Guía de solución de problemas
En este artículo se tratan preguntas frecuentes sobre el uso del flujo de avisos.
Problemas relacionados con la creación de flujos
Se produce el error "Package tool isn't found" ("No se encuentra la herramienta del paquete") al actualizar el flujo de una solución orientada al código
Al actualizar flujos para una experiencia de código primero, si el flujo utilizó la búsqueda de índices Faiss, la búsqueda de índices vectoriales, la búsqueda de base de datos vectoriales o las herramientas de seguridad de contenido (texto), es posible que encuentre el siguiente mensaje de error:
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
Tiene dos opciones para resolver este problema:
Opción 1
Actualice la sesión de proceso a la versión de la imagen base más reciente.
Seleccione modo de archivo sin formato para cambiar a la vista de código sin procesar. A continuación, abra el archivo flow.dag.yaml.

Actualice los nombres de las herramientas.
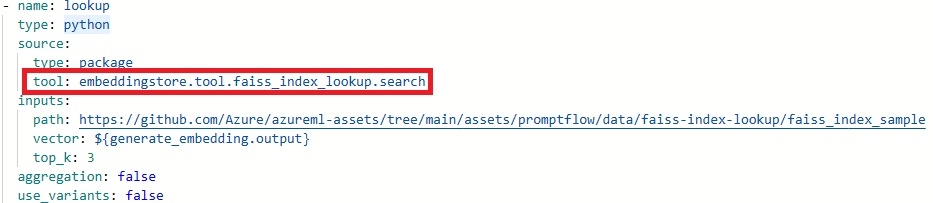
Herramienta Nuevo nombre de herramienta Faiss Index Lookup promptflow_vectordb.tool.faiss_index_lookup. FaissIndexLookup.search Búsqueda de índices vectoriales promptflow_vectordb.tool.vector_index_lookup. VectorIndexLookup.search Búsqueda en la base de datos de vectores promptflow_vectordb.tool.vector_db_lookup. VectorDBLookup.search Seguridad de los contenidos (texto) content_safety_text.tools.content_safety_text_tool.analyze_text Guarde el archivo flow.dag.yaml.
Opción 2
- Actualización de la sesión de proceso a la versión de la imagen base más reciente
- Quite la herramienta anterior y vuelva a crear una nueva herramienta.
Error "No such file or directory" ("No existe el archivo o directorio")
El flujo de avisos se basa en un almacenamiento de recurso compartido de archivos para almacenar una instantánea del flujo. Si el almacenamiento del recurso compartido de archivos tiene un problema, es posible que encuentre el siguiente problema. Estas son algunas soluciones alternativas que puede probar:
Si usa una cuenta de almacenamiento privada, consulte Aislamiento de red en el flujo de avisos para asegurarse de que el área de trabajo pueda acceder a la cuenta de almacenamiento.
Si la cuenta de almacenamiento está habilitada para el acceso público, compruebe si hay un almacén de datos denominado
workspaceworkingdirectoryen el área de trabajo. Debe ser un tipo de recurso compartido de archivos.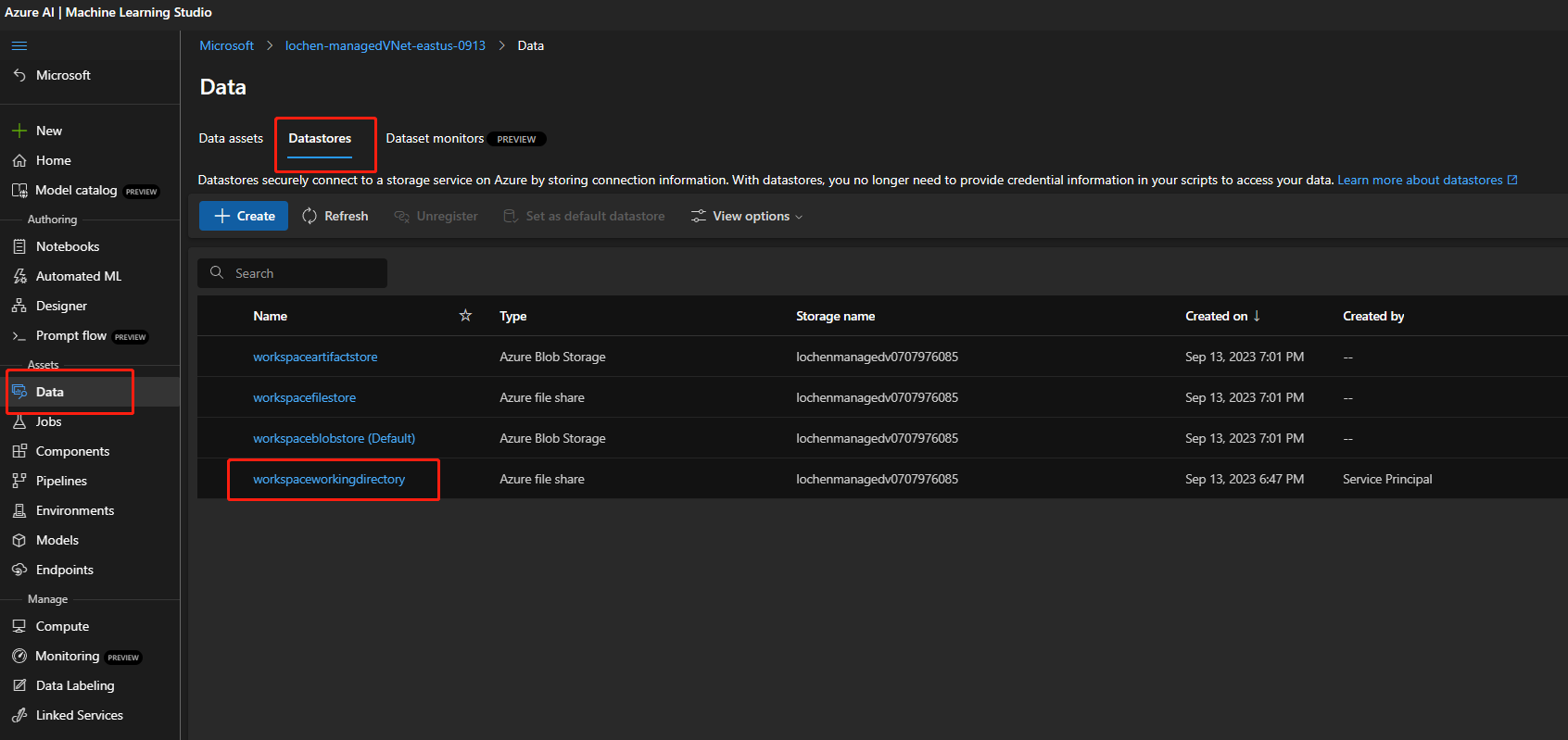
- Si no ha encontrado este almacén de datos, debe agregarlo en el área de trabajo.
- Cree un recurso compartido de archivos con el nombre
code-391ff5ac-6576-460f-ba4d-7e03433c68b6. - Cree un almacén de datos con el nombre
workspaceworkingdirectory. Consulte Creación de almacenes de datos.
- Cree un recurso compartido de archivos con el nombre
- Si tiene un almacén de datos
workspaceworkingdirectory, pero su tipo esbloben lugar defileshare, cree una nueva área de trabajo. Use almacenamiento que no habilite espacios de nombres jerárquicos para Azure Data Lake Storage Gen2 como una cuenta de almacenamiento predeterminada del área de trabajo. Para obtener más información, consulte Crear área de trabajo.
- Si no ha encontrado este almacén de datos, debe agregarlo en el área de trabajo.

Falta el flujo

Hay posibles razones para este problema:
Si el acceso público a la cuenta de almacenamiento está deshabilitado, debe asegurarse de que el acceso se agrega a la dirección IP al firewall de almacenamiento o habilita el acceso a través de una red virtual que tiene un punto de conexión privado conectado a la cuenta de almacenamiento.
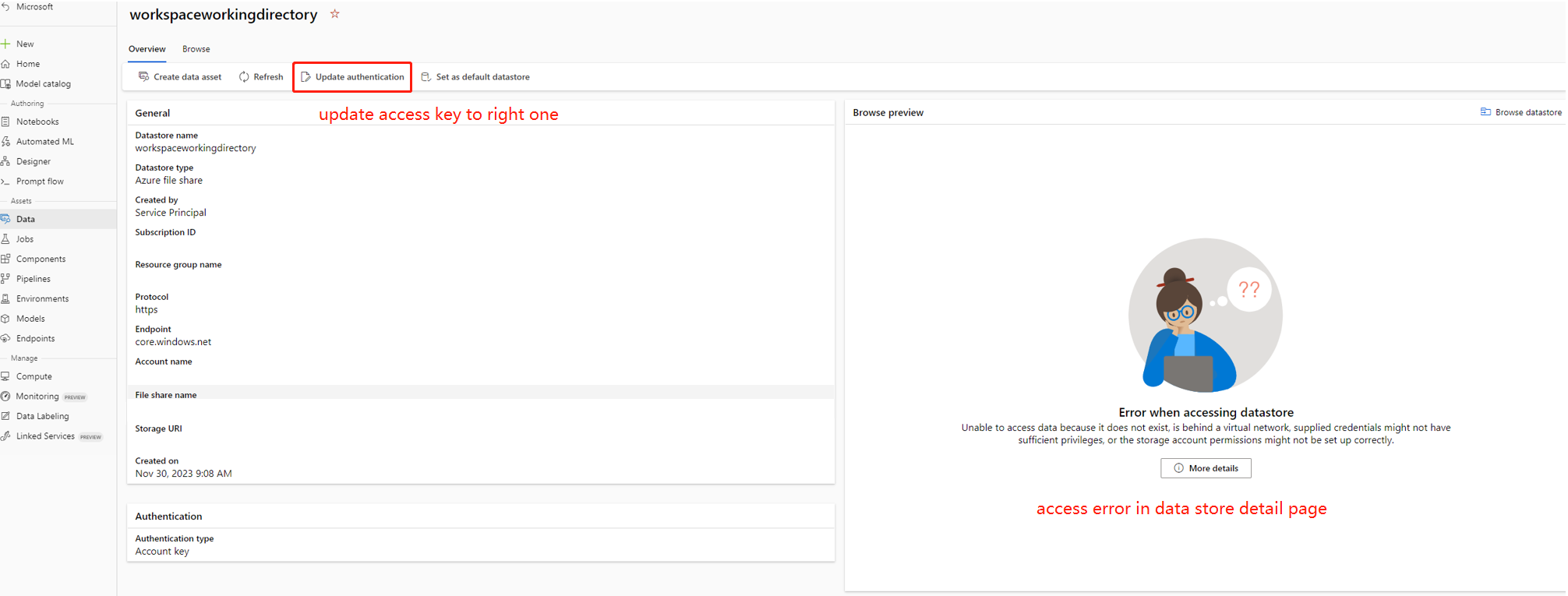
En algunos casos, la clave de cuenta en el almacén de datos no está sincronizada con la cuenta de almacenamiento, puede intentar actualizar la clave de cuenta en la página de detalles del almacén de datos para corregirlo.
Si usa AI Studio, la cuenta de almacenamiento debe establecer CORS para permitir que AI Studio acceda a la cuenta de almacenamiento; de lo contrario, verá que falta el flujo. Puede agregar la siguiente configuración de CORS a la cuenta de almacenamiento para corregir este problema.
- Vaya a la página de la cuenta de almacenamiento, seleccione
Resource sharing (CORS)ensettingsy seleccione la pestañaFile service. - Orígenes permitidos:
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - Métodos permitidos:
DELETE, GET, HEAD, POST, OPTIONS, PUT
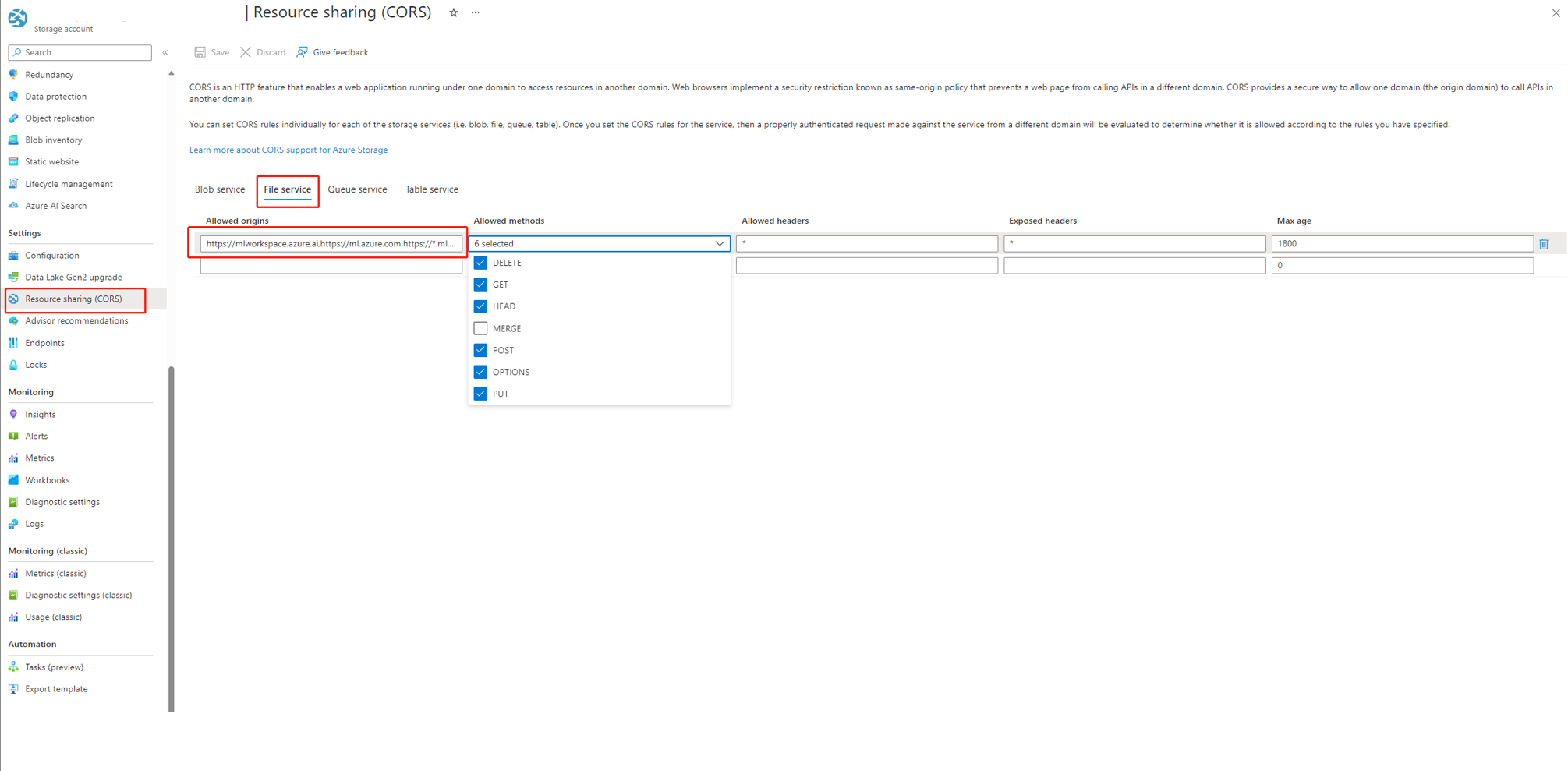
- Vaya a la página de la cuenta de almacenamiento, seleccione



Problemas relacionados con la sesión de proceso
Error de ejecución: "No module named XXX" ("No hay ningún módulo llamado XXX")
Este tipo de error relacionado con la sesión de proceso carece de paquetes necesarios. Si usa un entorno predeterminado, asegúrese de que la imagen de la sesión de proceso usa la versión más reciente. Si usa una imagen base personalizada, asegúrese de instalar todos los paquetes necesarios en el contexto de Docker. Para obtener más información, consulte Personalización de la imagen base para la sesión de proceso.
¿Dónde encontrar la instancia sin servidor usada por la sesión de proceso?
Puede ver la instancia sin servidor que usa la sesión de proceso en la pestaña lista de sesiones de proceso en la página proceso. Obtenga más información sobre cómo administrar la instancia sin servidor.
Errores de sesión de proceso mediante una imagen base personalizada
Error de inicio de sesión de proceso con requirements.txt o imagen base personalizada
Compatibilidad con la sesión de proceso para usar requirements.txt o la imagen base personalizada en flow.dag.yaml para personalizar la imagen. Se recomienda usar requirements.txt para casos comunes, que usarán pip install -r requirements.txt para instalar los paquetes. Si tiene una dependencia mayor que los paquetes de Python, debe seguir Personalizar la imagen base para crear una nueva base de imágenes sobre la imagen base del flujo de avisos. Después, úsela en flow.dag.yaml. Más información sobre cómo especificar la imagen base en la sesión de proceso.
- No puede usar una imagen base arbitraria para crear una sesión de proceso; debe usar la imagen base que proporciona el flujo de aviso.
- No ancle la versión de
promptflowypromptflow-toolsenrequirements.txt, porque ya las incluimos en la imagen base. El uso de la versión anterior depromptflowypromptflow-toolspuede provocar un comportamiento inesperado.
Problemas relacionados con la ejecución de flujo
¿Cómo encontrar las entradas y salidas sin procesar en la herramienta de LLM para una investigación más detallada?
En el flujo de avisos, en la página flujo con la página de detalles de ejecución y ejecución correctas, puede encontrar las entradas y salidas sin procesar de la herramienta LLM en la sección de salida. Seleccione el botón view full output para ver la salida completa.

La sección Trace incluye cada solicitud y respuesta a la herramienta LLM. Puede comprobar el mensaje sin procesar enviado al modelo LLM y la respuesta sin procesar del modelo LLM.

¿Cómo corregir el error 409 de Azure OpenAI?
Es posible que encuentre un error 409 de Azure OpenAI, lo que significa que ha alcanzado el límite de velocidad de Azure OpenAI. Puede comprobar el mensaje de error en la sección de salida del nodo LLM. Obtenga más información sobre límite de velocidad de Azure OpenAI.

Identificar qué nodo consume más tiempo
Compruebe los registros de sesión de proceso.
Intente encontrar el siguiente formato de registro de advertencia:
{node_name} se ha estado ejecutando durante {duration} segundos.
Por ejemplo:
Caso 1: el nodo de script de Python se ejecuta durante mucho tiempo.

En este caso, puede encontrar que
PythonScriptNodese estaba ejecutando durante mucho tiempo (casi 300 segundos). A continuación, puede comprobar los detalles del nodo para ver cuál es el problema.Caso 2: el nodo LLM se ejecuta durante mucho tiempo.
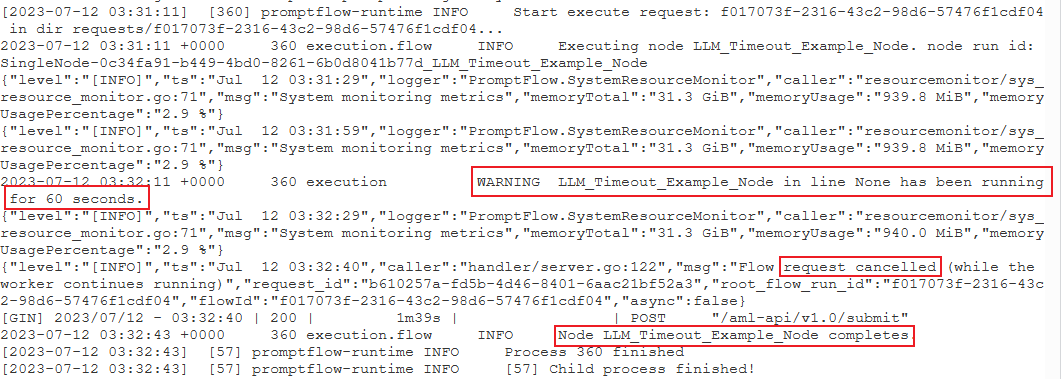
En este caso, si encuentra el mensaje
request canceleden los registros, puede deberse a que la llamada API de OpenAI tarda demasiado tiempo y supera el límite de tiempo de espera.El tiempo de espera de la API de OpenAI puede deberse a un problema de red o a una solicitud compleja que requiera más tiempo de procesamiento. Para más información, consulte Tiempo de espera de la API de OpenAI.
Espere unos segundos y vuelva a intentar la solicitud. Esta acción suele resolver cualquier problema de red.
Si el reintento no funciona, compruebe si usa un modelo de contexto largo, como
gpt-4-32k, y ha establecido un valor grande paramax_tokens. Si es así, se espera el comportamiento porque el mensaje podría generar una respuesta larga que tarde más tiempo que el umbral superior del modo interactivo. En esta situación, se recomienda probarBulk testporque este modo no tiene una configuración de tiempo de espera.
Si no encuentra nada en los registros que indique que se trata de un problema específico de un nodo:
- Póngase en contacto con el equipo del flujo de avisos (promptflow-eng) con los registros. Intentamos identificar la causa principal.


Problemas relacionados con la implementación de flujo
Falta autorización para realizar la acción "Microsoft.MachineLearningService/workspaces/datastores/read"
Si el flujo contiene la herramienta Búsqueda de índices, después de implementar el flujo, el punto de conexión debe acceder al almacén de datos del área de trabajo para leer el archivo yaml de MLIndex o la carpeta FAISS que contiene fragmentos e incrustaciones. Por lo tanto, debe conceder manualmente el permiso de identidad del punto de conexión para hacerlo.
Puede conceder la identidad del punto de conexión AzureML Data Scientist en el ámbito del área de trabajo, o un rol personalizado que contenga la acción "MachineLearningService/workspace/datastore/reader".
Problema de tiempo de espera de solicitud ascendente al consumir el punto de conexión
Si usa la CLI o el SDK para implementar el flujo, puede producirse un error de tiempo de espera. De manera predeterminada, el request_timeout_ms es 5000. Puede especificar un máximo de 5 minutos, que son 300 000 ms. A continuación se muestra cómo especificar el tiempo de espera de la solicitud en el archivo yaml de implementación. Para obtener más información, consulte el esquema de implementación.
request_settings:
request_timeout_ms: 300000
La API de OpenAI alcanza el error de autenticación
Si vuelve a generar la clave de Azure OpenAI y actualiza manualmente la conexión que se usa en el flujo de solicitud, puede que encuentre errores como "No autorizado. Falta el token de acceso, no es válido, la audiencia es incorrecta o ha expirado." al invocar un punto de conexión existente creado antes de volver a generar la clave.
Esto se debe a que las conexiones usadas en los puntos de conexión o las implementaciones no se actualizarán automáticamente. Cualquier cambio de clave o de secretos en las implementaciones se debe realizar mediante la actualización manual, lo que pretende evitar afectar a la implementación de producción en línea debido a una operación sin conexión involuntaria.
- Si el punto de conexión se implementó en la interfaz de usuario de Studio, puede volver a implementar el flujo en el punto de conexión existente con el mismo nombre de implementación.
- Si el punto de conexión se implementó mediante el SDK o la CLI, debe realizar alguna modificación en la definición de implementación, como agregar una variable de entorno ficticia y, a continuación, usar
az ml online-deployment updatepara actualizar la implementación.
Problemas de vulnerabilidad en las implementaciones de flujo de solicitud
En el caso de las vulnerabilidades relacionadas con el tiempo de ejecución del flujo de solicitud, estos son los enfoques que pueden ayudar a mitigar:
- Actualice los paquetes de dependencias del archivo requirements.txt en la carpeta de flujo.
- Si usa una imagen base personalizada para el flujo, debe actualizar el tiempo de ejecución del flujo de mensajes a la versión más reciente y volver a generar la imagen base y, a continuación, volver a implementar el flujo.
Para cualquier otra vulnerabilidad de las implementaciones en línea administradas, Azure Machine Learning corrige los problemas de forma mensual.
"Error MissingDriverProgram" o "No se pudo encontrar el programa de controladores en la solicitud".
Si implementa el flujo y encuentra el siguiente error, podría estar relacionado con el entorno de implementación.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
Existen dos formas de solucionar este error.
(Recomendado) Puede encontrar el identificador URI de la imagen de contenedor en la página de detalles del entorno personalizado y establecerlo como la imagen base de flujo en el archivo flow.dag.yaml. Al implementar el flujo en la interfaz de usuario, solo tiene que seleccionar Usar entorno de definición de flujo actualy el servicio back-end creará el entorno personalizado en función de esta imagen base y
requirement.txtpara la implementación. Obtenga más información sobre el entorno especificado en la definición de flujo.
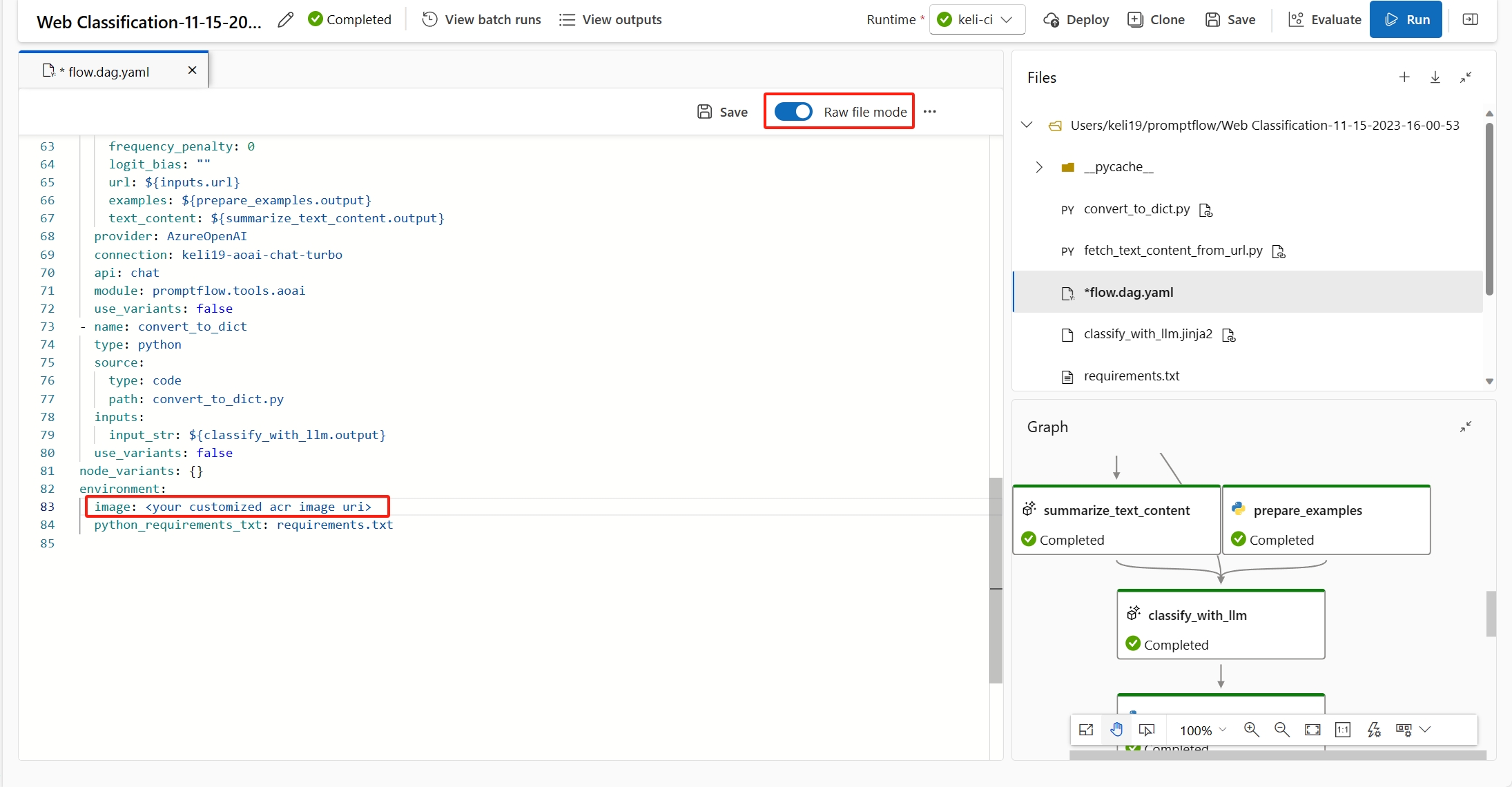
Para corregir este error, agregue
inference_configen la definición de entorno personalizada.A continuación se muestra un ejemplo de definición de entorno personalizada.


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
La respuesta del modelo tarda demasiado tiempo
A veces, es posible que observe que la implementación tarda demasiado tiempo en responder. Hay varios factores potenciales para que esto ocurra.
- El modelo usado en el flujo no es lo suficientemente eficaz (por ejemplo: use GPT 3.5 en lugar de text-ada)
- La consulta de índice no está optimizada y tarda demasiado tiempo.
- El flujo tiene muchos pasos para procesar
Considere la posibilidad de optimizar el punto de conexión con las consideraciones anteriores para mejorar el rendimiento del modelo.
No se puede capturar el esquema de implementación
Después de implementar el punto de conexión y probarlo en la pestaña Prueba de la página de detalles del punto de conexión, si la pestaña Prueba muestra No se puede capturar el esquema de implementación, puede probar los dos métodos siguientes para mitigar este problema:

- Asegúrese de que ha concedido el permiso correcto a la identidad del punto de conexión. Obtenga más información sobre cómo conceder permiso a la identidad del punto de conexión.
- Puede ser porque ejecutó el flujo en un runtime de una versión anterior y después implementó el flujo que la implementación usó el entorno del runtime que también estaba en la versión anterior. Para actualizar el runtime, siga Actualización de un runtime en la interfaz de usuario y vuelva a ejecutar el flujo en el runtime más reciente y después vuelva a implementar el flujo.
Acceso denegado a enumerar el secreto del área de trabajo
Si se produce un error como "Acceso denegado a enumerar el secreto del área de trabajo", compruebe si ha concedido el permiso correcto a la identidad del punto de conexión. Obtenga más información sobre cómo conceder permiso a la identidad del punto de conexión.
Problemas relacionados con la autenticación e identidad
¿Cómo puedo usar el almacén de datos sin credenciales en el flujo de avisos?
Para usar el almacenamiento sin credenciales en Azure AI Studio. Básicamente, necesita hacer lo siguiente:
- Cambie el tipo de autenticación del almacén de datos a Ninguno.
- Conceda permiso msi de proyecto y colaborador de datos de blobs o archivos de usuario en el almacenamiento.
Cambio del tipo de autenticación del almacén de datos a Ninguno
Puede seguir la autenticación de datos basada en identidades de esta parte para que las credenciales del almacén de datos sean menos.
Debe cambiar el tipo de autenticación de almacén de datos a Ninguno, que significa meid_token autenticación basada en . Puede realizar cambios desde la página de detalles del almacén de datos o la CLI o el SDK: https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

En el caso del almacén de datos basado en blobs, puede cambiar el tipo de autenticación y también habilitar MSI del área de trabajo para acceder a la cuenta de almacenamiento.

En el caso del almacén de datos basado en el recurso compartido de archivos, solo puede cambiar el tipo de autenticación.

Concesión de permisos a la identidad de usuario o a la identidad administrada
Para usar el almacén de datos sin credenciales en el flujo de solicitud, debe conceder permisos suficientes a la identidad del usuario o a la identidad administrada para acceder al almacén de datos.
- Asegúrese de que la identidad administrada asignada por el sistema del área de trabajo tiene
Storage Blob Data ContributoryStorage File Data Privileged Contributoren la cuenta de almacenamiento, al menos necesita permiso de lectura y escritura (también incluir eliminación). - Si usa la identidad de usuario esta opción predeterminada en el flujo de solicitud, debe asegurarse de que la identidad de usuario tiene el rol siguiente en la cuenta de almacenamiento:
Storage Blob Data Contributoren la cuenta de almacenamiento, al menos necesita permiso de lectura y escritura (mejor también incluir eliminación).Storage File Data Privileged Contributoren la cuenta de almacenamiento, al menos necesita permiso de lectura y escritura (mejor también incluir eliminación).
- Si usa la identidad administrada asignada por el usuario, debe asegurarse de que la identidad administrada tiene el rol siguiente en la cuenta de almacenamiento:
Storage Blob Data Contributoren la cuenta de almacenamiento, al menos necesita permiso de lectura y escritura (mejor también incluir eliminación).Storage File Data Privileged Contributoren la cuenta de almacenamiento, al menos necesita permiso de lectura y escritura (mejor también incluir eliminación).- Mientras tanto, debe asignar el rol de identidad
Storage Blob Data Readde usuario a la cuenta de almacenamiento al menos, si desea usar el flujo de solicitud para crear y probar el flujo.
- Si todavía no puede ver la página de detalles del flujo y la primera vez que usa el flujo de solicitud es anterior a 2024-01-01, debe conceder msi al área de trabajo como
Storage Table Data Contributora la cuenta de almacenamiento vinculada con el área de trabajo.