Solución de problemas de proceso de Kubernetes
En este artículo, aprenderá a solucionar problemas comunes de carga de trabajo en la Proceso de Kubernetes. Entre los errores comunes se incluyen trabajos de entrenamiento y errores de punto de conexión.
Guía de inferencia
Los errores comunes de punto de conexión de Kubernetes en el proceso de Kubernetes se clasifican en dos ámbitos: ámbito de proceso y ámbito de clúster. Los errores de ámbito de proceso están relacionados con el destino de proceso, por ejemplo, no se encuentra el destino de proceso o no se puede acceder a él. Los errores de ámbito del clúster están relacionados con el clúster de Kubernetes subyacente, como el propio clúster, o no se encuentra el clúster.
Errores de proceso de Kubernetes
A continuación se muestran tipos de error comunes en ámbito de proceso que podría encontrarse al usar el proceso de Kubernetes para crear puntos de conexión en línea e implementaciones en línea para la inferencia del modelo en tiempo real. Puede solucionar problemas siguiendo las secciones vinculadas para obtener instrucciones:
- ERROR: GenericComputeError
- ERROR: ComputeNotFound
- ERROR: ComputeNotAccessible
- ERROR: InvalidComputeInformation
- ERROR: InvalidComputeNoKubernetesConfiguration
ERROR: GenericComputeError
El mensaje de error es el siguiente:
Failed to get compute information.
Este error puede producirse si el sistema no pudo obtener la información de proceso del clúster de Kubernetes. Puede comprobar los siguientes elementos para solucionar el problema:
- Compruebe el estado del clúster de Kubernetes. Si el clúster no se está ejecutando, primero debe iniciar el clúster.
- Compruebe el estado de mantenimiento del clúster de Kubernetes.
- Puede ver el informe de comprobación de estado del clúster para detectar cualquier problema, por ejemplo, si el clúster no es accesible.
- Puede ir al portal del área de trabajo para comprobar el estado del proceso.
- Compruebe si la información sobre los tipos de instancia es correcta. Puede comprobar los tipos de instancia admitidos en la documentación del proceso de Kubernetes.
- Intente desasociar y volver a asociar el proceso al área de trabajo si procede.
Nota:
Para solucionar errores mediante una nueva asociación, asegúrese de que lo hace con la misma configuración que el proceso desasociado anteriormente. Por ejemplo, con el mismo nombre de proceso y el mismo espacio de nombres ya que, de lo contrario, puede encontrar otros errores.
ERROR: ComputeNotFound
El mensaje de error es:
Cannot find Kubernetes compute.
Este error puede producirse cuando:
- El sistema no encuentra el proceso al crear o actualizar un nuevo punto de conexión o implementación en línea.
- Se ha eliminado el proceso de los puntos de conexión o implementaciones en línea existentes.
Puede comprobar los siguientes elementos para solucionar el problema:
- Intente volver a crear el punto de conexión y la implementación.
- Intente desasociar y volver a asociar el proceso al área de trabajo. Preste atención a más notas sobre la nueva asociación.
ERROR: ComputeNotAccessible
El mensaje de error es:
The Kubernetes compute is not accessible.
Este error puede producirse cuando la MSI (identidad administrada) del área de trabajo no tiene acceso al clúster de AKS. Puede comprobar si la MSI del área de trabajo tiene acceso a AKS y, si no es así, puede consultar este documento para administrar el acceso y la identidad.
ERROR: InvalidComputeInformation
El mensaje de error es:
The compute information is invalid.
Hay un proceso de validación de un destino de proceso al implementar modelos en el clúster de Kubernetes. Este error se producirá si la información de proceso no es válida. Por ejemplo, no se encuentra el destino de proceso o la configuración de la extensión de Azure Machine Learning se ha actualizado en el clúster de Kubernetes.
Puede comprobar los siguientes elementos para solucionar el problema:
- Compruebe si el destino de proceso que usó es correcto y existe en el área de trabajo.
- Intente desasociar y volver a asociar el proceso al área de trabajo. Preste atención a más notas sobre la nueva asociación.
ERROR: InvalidComputeNoKubernetesConfiguration
El mensaje de error es:
The compute kubeconfig is invalid.
Este error se producirá si el sistema no puede encontrar ninguna configuración para conectarse al clúster, como:
- En el caso del clúster de Kubernetes para Arc, no se puede encontrar ninguna configuración de Azure Relay.
- En el caso del clúster de AKS, no se puede encontrar ninguna configuración de AKS.
Para volver a generar la configuración de la conexión de proceso en el clúster, puede intentar desasociar y volver a asociar el proceso al área de trabajo. Preste atención a más notas sobre la nueva asociación.
Error de clúster de Kubernetes
A continuación se muestra una lista de tipos de error en el ámbito de clúster que se pueden encontrar al usar el proceso de Kubernetes para crear puntos de conexión en línea e implementaciones en línea para la inferencia de modelos en tiempo real. Puede solucionar los problemas de estas dos operaciones con las siguientes instrucciones:
- ERROR: GenericClusterError
- ERROR: ClusterNotReachable
- ERROR: ClusterNotFound
- ERROR: ClusterServiceNotFound
- ERROR: ClusterUnauthorized
ERROR: GenericClusterError
El mensaje de error es:
Failed to connect to Kubernetes cluster: <message>
Este error puede producirse si el sistema no pudo conectarse al clúster de Kubernetes por un motivo desconocido. Puede comprobar los siguientes elementos para solucionar el problema:
Para clústeres de AKS:
- Compruebe si el clúster de AKS está apagado.
- Si el clúster no se está ejecutando, primero debe iniciar el clúster.
- Compruebe si el clúster de AKS ha habilitado la red seleccionada mediante intervalos IP autorizados.
- Si el clúster de AKS tiene habilitados los intervalos IP autorizados, asegúrese de que se hayan habilitado todos los intervalos IP del plano de control de Azure Machine Learning para el clúster de AKS. Para más información, consulte esta documentación.
En el caso de un clúster de AKS o de Kubernetes habilitado para Azure Arc:
- Compruebe si el servidor de la API de Kubernetes es accesible mediante la ejecución del comando
kubectlen el clúster.
ERROR: ClusterNotReachable
El mensaje de error es:
The Kubernetes cluster is not reachable.
Este error puede producirse si el sistema no puede conectarse a un clúster. Puede comprobar los siguientes elementos para solucionar el problema:
Para clústeres de AKS:
- Compruebe si el clúster de AKS está apagado.
- Si el clúster no se está ejecutando, primero debe iniciar el clúster.
En el caso de un clúster de AKS o de Kubernetes habilitado para Azure Arc:
- Compruebe si el servidor de la API de Kubernetes es accesible mediante la ejecución del comando
kubectlen el clúster.
ERROR: ClusterNotFound
El mensaje de error es:
Cannot found Kubernetes cluster.
Este error se puede producir si el sistema no encuentra el clúster de AKS o de Kubernetes para Arc.
Puede comprobar los siguientes elementos para solucionar el problema:
- En primer lugar, compruebe el identificador de recurso del clúster en Azure Portal para comprobar si el recurso de clúster de Kubernetes existe todavía y se ejecuta con normalidad.
- Si el clúster existe y se está ejecutando, puede intentar desasociar y volver a asociar el proceso al área de trabajo. Preste atención a más notas sobre la nueva asociación.
ERROR: ClusterServiceNotFound
El mensaje de error es:
AzureML extension service not found in cluster.
Este error debe producirse cuando el servicio de entrada propiedad de la extensión no tiene suficientes pods back-end.
Puede:
- Acceda al clúster y compruebe el estado del servicio
azureml-ingress-nginx-controllery su pod de back-end en el espacio de nombresazureml. - Si el clúster no tiene pods back-end en ejecución, compruebe el motivo mediante la descripción del pod. Por ejemplo, si el pod no tiene suficientes recursos para ejecutarse, puede eliminar algunos pods para liberar suficientes recursos para el pod de entrada.
ERROR: ClusterUnauthorized
El mensaje de error es:
Request to Kubernetes cluster unauthorized.
Este error solo debe producirse en el clúster habilitado para TA, lo que significa que el token de acceso expiró durante la implementación.
Puede intentarlo de nuevo después de varios minutos.
Sugerencia
Para obtener más soluciones a problemas comunes al crear o actualizar puntos de conexión e implementaciones en línea de Kubernetes, consulte Solución de problemas de puntos de conexión en línea.
Error de identidad
ERROR: RefreshExtensionIdentityNotSet
Este error se produce cuando la extensión está instalada pero la identidad de la extensión no está correctamente asignada. Puede intentar volver a instalar la extensión para corregirlo.
Observe que este error solo es para clústeres administrados
¿Cómo comprobar si sslCertPemFile y sslKeyPemFile son correctos?
Para permitir que se muestren errores conocidos, puede usar los comandos para ejecutar una comprobación de línea de base para el certificado y la clave. Espere que el segundo comando devuelva "Clave RSA ok" sin solicitar la contraseña.
openssl x509 -in cert.pem -noout -text
openssl rsa -in key.pem -noout -check
Ejecute los comandos para comprobar si sslCertPemFile y sslKeyPemFile se corresponden:
openssl x509 -in cert.pem -noout -modulus | md5sum
openssl rsa -in key.pem -noout -modulus | md5sum
Para sslCertPemFile, es el certificado público. Debe incluir la cadena de certificados que incluye los siguientes certificados y debe estar en la secuencia del certificado de servidor, el certificado de entidad de certificación intermedia y el certificado de entidad de certificación raíz:
- El certificado de servidor: el servidor se presenta al cliente durante el protocolo de enlace TLS. Contiene la clave pública del servidor, el nombre de dominio y otra información. El certificado de servidor está firmado por una entidad de certificación (CA) intermedia que garantiza la identidad del servidor.
- El certificado de entidad de certificación intermedia: la entidad de certificación intermedia se presenta al cliente para demostrar su autoridad para firmar el certificado de servidor. Contiene la clave pública, el nombre y otra información de la entidad de certificación intermedia. El certificado de entidad de certificación intermedia está firmado por una entidad de certificación raíz que garantiza la identidad de la entidad de certificación intermedia.
- El certificado de entidad de certificación raíz: la entidad de certificación raíz se presenta al cliente para demostrar su autoridad para firmar el certificado de entidad de certificación intermedia. Contiene la clave pública, el nombre y otra información de la entidad de certificación raíz. El certificado de la entidad de certificación raíz está autofirmado y aprobado por el cliente.
Guía de aprendizaje
Cuando se ejecuta el trabajo de entrenamiento, puede comprobar el estado del trabajo en el portal del área de trabajo. Cuando encuentra algún estado de trabajo anómalo, como cuando el trabajo se ha reintentado varias veces, o cuando el trabajo se ha bloqueado en el estado de inicialización, o incluso cuando el trabajo ha fallado finalmente, puede seguir la guía para solucionar el problema.
Depuración de reintento de trabajo
Si el pod del trabajo de entrenamiento que se ejecuta en el clúster se finalizó debido a que el nodo en el que se ejecuta está OOM (memoria insuficiente), el trabajo se reintenta automáticamente en otro nodo disponible.
Para depurar mejor la causa principal del intento de trabajo, puede ir al portal del área de trabajo para consultar el registro de reintentos de trabajo.
- Cada registro de reintento se registra en una nueva carpeta de registro con el formato de "reintento-<número de reintentos>" (por ejemplo, reintento-001).
Así, puede obtener la información de asignación del nodo del trabajo de reintento, para averiguar en qué nodo se ha estado ejecutando el trabajo de reintento.
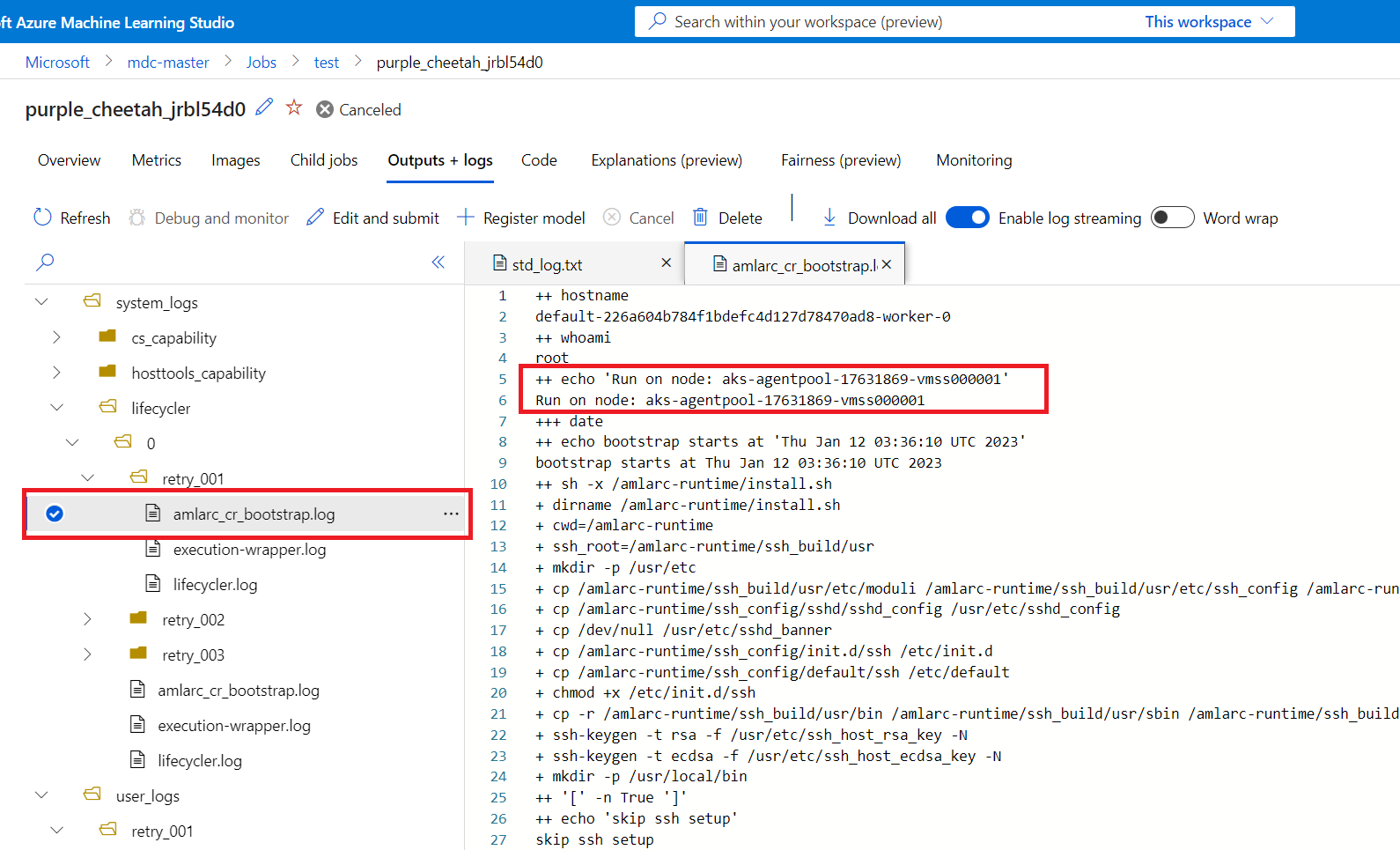
Puede obtener información sobre la asignación de nodos de trabajo en el archivo amlarc_cr_bootstrap.log que se encuentra en la carpeta system_logs.
El nombre de host del nodo en el que se ejecuta el pod de trabajo se indica en este registro, por ejemplo:
++ echo 'Run on node: ask-agentpool-17631869-vmss0000"
"ask-agentpool-17631869-vmss0000" representa el nombre de host del nodo que ejecuta este trabajo en el clúster de AKS. De esta forma, puede acceder al clúster para comprobar el estado del nodo y realizar una investigación más detallada.
El pod de trabajo se bloquea en el estado de inicialización
Si el trabajo tarda en ejecutarse más de lo esperado y si detecta que los pods del trabajo se bloquean en un estado de inicialización con la advertencia Unable to attach or mount volumes: *** failed to get plugin from volumeSpec for volume ***-blobfuse-*** err=no volume plugin matched, es posible que el problema se produzca porque la extensión de Azure Machine Learning no admite el modo de descarga para los datos de entrada.
Para resolver este problema, cambie al modo de montaje de los datos de entrada.
Errores comunes de trabajo
A continuación se encuentra una enumeración de tipos de errores comunes que puede encontrarse al usar el proceso de Kubernetes para crear y ejecutar un trabajo de entrenamiento, que puede solucionar siguiendo la guía:
- Error del trabajo. 137
- Error del trabajo. E45004
- Error del trabajo. 400
- Asigne una clave de cuenta o un token de SAS.
- Error de autorización de AzureBlob
Error del trabajo. 137
El mensaje de error es:
Azure Machine Learning Kubernetes job failed. 137:PodPattern matched: {"containers":[{"name":"training-identity-sidecar","message":"Updating certificates in /etc/ssl/certs...\n1 added, 0 removed; done.\nRunning hooks in /etc/ca-certificates/update.d...\ndone.\n * Serving Flask app 'msi-endpoint-server' (lazy loading)\n * Environment: production\n WARNING: This is a development server. Do not use it in a production deployment.\n Use a production WSGI server instead.\n * Debug mode: off\n * Running on http://127.0.0.1:12342/ (Press CTRL+C to quit)\n","code":137}]}
Compruebe la configuración del proxy y compruebe si 127.0.0.1 se agregó a proxy-skip-range al usar az connectedk8s connect con esta configuración de red.
Error del trabajo. E45004
El mensaje de error es:
Azure Machine Learning Kubernetes job failed. E45004:"Training feature is not enabled, please enable it when install the extension."
Compruebe si ha establecido enableTraining=True al realizar la instalación de la extensión de Azure Machine Learning. Puede encontrar más detalles en Implementación de la extensión de Azure Machine Learning en AKS o en el clúster de Kubernetes habilitado para Arc.
Error del trabajo. 400
El mensaje de error es:
Azure Machine Learning Kubernetes job failed. 400:{"Msg":"Encountered an error when attempting to connect to the Azure Machine Learning token service","Code":400}
Puede consultar la sección de solución de problemas de Private Link para comprobar la configuración de red.
Asigne una clave de cuenta o un token de SAS.
Si necesita acceder a Azure Container Registry (ACR) para la imagen de Docker y para acceder a la cuenta de almacenamiento para los datos de entrenamiento, este problema se producirá si no se especifica el proceso con una identidad administrada.
Para acceder a Azure Container Registry (ACR) desde un clúster de proceso de Kubernetes para imágenes de Docker o acceder a una cuenta de almacenamiento para los datos de entrenamiento, debe adjuntar el proceso de Kubernetes con una identidad administrada asignada por el sistema o asignada por el usuario habilitada.
En el escenario de entrenamiento anterior, esta identidad de proceso es necesaria para que el proceso de Kubernetes se use como credencial para comunicarse entre el recurso arm enlazado al área de trabajo y el clúster informático de Kubernetes. Por lo tanto, sin esta identidad, se produce un error en el trabajo de entrenamiento y se notifica que falta la clave de cuenta o el token sas. Tome el acceso a la cuenta de almacenamiento, por ejemplo, si no especifica una identidad administrada para el proceso de Kubernetes, se produce un error en el trabajo con el siguiente mensaje de error:
Unable to mount data store workspaceblobstore. Give either an account key or SAS token
Esto se debe a que la cuenta de almacenamiento predeterminada del área de trabajo de aprendizaje automático sin credenciales no es accesible en los trabajos de entrenamiento en el proceso de Kubernetes.
Para mitigar este problema, puede asignar la identidad administrada al proceso en el paso de asociación de proceso, o bien puede hacerlo después de asociarla. Puede encontrar más detalles en Asignación de una identidad administrada al destino de proceso.
Error de autorización de AzureBlob
Si necesita acceder a AzureBlob para cargar o descargar datos en los trabajos de entrenamiento en el proceso de Kubernetes y se produce un error en el trabajo con el siguiente mensaje de error:
Unable to upload project files to working directory in AzureBlob because the authorization failed.
Esto se debe a que se produjo un error en la autorización cuando el trabajo intenta cargar los archivos del proyecto en AzureBlob. Puede comprobar los siguientes elementos para solucionar el problema:
- Asegúrese de que la cuenta de almacenamiento ha habilitado las excepciones de "Permitir que los servicios de Azure en la lista de servicios de confianza accedan a esta cuenta de almacenamiento" y de que el área de trabajo esté en la lista de instancias de recursos.
- Asegúrese de que el área de trabajo tiene una identidad administrada asignada por el sistema.
Problema de Private Link
Podríamos usar el método para comprobar la configuración de Private Link iniciando sesión en un pod en el clúster de Kubernetes y, a continuación, comprobando la configuración de red relacionada.
Busque el identificador del área de trabajo en Azure Portal u obtenga este identificador mediante la ejecución de
az ml workspace showen la línea de comandos.Muestre todos los pods de azureml-fe ejecutados por
kubectl get po -n azureml -l azuremlappname=azureml-fe.Inicie sesión en cualquiera de ellos ejecute
kubectl exec -it -n azureml {scorin_fe_pod_name} bash.Si el clúster no usa el proxy, ejecute
nslookup {workspace_id}.workspace.{region}.api.azureml.ms. Si configura un vínculo privado desde la red virtual al área de trabajo correctamente, la dirección IP interna de la red virtual debe responderse a través de la herramienta DNSLookup.Si el clúster usa proxy, puede intentar
curlel área de trabajo.
curl https://{workspace_id}.workspace.westcentralus.api.azureml.ms/metric/v2.0/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/api/2.0/prometheus/post -X POST -x {proxy_address} -d {} -v -k
Cuando el proxy y el área de trabajo se configuran correctamente con un vínculo privado, debe observar un intento de conectarse a una dirección IP interna. Se espera una respuesta con un código de estado HTTP 401 en este escenario si no se proporciona un token.
Otros problemas conocidos
La actualización de proceso de Kubernetes no surte efecto
En este momento, la CLI v2 y el SDK v2 no permiten actualizar ninguna configuración de un proceso de Kubernetes existente. Por ejemplo, cambiar el espacio de nombres no surte efecto.
El nombre del área de trabajo o del grupo de recursos termina con "-"
Una causa común del error "InternalServerError" al crear cargas de trabajo como implementaciones, puntos de conexión o trabajos en un equipo Kubernetes, es tener los caracteres especiales como "-" al final del área de trabajo o nombre de grupo de recursos.