenamiento, vaya al panel Name> Outputs + logs del trabajo. En el panel izquierdo, expanda la carpeta Nebula y seleccione checkpointHistories.csv para ver información detallada sobre los procesos de guardado de puntos de control de Nebula (duración, rendimiento y tamaño de los puntos de control).

Ejemplos
En estos ejemplos se muestra cómo usar Nebula con diferentes tipos de marcos. Puede elegir el ejemplo que mejor se adapte al script de entrenamiento.
Para habilitar la compatibilidad completa de Nebula con scripts de entrenamiento basados en PyTorch, modifique el script de entrenamiento según sea necesario.
En primer lugar, importe el paquete
nebulamlnecesario:# Import the Nebula package for fast-checkpointing import nebulaml as nmPara inicializar Nebula, llame a la función
nm.init()enmain(), como se muestra aquí:# Initialize Nebula with variables that helps Nebula to know where and how often to save your checkpoints persistent_storage_path="/tmp/test", nm.init(persistent_storage_path, persistent_time_interval=2)Para guardar los puntos de control, reemplace la instrucción original
torch.save()para guardar el punto de control con Nebulosa. Asegúrese de que la instancia de punto de control comienza por "global_step", como "global_step500" o "global_step1000":checkpoint = nm.Checkpoint('global_step500') checkpoint.save('<CKPT_NAME>', model)Nota:
<'CKPT_TAG_NAME'>es el identificador único para el punto de control. Normalmente, una etiqueta es el número de pasos, el número de época o cualquier nombre definido por el usuario. El parámetro opcional<'NUM_OF_FILES'>especifica el número de estado que se guardaría para esta etiqueta.Cargue el punto de control válido más reciente, como se muestra aquí:
latest_ckpt = nm.get_latest_checkpoint() p0 = latest_ckpt.load(<'CKPT_NAME'>)Dado que un punto de control o instantánea puede contener muchos archivos, puede cargar uno o varios de ellos por nombre. Con el punto de control más reciente, el estado del entrenamiento se puede restaurar al estado guardado por el último punto de control.
Otras API pueden controlar la administración de los puntos de control:
- Enumerar todos los puntos de control.
- Obtener los puntos de control más recientes.
# Managing checkpoints ## List all checkpoints ckpts = nm.list_checkpoints() ## Get Latest checkpoint path latest_ckpt_path = nm.get_latest_checkpoint_path("checkpoint", persisted_storage_path)