Desencadenamiento de canalizaciones de Machine Learning
SE APLICA A:  Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
En este artículo, aprenderá a programar mediante programación una canalización para que se ejecute en Azure. Puede crear una programación basada en el tiempo transcurrido o en los cambios en el sistema de archivos. Las programaciones basadas en el tiempo se pueden usar para encargarse de tareas rutinarias, como la supervisión del desfase de datos. Las programaciones basadas en los cambios se pueden usar para reaccionar ante cambios irregulares o imprevisibles, como la carga de nuevos datos o la edición de datos antiguos. Después de aprender a crear programaciones, aprenderá a recuperarlas y desactivarlas. Por último, aprenderá a usar otros servicios de Azure, Azure Logic Apps y Azure Data Factory, para ejecutar canalizaciones. Una instancia de Azure Logic Apps permite una lógica o comportamiento de desencadenamiento más complejos. Las canalizaciones de Azure Data Factory permiten llamar a una canalización de Machine Learning como parte de una canalización de orquestación de datos más grande.
Prerrequisitos
Suscripción a Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita.
Entorno de Python en el que está instalado el SDK de Azure Machine Learning para Python. Para más información, consulte Creación y administración de entornos reutilizables para aprendizaje e implementación con Azure Machine Learning.
Un área de trabajo Machine Learning con una canalización publicada. Puede usar la creada en Creación y ejecución de canalizaciones de Machine Learning con el SDK de Azure Machine Learning.
Desencadenamiento de canalizaciones con el SDK de Azure Machine Learning para Python
Para programar una canalización, necesitará una referencia al área de trabajo, el identificador de la canalización publicada y el nombre del experimento en el que quiere crear la programación. Puede obtener estos valores con el código siguiente:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Crear una programación
Para ejecutar una canalización de forma periódica, creará una programación. Un elemento Schedule asocia una canalización, un experimento y un desencadenador. El desencadenador puede ser un elemento ScheduleRecurrence que describa la espera entre trabajos o una ruta de acceso a un almacén de datos que especifique un directorio para inspeccionar los cambios. En cualquier caso, necesitará el identificador de la canalización y el nombre del experimento en el que se va a crear la programación.
En la parte superior del archivo de Python, importe las clases Schedule y ScheduleRecurrence:
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Creación de una programación basada en el tiempo
El constructor ScheduleRecurrence tiene un argumento frequency necesario que debe ser una de las cadenas siguientes: "Minute", "Hour", "Day" "Week" o "Month". También requiere un argumento interval de entero que especifique el número de unidades de frequency que debe transcurrir entre inicios de programación. Los argumentos opcionales le permiten ser más específico sobre las horas de inicio, como se detalla en los documentos del SDK de ScheduleRecurrence.
Cree un elemento Schedule que inicie un trabajo cada 15 minutos:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Creación de una programación basada en los cambios
Las canalizaciones que se desencadenan por cambios en los archivos pueden ser más eficaces que las basadas en el tiempo. Si quiere hacer algo antes de cambiar un archivo, o cuando se agrega un nuevo archivo a un directorio de datos, puede preprocesar ese archivo. Puede supervisar los cambios en un almacén de datos o aquellos que tienen lugar dentro de un directorio específico del almacén de datos. Si supervisa un directorio específico, los cambios en los subdirectorios de ese directorio no desencadenarán un trabajo.
Nota:
Las programaciones basadas en cambios solo admiten la supervisión de Azure Blob Storage.
Para crear un elemento Schedule reactivo a los archivos, debe establecer el parámetro datastore en la llamada a Schedule.create. Para supervisar una carpeta, establezca el argumento path_on_datastore.
El argumento polling_interval permite expresar (en minutos) la frecuencia con la que se comprueba si hay cambios en el almacén de datos.
Si la canalización se construyó con DataPath PipelineParameter, puede establecer esa variable en el nombre del archivo cambiado mediante el argumento data_path_parameter_name.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Argumentos opcionales al crear una programación
Además de los argumentos descritos anteriormente, puede establecer el argumento status en "Disabled" para crear una programación inactiva. Por último, continue_on_step_failure permite pasar un valor booleano que invalidará el comportamiento de error predeterminado de la canalización.
Visualización de las canalizaciones programadas
En el explorador web, vaya a Azure Machine Learning. En la sección Endpoints (Puntos de conexión) del panel de navegación, elija Pipeline endpoints (Puntos de conexión de la canalización). Esto le llevará a una lista de las canalizaciones publicadas en el área de trabajo.
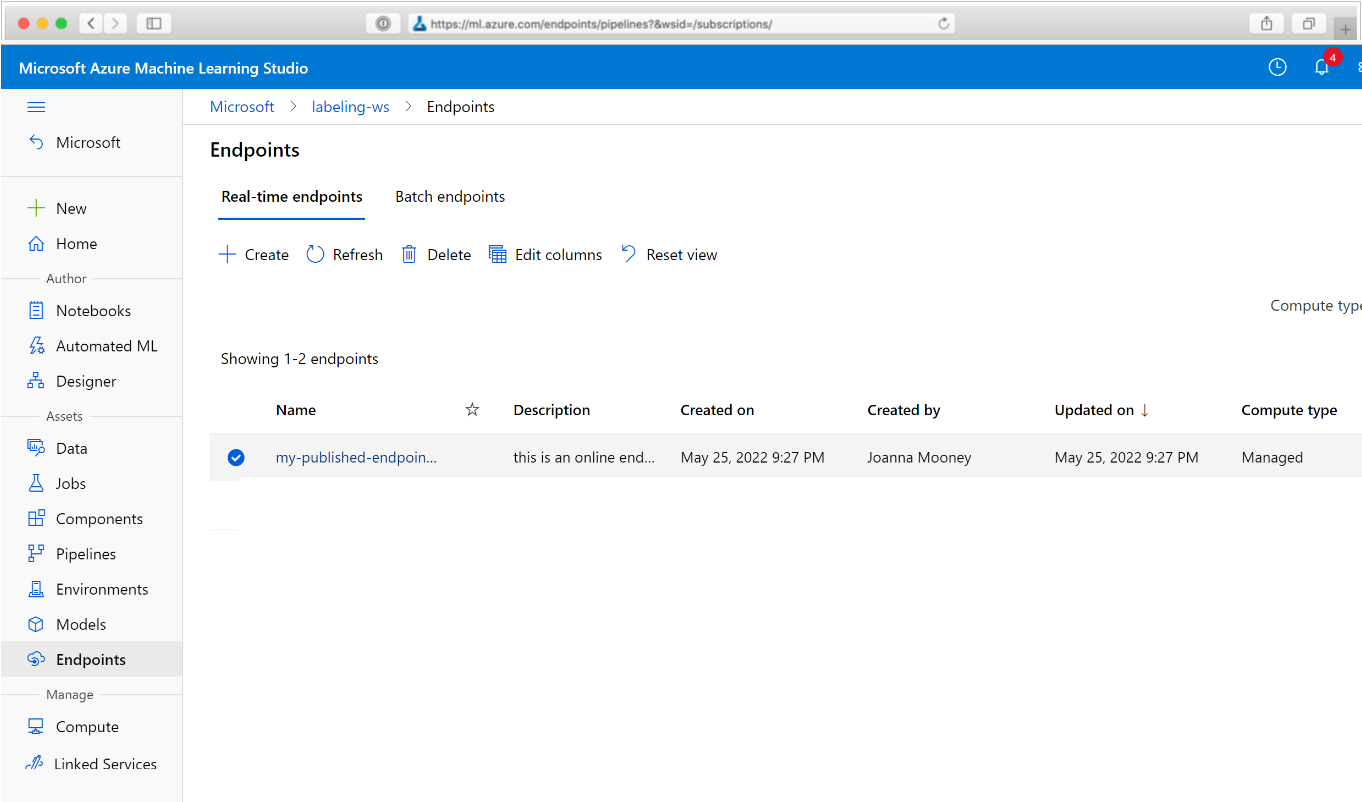
En esta página puede ver información de resumen sobre todas las canalizaciones del área de trabajo: nombres, descripciones, estado, etc. Profundice haciendo clic en la canalización. En la página resultante, hay más detalles sobre la canalización y puede profundizar en cada uno de los trabajos.
Desactivación de la canalización
Si tiene un elemento Pipeline publicado pero no programado, puede deshabilitarlo con:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Si la canalización está programada, primero debe cancelar la programación. Recupere el identificador de la programación del portal o mediante la ejecución de:
ss = Schedule.list(ws)
for s in ss:
print(s)
Una vez que tenga el elemento schedule_id que quiere deshabilitar, ejecute:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Si vuelve a ejecutar Schedule.list(ws), obtendrá una lista vacía.
Uso de Azure Logic Apps para desencadenadores complejos
Se pueden crear reglas o comportamientos de desencadenadores más complejos mediante una instancia de Azure Logic Apps.
Para usar una instancia de Azure Logic Apps para desencadenar una canalización Machine Learning, necesitará el punto de conexión de REST para una canalización de Machine Learning publicada. Cree y publique la canalización. Luego, busque el punto de conexión de REST de PublishedPipeline mediante el identificador de canalización:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Crear una aplicación lógica en Azure
Ahora cree una instancia de aplicación lógica de Azure. Una vez aprovisionada la aplicación lógica, siga estos pasos para configurar un desencadenador para la canalización:
Cree una identidad administrada asignada por el sistema para conceder a la aplicación acceso al área de trabajo de Azure Machine Learning.
Vaya a la vista del Diseñador de aplicación lógica y seleccione la plantilla de aplicación lógica vacía.
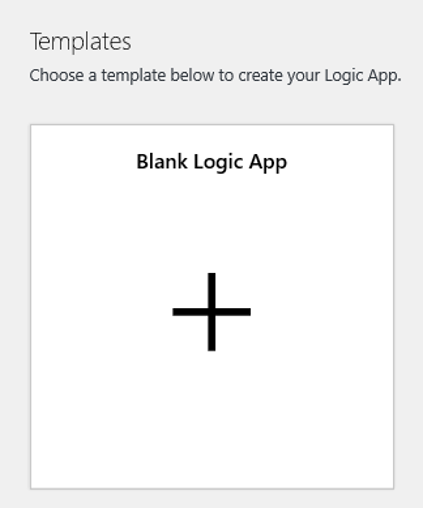
En el Diseñador, busque blob. Seleccione el desencadenador When a blob is added or modified (properties only) (Cuando se agrega o modifica un blob [solo propiedades]) y agregue este desencadenador a la aplicación lógica.
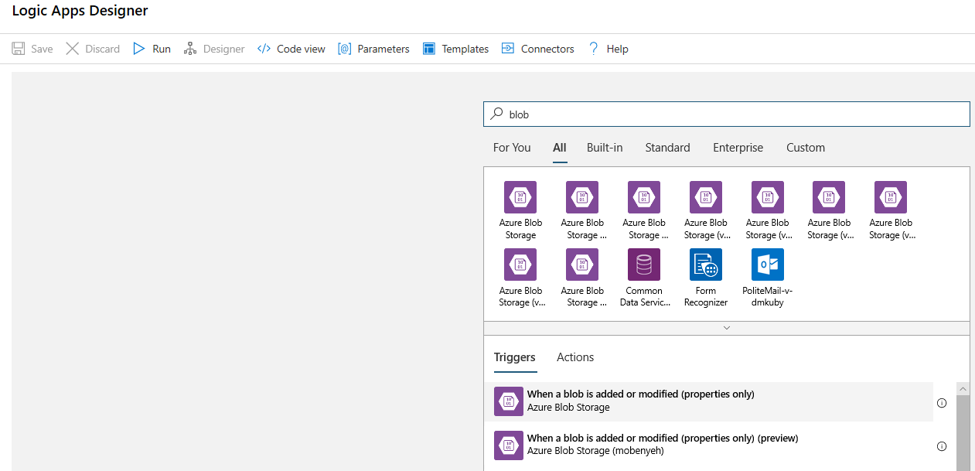
Rellene la información de conexión de la cuenta de almacenamiento de blobs que quiere supervisar para agregar o modificar blobs. Seleccione el contenedor que se va a supervisar.
Elija los valores de Intervalo y Frecuencia para buscar actualizaciones que funcionen en su caso.
Nota
Este desencadenador supervisará el contenedor seleccionado, pero no supervisará las subcarpetas.
Agregue una acción HTTP que se ejecutará cuando se detecte un blob nuevo o modificado. Seleccione + Nuevo paso y busque y seleccione la acción HTTP.
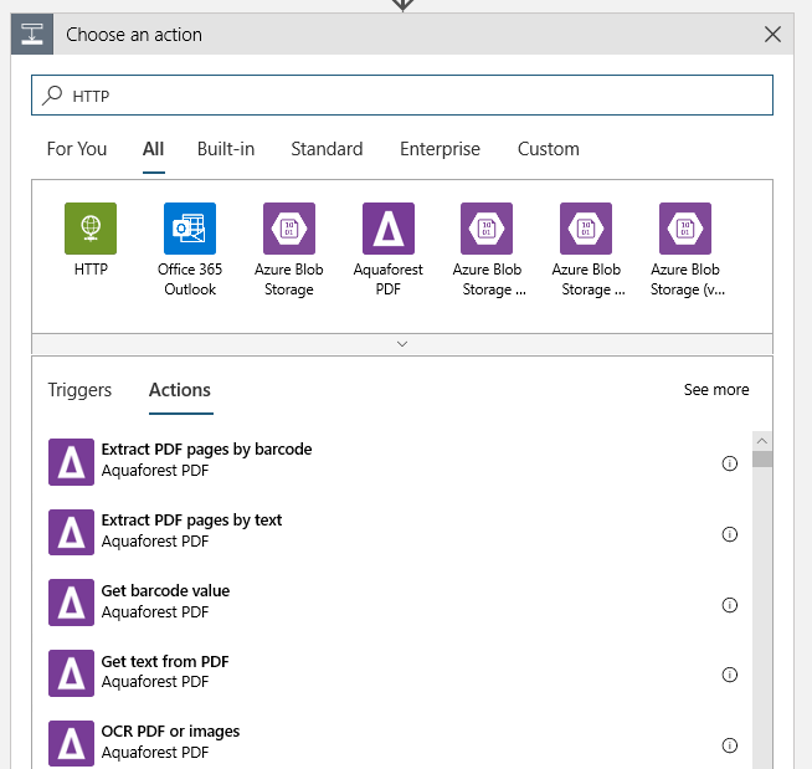
Para configurar la acción, use los siguientes valores:
| Configuración | Value |
|---|---|
| Acción HTTP | POST |
| URI | el punto de conexión a la canalización publicada que encontró como requisito previo. |
| Modo de autenticación | Identidad administrada |
Configure la programación para establecer el valor de cualquier elemento DataPath PipelineParameters que pueda tener:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Use el elemento
DataStoreNameque agregó al área de trabajo como requisito previo.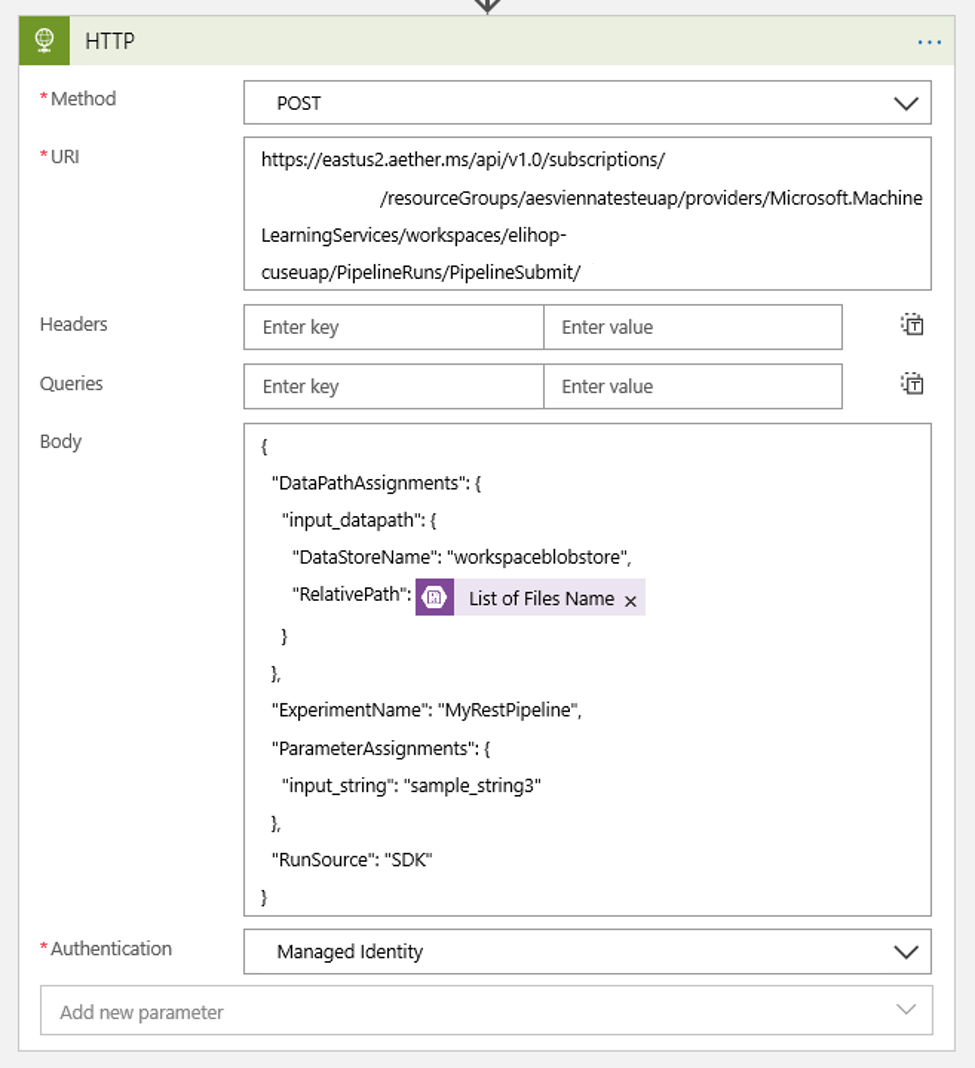
Seleccione Guardar y la programación ya estará lista.
Importante
Si utiliza el control basado en roles de Azure (Azure RBAC) para administrar el acceso a la canalización, establezca los permisos del escenario de canalización (entrenamiento o puntuación).
Llamada a canalizaciones de Machine Learning desde canalizaciones de Azure Data Factory
En una canalización de Azure Data Factory, la actividad Machine Learning Execute Pipeline (Canalización de ejecución de Machine Learning) ejecuta una canalización de Azure Machine Learning. Puede encontrar esta actividad en la página de creación de la instancia de Data Factory en la categoría Machine Learning:
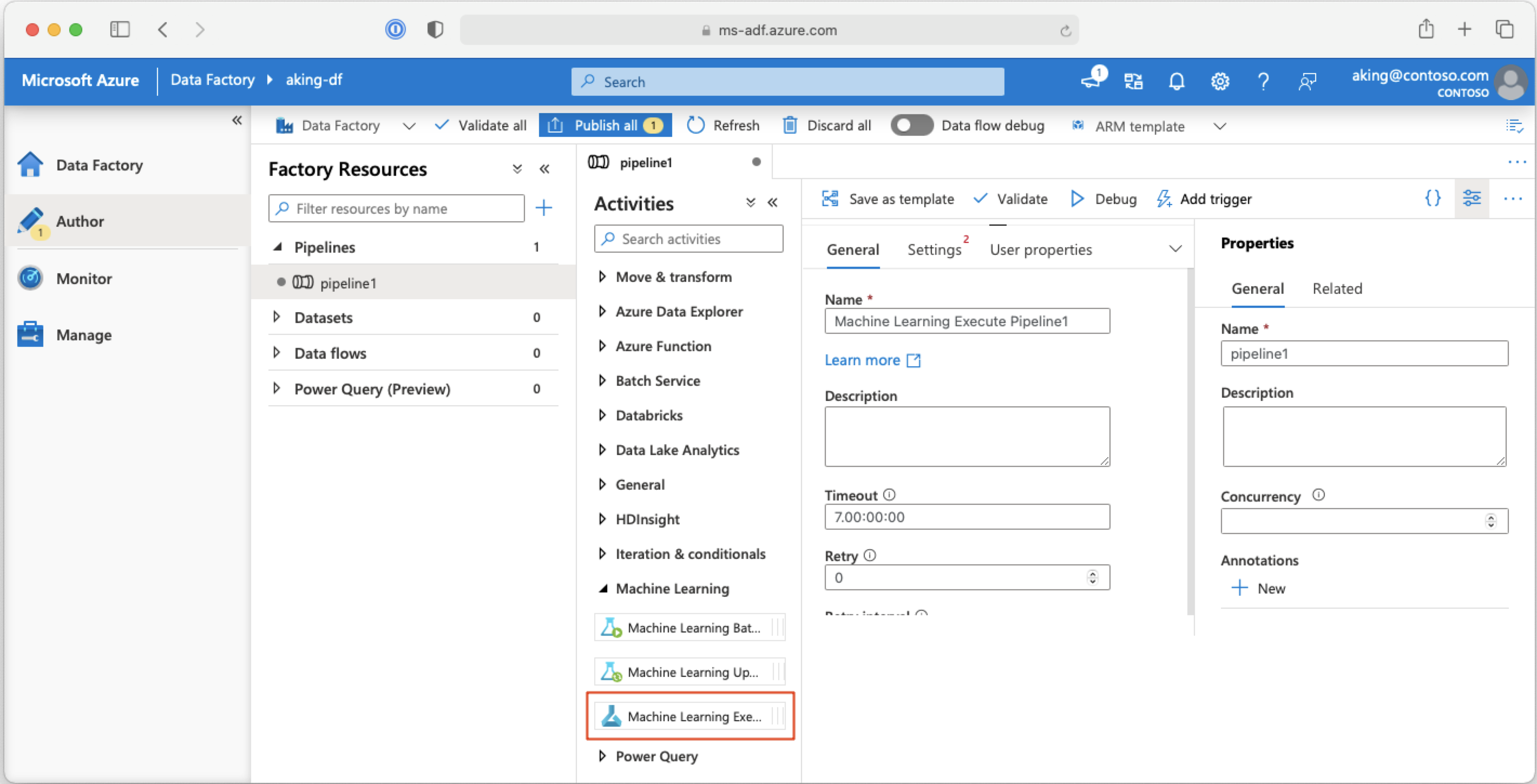
Pasos siguientes
En este artículo, ha usado el SDK de Azure Machine Learning para Python para programar una canalización de dos maneras diferentes. Una programación se repite en función de la hora de reloj transcurrida. La otra programación determina si se modifica un archivo en un elemento Datastore especificado o en un directorio de ese almacén. Ha visto cómo usar el portal para examinar la canalización y los trabajos individuales. Ha aprendido a deshabilitar una programación para que la canalización deje de ejecutarse. Por último, ha creado una instancia de Azure Logic Apps para desencadenar una canalización.
Para más información, consulte:
- Más información sobre las canalizaciones
- Más información sobre la exploración de Azure Machine Learning con Jupyter