Uso de trabajos paralelos en canalizaciones
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
En este artículo se explica cómo usar la CLI v2 y el SDK de Python v2 para ejecutar trabajos paralelos en canalizaciones de Azure Machine Learning. Los trabajos paralelos aceleran la ejecución de trabajos mediante la distribución de tareas repetidas en clústeres de proceso multinodo eficaces.
Los ingenieros de aprendizaje automático siempre tienen requisitos de escala en sus tareas de entrenamiento o inferencia. Por ejemplo, cuando un científico de datos proporciona un único script para entrenar un modelo de predicción de ventas, los ingenieros de aprendizaje automático deben aplicar esta tarea de entrenamiento a cada almacén de datos individual. Los desafíos de este proceso de escalabilidad horizontal incluyen tiempos de ejecución largos que provocan retrasos y problemas inesperados que requieren intervención manual para mantener la tarea en ejecución.
El trabajo principal de la paralelización de Azure Machine Learning es dividir una única tarea en serie en minilotes y distribuir esos minilotes a varios procesos para que se ejecuten en paralelo. Los trabajos paralelos reducen significativamente el tiempo de ejecución de un extremo a otro y también controlan los errores automáticamente. Considere el uso de trabajos paralelos de Azure Machine Learning para entrenar muchos modelos sobre sus datos particionados o para acelerar sus tareas de inferencia por lotes a gran escala.
Por ejemplo, en un escenario en el que se ejecuta un modelo de detección de objetos en un gran conjunto de imágenes, los trabajos paralelos de Azure Machine Learning permiten distribuir fácilmente las imágenes para ejecutar código personalizado en paralelo en un clúster de proceso específico. La paralelización puede reducir significativamente el costo de tiempo. Los trabajos paralelos de Azure Machine Learning también pueden simplificar y automatizar el proceso para que sea más eficaz.
Requisitos previos
- Tener una cuenta y un área de trabajo de Azure Machine Learning.
- Comprender canalizaciones de Azure Machine Learning.
- Instale la CLI de Azure y la extensión
ml. Para más información, consulte Instalación, configuración y uso de la CLI v2. La extensiónmlse instala de forma automática la primera vez que ejecuta un comandoaz ml. - Obtenga información sobre cómo crear y ejecutar canalizaciones y componentes de Azure Machine Learning con la CLI v2.
Crear y ejecutar una canalización con un paso de trabajo paralelo
Un trabajo paralelo de Azure Machine Learning solo se puede usar como paso en un trabajo de canalización.
Los siguientes ejemplos provienen de Ejecutar un trabajo de canalización utilizando trabajo paralelo en canalización en el repositorio de ejemplos de Azure Machine Learning.
Preparación para la paralelización
Este paso de trabajo paralelo requiere preparación. Necesita un script de entrada que implemente las funciones predefinidas. También debe establecer atributos en la definición del trabajo paralelo que:
- Defina y enlace los datos de entrada.
- Establezca el método de división de datos.
- Configure los recursos de proceso.
- Llame al script de entrada.
En las siguientes secciones se describe cómo preparar el trabajo paralelo.
Declaración de las entradas y la configuración de división de datos
Un trabajo paralelo requiere que se divida y procese una entrada principal en paralelo. El formato de datos de entrada principal puede ser datos tabulares o una lista de archivos.
Los diferentes formatos de datos tienen diferentes tipos de entrada, modos de entrada y métodos de división de datos. En la siguiente tabla se describen las opciones:
| Formato de datos | Tipo de entrada | Modo de entrada | Método de división de datos |
|---|---|---|---|
| Lista de archivos | mltable o uri_folder |
ro_mount o download |
Por tamaño (número de archivos) o por partición |
| Datos tabulares | mltable |
direct |
Por tamaño (tamaño físico estimado) o por partición |
Nota:
Si usa mltable tabular como datos de entrada principales, debe hacer lo siguiente:
- Instale la biblioteca
mltableen su entorno, como en la línea 9 de este archivo conda. - Tenga un archivo de especificación MLTable en la ruta de acceso especificada con la sección
transformations: - read_delimited:rellenada. Para obtener ejemplos, consulte Creación y administración de recursos de datos.
Puede declarar los datos de entrada principales con el atributo input_data en el trabajo paralelo YAML o Python, y enlazar los datos con el input definido del trabajo paralelo mediante ${{inputs.<input name>}}. A continuación, defina el atributo de división de datos para la entrada principal en función del método de división de datos.
| Método de división de datos | Nombre del atributo | Tipo de atributo | Ejemplo de trabajo |
|---|---|---|---|
| Por tamaño | mini_batch_size |
string | Predicción por lotes de Iris |
| Por partición | partition_keys |
lista de cadenas | Predicción de las ventas de zumo de naranja |
Configuración de los recursos de proceso para la paralelización
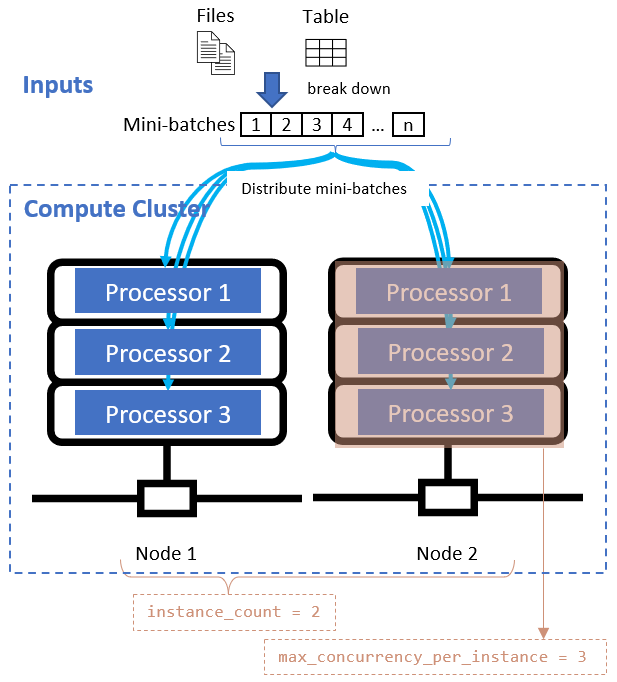
Después de definir el atributo de división de datos, configure los recursos de proceso para la paralelización estableciendo los atributos instance_count y max_concurrency_per_instance.
| Attribute name | Type | Descripción | Valor predeterminado |
|---|---|---|---|
instance_count |
integer | El número de nodos que se usarán para el trabajo. | 1 |
max_concurrency_per_instance |
integer | Número de procesadores en cada nodo. | Para un proceso de GPU: 1. Para un proceso de CPU: número de núcleos. |
Estos atributos funcionan junto con el clúster de proceso especificado, como se muestra en el siguiente diagrama:
Llamada al script de entrada
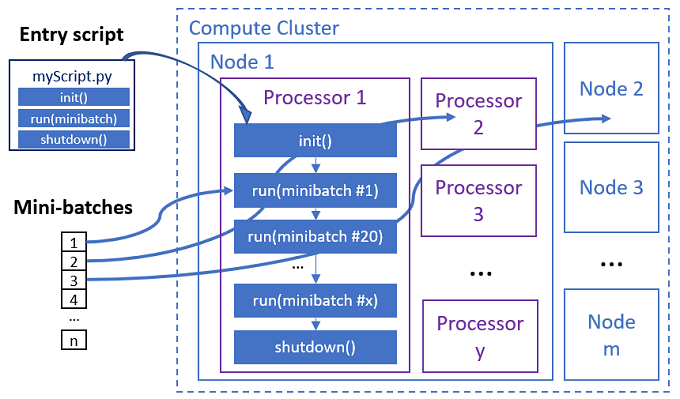
El script de entrada es un único archivo de Python que implementa las tres funciones predefinidas siguientes con código personalizado.
| Nombre de la función | Obligatorio | Description | Entrada | Valor devuelto |
|---|---|---|---|---|
Init() |
Y | Preparación común antes de empezar a ejecutar mini lotes. Por ejemplo, use esta función para cargar el modelo en un objeto global. | -- | -- |
Run(mini_batch) |
Y | Implementa la lógica de ejecución principal para minilotes. | mini_batch es un dataframe de pandas si los datos de entrada son datos tabulares, o una lista de rutas de archivos si los datos de entrada son un directorio. |
Trama de datos, lista o tupla. |
Shutdown() |
N | Función opcional para realizar limpiezas personalizadas antes de devolver el proceso al grupo. | -- | -- |
Importante
Para evitar excepciones al analizar argumentos en funciones de Init() o Run(mini_batch), use parse_known_args en lugar de parse_args. Consulte el ejemplo de iris_score para ver un script de entrada con analizador de argumentos.
Importante
La función Run(mini_batch) requiere una devolución de un elemento dataframe, lista o tupla. El trabajo paralelo usa el recuento de que devuelven para medir los elementos correctos en ese minilote. El número de mini lotes debe ser igual al recuento de listas de devolución si todos los elementos se han procesado.
El trabajo paralelo ejecuta las funciones de cada procesador, como se muestra en el siguiente diagrama.
Consulte los siguientes ejemplos de script de entrada:
- Identificación de imágenes para una lista de archivos de imagen
- Clasificación de iris para datos de iris tabulares
Para llamar al script de entrada, establezca los siguientes dos atributos en la definición del trabajo paralelo:
| Attribute name | Type | Description |
|---|---|---|
code |
string | Ruta de acceso local al directorio de código fuente para cargar y usar para el trabajo. |
entry_script |
string | Archivo de Python que contiene la implementación de funciones paralelas predefinidas. |
Ejemplo de paso de trabajo paralelo
El siguiente paso de trabajo paralelo declara el tipo de entrada, el modo y el método de división de datos, enlaza la entrada, configura el proceso y llama al script de entrada.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Considerar la configuración de automatización
El trabajo paralelo de Azure Machine Learning expone muchas opciones opcionales que pueden controlar automáticamente el trabajo sin intervención manual. En la siguiente tabla se describe esta configuración.
| Clave | Tipo | Descripción | Valores permitidos | Valor predeterminado | Establecer en el atributo o el argumento del programa |
|---|---|---|---|---|---|
mini_batch_error_threshold |
integer | Número de minilotes erróneos que se omitirán en este trabajo paralelo. Si el recuento de minilotes con errores es mayor que este umbral, el trabajo paralelo se marcará como erróneo. El minilote se marcará como erróneo si: - El recuento de devolución de run() es menor que el recuento de entradas del minilote.- Las excepciones se detectan en código personalizado run(). |
[-1, int.max] |
-1, lo que significa omitir todos los minilotes con errores |
Atributo mini_batch_error_threshold |
mini_batch_max_retries |
integer | Número de reintentos cuando se produce un error en el minilote o se agota el tiempo de espera. Si se produce un error en todos los reintentos, el minilote se marcará como erróneo según el cálculo mini_batch_error_threshold. |
[0, int.max] |
2 |
Atributo retry_settings.max_retries |
mini_batch_timeout |
integer | Tiempo de espera en segundos para ejecutar la función personalizada run(). Si el tiempo de ejecución es superior a este umbral, el minilote se interrumpe y se marcará como erróneo para volver a intentarlo. |
(0, 259200] |
60 |
Atributo retry_settings.timeout |
item_error_threshold |
integer | El umbral de elementos con errores. Los elementos con errores se cuentan por la diferencia numérica entre las entradas y las devoluciones de cada minilote. Si la suma de elementos con error es superior a este umbral, el trabajo paralelo se marca como erróneo. | [-1, int.max] |
-1, lo que significa omitir todos los errores durante el trabajo paralelo |
Argumento del programa--error_threshold |
allowed_failed_percent |
integer | De forma similar a mini_batch_error_threshold, pero usa el porcentaje de minilotes con errores en lugar del recuento. |
[0, 100] |
100 |
Argumento del programa--allowed_failed_percent |
overhead_timeout |
integer | Tiempo de espera en segundos para la inicialización de cada minilote. Por ejemplo, cargue los datos de minilote y páselo a la función run(). |
(0, 259200] |
600 |
Argumento del programa--task_overhead_timeout |
progress_update_timeout |
integer | Tiempo de espera en segundos para supervisar el progreso de la ejecución de minilotes. Si no se reciben actualizaciones de progreso dentro de esta configuración de tiempo de espera, el trabajo paralelo se marcará como erróneo. | (0, 259200] |
Calculado dinámicamente por otra configuración | Argumento del programa--progress_update_timeout |
first_task_creation_timeout |
integer | Tiempo de espera en segundos para supervisar el tiempo entre el inicio del trabajo y la ejecución del primer minilote. | (0, 259200] |
600 |
Argumento del programa--first_task_creation_timeout |
logging_level |
string | El nivel de registros a volcar a los archivos de registro de usuario. | INFO, WARNINGo DEBUG |
INFO |
Atributo logging_level |
append_row_to |
string | Agregue todos los resultados de cada ejecución del mini lote y envíelos a este archivo. Puede hacer referencia a una de las salidas del trabajo paralelo mediante la expresión ${{outputs.<output_name>}} |
Atributo task.append_row_to |
||
copy_logs_to_parent |
string | Opción booleana si se va a copiar el progreso del trabajo, la información general y los registros en el trabajo de canalización principal. | True o False |
False |
Argumento del programa--copy_logs_to_parent |
resource_monitor_interval |
integer | Intervalo de tiempo en segundos para volcar el uso de recursos del nodo (por ejemplo cpu o memoria) a la carpeta de registro en la ruta logs/sys/perf. Nota: El volcado frecuente de registros de recursos ralentiza ligeramente la velocidad de ejecución. Establezca este valor en 0 para detener el uso de recursos de volcado. |
[0, int.max] |
600 |
Argumento del programa--resource_monitor_interval |
El siguiente código de ejemplo actualiza esta configuración:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Creación de la canalización con el paso de trabajo paralelo
En el siguiente ejemplo se muestra el trabajo de canalización completo con el paso de trabajo paralelo insertado:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Enviar el trabajo de canalización
Envíe su trabajo de canalización con paso paralelo utilizando el comando de la CLI az ml job create:
az ml job create --file pipeline.yml
Comprobar el paso paralelo en la interfaz de usuario del estudio
Después de enviar un trabajo de canalización, el SDK o el widget de la CLI proporciona un vínculo de dirección URL web al grafo de canalización en la interfaz de usuario de Azure Machine Learning Studio.
Para ver los resultados del trabajo paralelo, haga doble clic en el paso paralelo en el gráfico de canalización, seleccione la pestaña Configuración en el panel de detalles, expanda Configuración de ejecución y luego expanda la sección paralelo.

Para depurar el error del trabajo paralelo, seleccione la pestaña Salidas y registros, expanda la carpeta registros y compruebe job_result.txt para comprender por qué se produjo un error en el trabajo paralelo. Para obtener información sobre la estructura de registro de trabajos paralelos, consulte readme.txt en la misma carpeta.
