Consulta y comparación de experimentos y ejecuciones con MLflow
Los experimentos y trabajos (o ejecuciones) en Azure Machine Learning se pueden consultar utilizando MLflow. No es necesario instalar ningún SDK específico para administrar lo que sucede dentro de un trabajo de entrenamiento, gracias a lo cual se genera una transición más fluida entre ejecuciones locales y la nube por la eliminación de las dependencias específicas de la nube. En este artículo, aprenderá a consultar y comparar experimentos y ejecuciones en el área de trabajo mediante Azure Machine Learning y el SDK de MLflow en Python.
MLflow le permite:
- Crear, consultar, eliminar y buscar experimentos en un área de trabajo.
- Consultar, eliminar y buscar ejecuciones en un área de trabajo.
- Realizar el seguimiento y recuperar métricas, parámetros, artefactos y modelos a partir de ejecuciones.
Para obtener una comparación detallada entre MLflow de código abierto y MLflow al conectarse a Azure Machine Learning, consulte Matriz de compatibilidad para consultar ejecuciones y experimentos en Azure Machine Learning.
Nota:
El SDK v2 de Python para Azure Machine Learning no proporciona funcionalidades nativas de registro o seguimiento. Esto no solo se aplica al registro, sino también para la consulta de las métricas registradas. En su lugar, use MLflow para administrar experimentos y ejecuciones. En este artículo se explica cómo usar MLflow para administrar experimentos y ejecuciones en Azure Machine Learning.
También es posible consultar y buscar experimentos y ejecuciones mediante la API de REST de MLflow. Consulte Uso de MLflow REST con Azure Machine Learning para ver un ejemplo sobre cómo consumirlo.
Requisitos previos
Instale el paquete
mlflowdel SDK de MLflow y el complementoazureml-mlflowde Azure Machine Learning para MLflow de la siguiente manera:pip install mlflow azureml-mlflowSugerencia
Puede usar el paquete de
mlflow-skinny, que es un paquete MLflow ligero sin dependencias de ciencia de datos, interfaz de usuario, servidor o almacenamiento de SQL. Este paquete se recomienda para los usuarios que necesitan principalmente las funcionalidades de seguimiento y registro de MLflow sin importar el conjunto completo de características, incluidas las implementaciones.Cree un área de trabajo de Azure Machine Learning. Para crear un área de trabajo, consulte Crear recursos que necesita para empezar. Revise los permisos de acceso que necesita para realizar las operaciones de MLflow en el área de trabajo.
Para realizar el seguimiento remoto o realizar un seguimiento de experimentos que se ejecutan fuera de Azure Machine Learning, configure MLflow para que apunte al URI de seguimiento del área de trabajo de Azure Machine Learning. Para más información sobre cómo conectar MLflow al área de trabajo, consulte Configuración de MLflow para Azure Machine Learning.
Consulta y búsqueda de experimentos
Use MLflow para buscar experimentos dentro del área de trabajo. Consulte los siguientes ejemplos:
Obtener todos los experimentos activos:
mlflow.search_experiments()Nota:
En las versiones heredadas de MLflow (<2.0), use el método
mlflow.list_experiments()en su lugar.Obtenga todos los experimentos, incluidos los archivados:
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)Obtenga un experimento específico por nombre:
mlflow.get_experiment_by_name(experiment_name)Obtenga un experimento específico por Id.:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
Experimentos de búsqueda
El método search_experiments(), disponible desde Mlflow 2.0, permite buscar experimentos que coincidan con criterios mediante filter_string.
Recupere varios experimentos en función de sus Id.:
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )Recupere todos los experimentos creados después de un tiempo determinado:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")Recupere todos los experimentos con una etiqueta determinada:
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
Ejecución de consultas y búsquedas
MLflow permite realizar búsquedas de ejecuciones dentro de cualquier experimento o, incluso, de varios al mismo tiempo. El método mlflow.search_runs() acepta los argumentos experiment_ids y experiment_name para indicar en qué experimentos se desea buscar. También puede indicar search_all_experiments=True si desea buscar en todos los experimentos del área de trabajo:
Por nombre del experimento:
mlflow.search_runs(experiment_names=[ "my_experiment" ])Por id. de experimento:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])Busque en todos los experimentos del área de trabajo:
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
Tenga en cuenta que experiment_ids permite proporcionar una matriz de experimentos, por lo que podrá buscar ejecuciones en varios experimentos si fuera necesario. Esto podría resultar útil en caso de que quiera comparar ejecuciones del mismo modelo cuando se registra en diferentes experimentos (por ejemplo: por personas diferentes o iteraciones de proyectos diferentes).
Importante
Si experiment_ids, experiment_names o search_all_experiments no se especificasen, MLflow buscará de forma predeterminada en el experimento activo actual. Establezca el experimento activo mediante mlflow.set_experiment().
De manera predeterminada, MLflow devuelve los datos en formato Pandas Dataframe, lo que resulta útil cuando se procesa más a fondo el análisis de las ejecuciones. Los datos devueltos incluyen columnas con:
- Información básica sobre la ejecución.
- Parámetros con el nombre de columna
params.<parameter-name>. - Métricas (último valor registrado de cada una) con el nombre de columna
metrics.<metric-name>.
Todas las métricas y parámetros también se devuelven al realizar consultas. Sin embargo, para las métricas que contengan varios valores (por ejemplo, una curva de pérdida o una curva de PR), solo se devolverá el último valor de la métrica. Si quiere recuperar todos los valores de una métrica determinada, use el método mlflow.get_metric_history. Consulte Obtención de parámetros y métricas de una ejecución para ver un ejemplo.
Ejecuciones de pedidos
De manera predeterminada, los experimentos se ordenan de forma descendente por start_time, que es el momento en el que el experimento se encontraba en la cola en Azure Machine Learning. Sin embargo, puede cambiar este valor predeterminado mediante el parámetro order_by.
El orden se lleva a cabo por atributos, como
start_time:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])Ordene ejecuciones y limite los resultados. En el ejemplo siguiente se devuelve la última ejecución única del experimento:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])La orden se ejecuta mediante el atributo
duration:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])Sugerencia
attributes.durationno está presente en el software de código abierto de MLflow, pero se proporciona en Azure Machine Learning para mayor comodidad.El orden se ejecuta por los valores de la métrica:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)Advertencia
Actualmente, no se admite el uso de
order_bycon expresiones que contenganmetrics.*,params.*otags.*en el parámetroorder_by. En su lugar, use el métodosort_valuesde Pandas, tal y como se muestra en el ejemplo.
Filtrado de ejecuciones
También puede buscar una ejecución con una combinación específica en los hiperparámetros mediante el parámetro filter_string. Se utiliza params para acceder a los parámetros de la ejecución, metrics para acceder a las métricas registradas en la ejecución y attributes para acceder a los detalles de la información de la ejecución. MLflow admite expresiones unidas por la palabra clave AND (la sintaxis no admite OR):
La búsqueda se ejecuta según el valor de un parámetro:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")Advertencia
Solo se admiten los operadores
=,likey!=para filtrarparameters.Buscar ejecuciones en función del valor de una métrica:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")Buscar ejecuciones con una etiqueta determinada:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")Buscar ejecuciones creadas por un usuario determinado:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")Buscar ejecuciones con errores. Consulte Filtrado de ejecuciones por estado para ver los valores posibles:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")Buscar ejecuciones creadas después de un tiempo determinado:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")Sugerencia
Para la clave
attributes, los valores deben ser siempre cadenas y, por tanto, estar codificados entre comillas.Ejecuciones de búsqueda que tardan más de una hora:
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")Sugerencia
attributes.durationno está presente en el software de código abierto de MLflow, pero se proporciona en Azure Machine Learning para mayor comodidad.Ejecuciones de búsqueda que tienen el identificador en un conjunto determinado:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
Filtrado de ejecuciones por estado
Al filtrar las ejecuciones por estado, MLflow usa una convención diferente para asignar un nombre al estado posible diferente de una ejecución en comparación con Azure Machine Learning. En la tabla siguiente, se muestran los valores posibles:
| Estado del trabajo de Azure Machine Learning | attributes.status de MLFlow |
Significado |
|---|---|---|
| Sin iniciar | Scheduled |
Azure Machine Learning recibió el trabajo o la ejecución. |
| Cola | Scheduled |
El trabajo o la ejecución está programado para ejecutarse, pero aún no se ha iniciado. |
| Preparing (En preparación) | Scheduled |
El trabajo o la ejecución aún no se han iniciado, pero se asignó un proceso para su ejecución y se está preparando el entorno y sus entradas. |
| En ejecución | Running |
El trabajo o ejecución se encuentra actualmente en ejecución activa. |
| Completado | Finished |
El trabajo o ejecución se completó sin errores. |
| Con error | Failed |
El trabajo o ejecución se completó con errores. |
| Canceled | Killed |
El usuario canceló el trabajo o la ejecución, o se finalizó por el sistema. |
Ejemplo:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
Obtención de métricas, parámetros, artefactos y modelos
El método search_runs devuelve un Pandas Dataframe que contiene una cantidad limitada de información de forma predeterminada. En caso necesario, es posible obtener objetos de Python que pudieran ser útiles para ver más detalles sobre estos. Use el output_format parámetro para controlar cómo se devuelve la salida:
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
Se puede acceder a los detalles desde el miembro info. En el siguiente ejemplo se muestra cómo obtener run_id:
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
Obtención de parámetros y métricas de una ejecución
Cuando se devuelven ejecuciones mediante output_format="list", puede acceder fácilmente a parámetros mediante la clave data:
last_run.data.params
De la misma manera, puede consultar las métricas:
last_run.data.metrics
Para las métricas que contienen varios valores (por ejemplo, una curva de pérdida o una curva PR), solo se devuelve el último valor registrado de la métrica. Si quiere recuperar todos los valores de una métrica determinada, use el método mlflow.get_metric_history. Este método requiere que use MlflowClient:
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
Obtención de artefactos de una ejecución
MLflow puede consultar cualquier artefacto registrado por una ejecución. No se puede acceder a los artefactos mediante el propio objeto de ejecución y se debería usar el cliente de MLflow en su lugar:
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
El método anterior enumera todos los artefactos registrados en la ejecución, pero permanecen almacenados en el almacén de artefactos (almacenamiento de Azure Machine Learning). Para descargar cualquiera de ellos, use el método download_artifact:
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
Nota:
En las versiones heredadas de MLflow (<2.0), use el método MlflowClient.download_artifacts() en su lugar.
Obtención de modelos de una ejecución
Los modelos también se pueden registrar en la ejecución y, a continuación, recuperarse directamente desde esta. Para recuperar un modelo, es necesario conocer la ruta de acceso al artefacto donde se almacene. El método list_artifacts se puede usar para buscar artefactos que representen un modelo, ya que los modelos de MLflow siempre son carpetas. Descargue un modelo de manera que especifique la ruta de acceso donde se almacene el modelo mediante el método download_artifact:
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
Después, puede volver a cargar el modelo desde los artefactos descargados mediante la función típica load_model en el espacio de nombres específico del tipo. En el ejemplo siguiente se usa xgboost:
model = mlflow.xgboost.load_model(model_local_path)
MLflow también permite realizar ambas operaciones a la vez y descargar y cargar el modelo en una sola instrucción. MLflow descarga el modelo en una carpeta temporal y lo carga desde allí. El método load_model usa un formato URI para indicar desde dónde se debe recuperar el modelo. En el caso de cargar un modelo desde una ejecución, la estructura de URI es la siguiente:
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
Sugerencia
Para consultar y cargar modelos registrados en el registro de modelos, consulte Administración de registros de modelos en Azure Machine Learning con MLflow.
Obtención de ejecuciones secundarias (anidadas)
MLflow admite el concepto de ejecuciones secundarias (anidadas). Estas ejecuciones resultan útiles cuando es necesario poner en marcha rutinas de entrenamiento que se deben seguir de forma independientemente del proceso de entrenamiento principal. Los procesos de optimización del ajuste de hiperparámetros o las canalizaciones de Azure Machine Learning son ejemplos típicos de trabajos que generan varias ejecuciones secundarias. Puede consultar todas las ejecuciones secundarias de una ejecución específica mediante la etiqueta de propiedad mlflow.parentRunId, que contiene el id. de ejecución de la ejecución primaria.
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
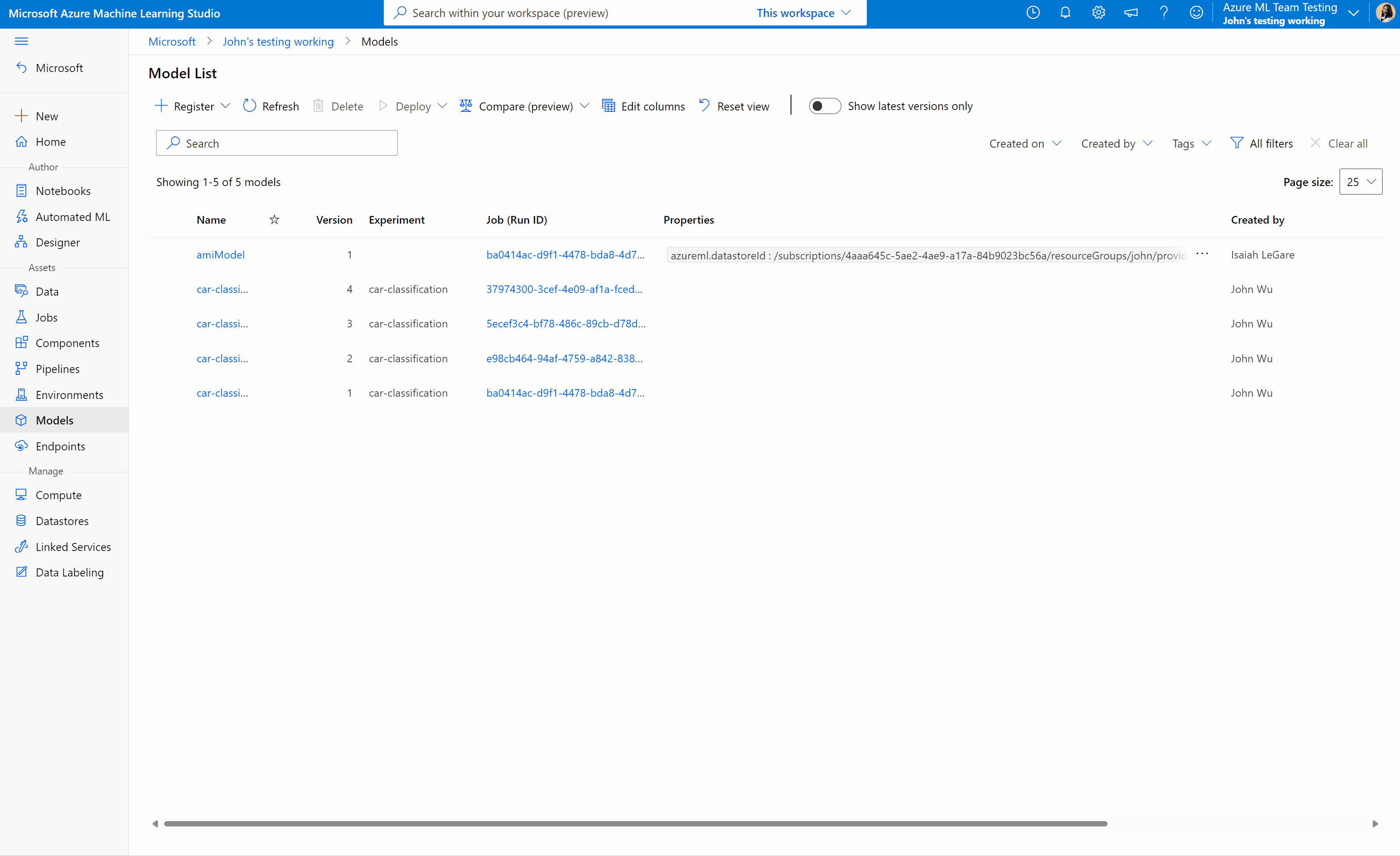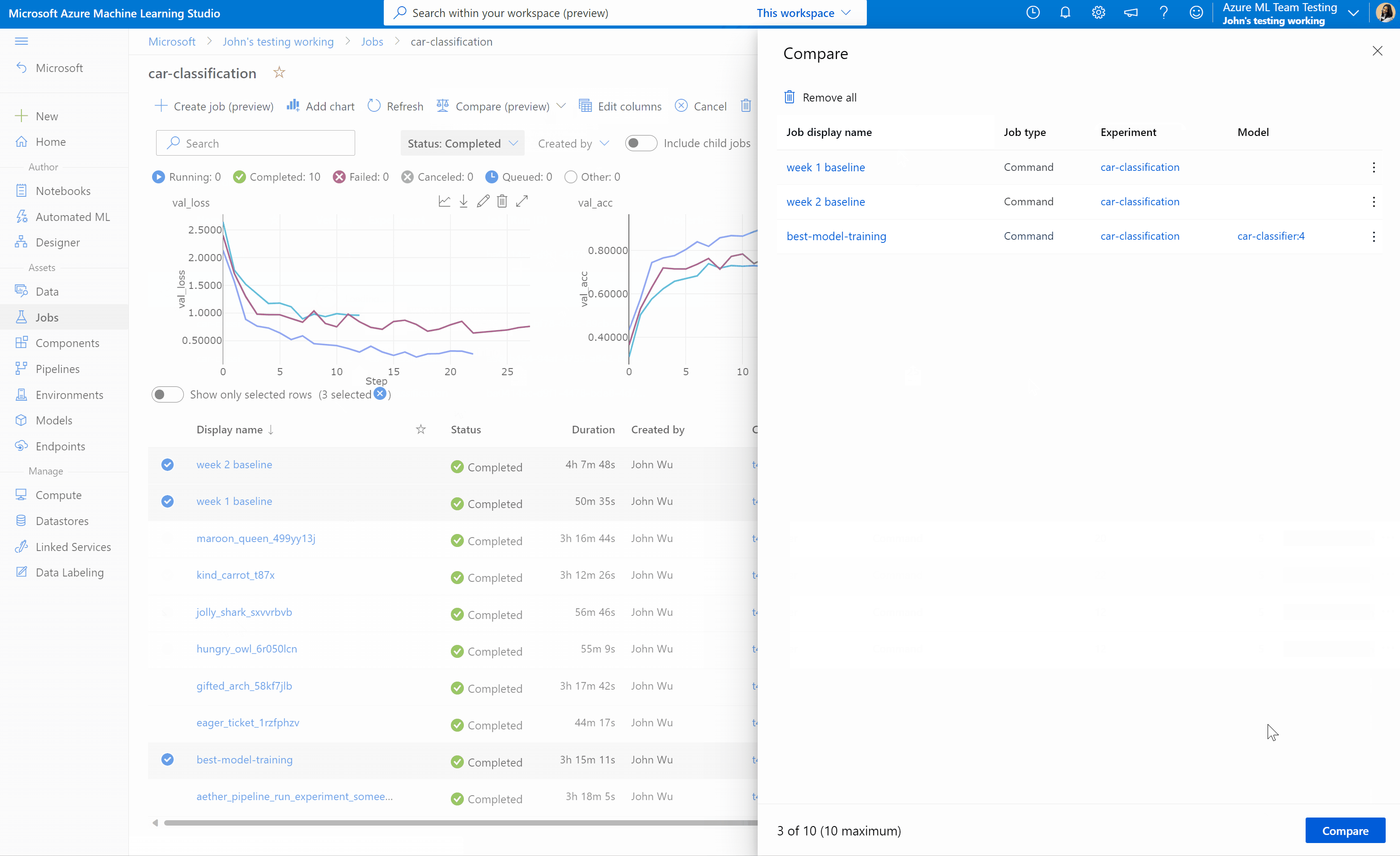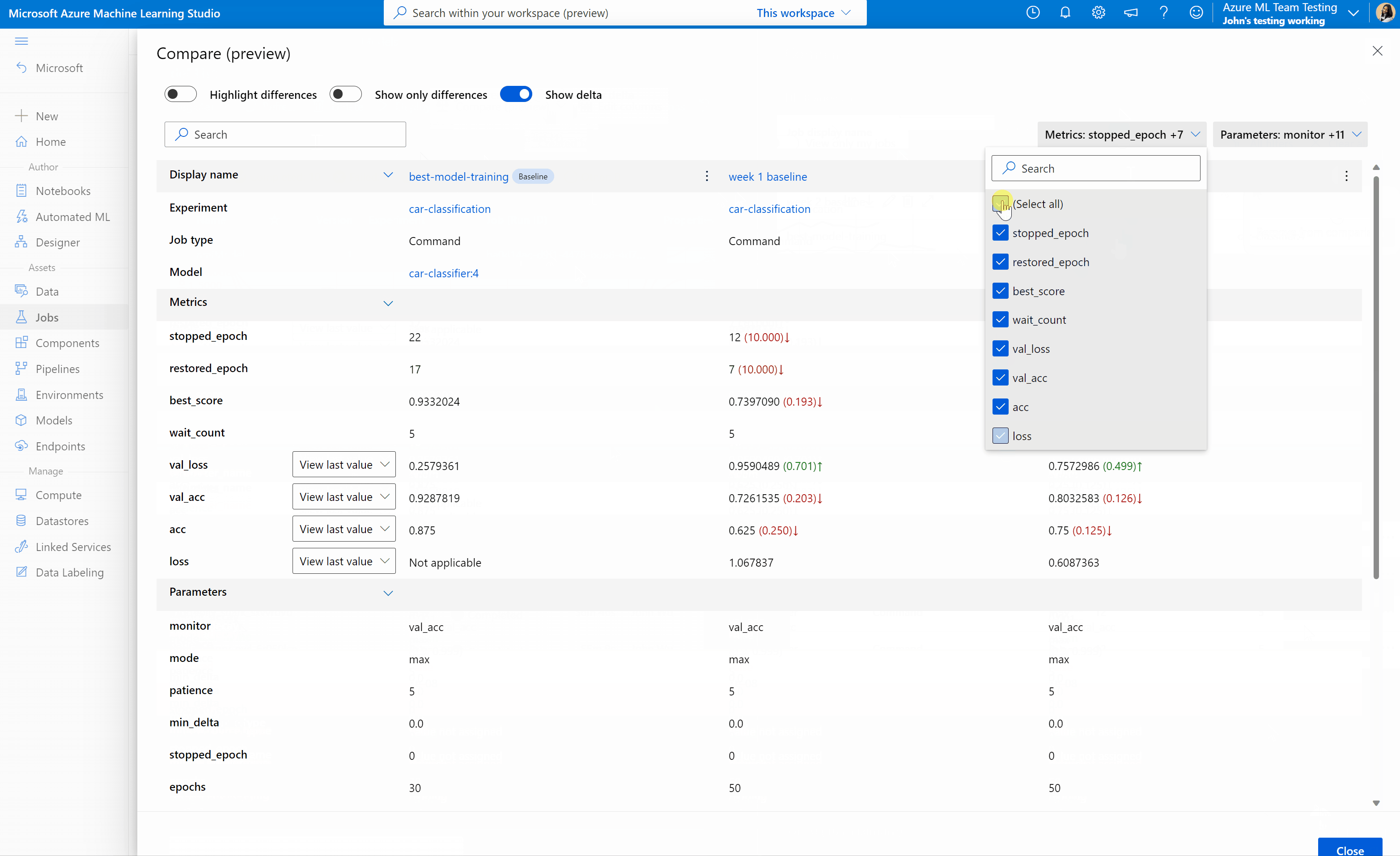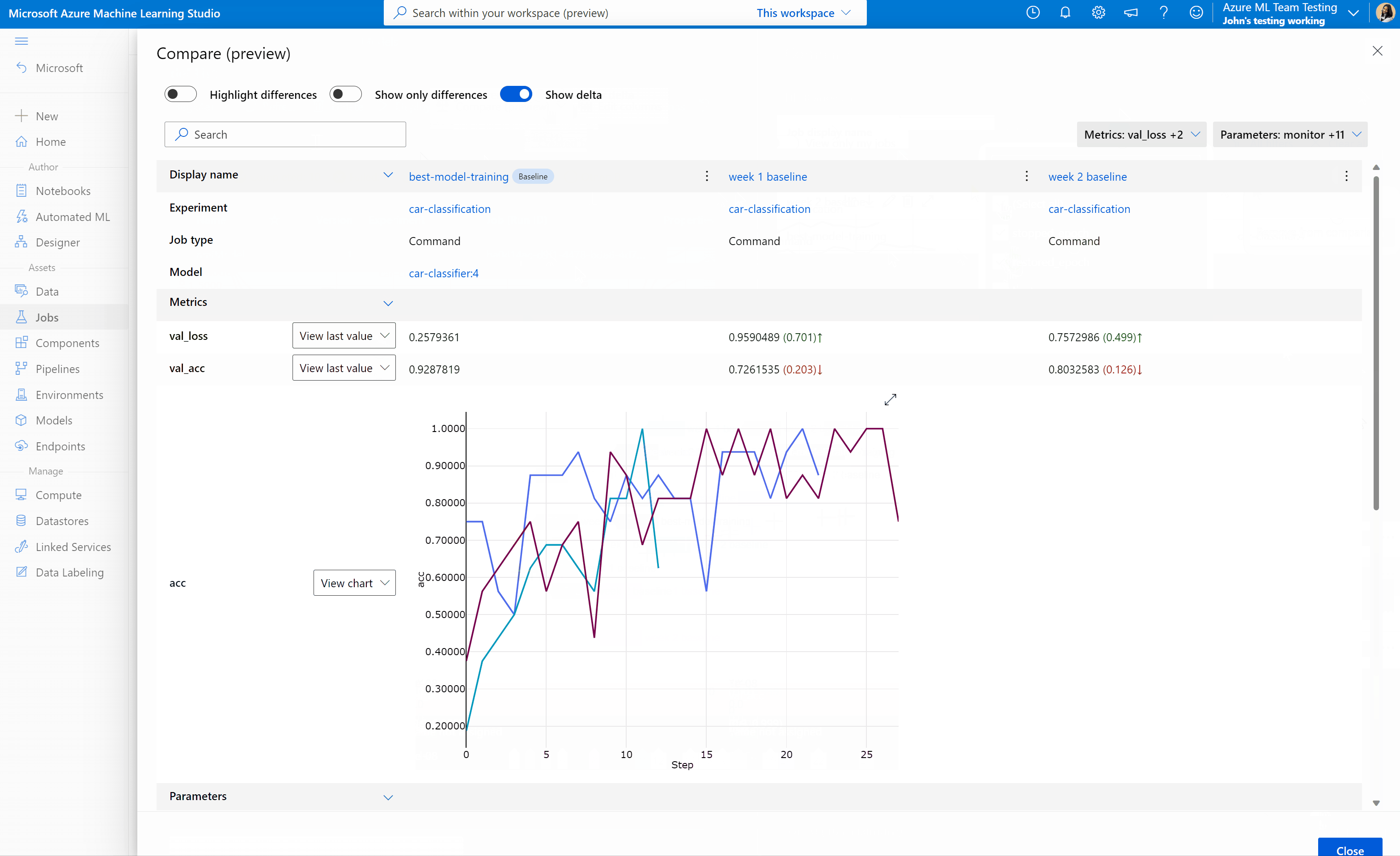
Comparación de trabajos y modelos en Estudio de Azure Machine Learning (versión preliminar)
Para comparar y evaluar la calidad de los trabajos y modelos en Estudio de Azure Machine Learning, use el panel de vista previa para habilitar la característica. Una vez habilitado, puede comparar los parámetros, las métricas y las etiquetas entre los trabajos o los modelos seleccionados.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Se ofrece la versión preliminar sin Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
En MLflow con cuadernos de Azure Machine Learning se demuestran y se analizan con mayor profundidad los conceptos presentados en este artículo.
- Entrenar y seguir un clasificador con MLflow: muestra cómo realizar un seguimiento de experimentos mediante MLflow, registrar modelos, así como combinar varios tipos en canalizaciones.
- Administración de experimentos y ejecuciones con MLflow: muestra cómo consultar experimentos, ejecuciones, métricas, parámetros y artefactos desde Azure Machine Learning mediante MLflow.
Matriz de compatibilidad para consultas de ejecuciones y experimentos
El SDK de MLflow expone varios métodos para recuperar ejecuciones, incluidas opciones para controlar lo que se devuelve y de qué manera. Consulte la tabla siguiente para obtener información sobre cuáles de esos métodos se admiten actualmente en MLflow cuando se conecta a Azure Machine Learning:
| Característica | Compatible con MLflow | Compatible con Azure Machine Learning |
|---|---|---|
| Ordenación de ejecuciones por atributos | ✓ | ✓ |
| Ordenación de ejecuciones por métricas | ✓ | 1 |
| Ordenación de ejecuciones por parámetros | ✓ | 1 |
| Ordenación de ejecuciones por etiquetas | ✓ | 1 |
| Filtrado de ejecuciones por atributos | ✓ | ✓ |
| Filtrado de ejecuciones por métricas | ✓ | ✓ |
| Filtrado de ejecuciones por métricas con caracteres especiales (con escape) | ✓ | |
| Filtrado de ejecuciones por parámetros | ✓ | ✓ |
| Filtrado de ejecuciones por etiquetas | ✓ | ✓ |
Filtrado de ejecuciones con comparadores numéricos (métricas), como =, !=, >, >=, < y <= |
✓ | ✓ |
Filtrado de ejecuciones con comparadores de cadenas (parámetros, etiquetas y atributos): = y != |
✓ | ✓2 |
Filtrado de ejecuciones con comparadores de cadenas (parámetros, etiquetas y atributos): LIKE/ILIKE |
✓ | ✓ |
Filtrado de ejecuciones con comparadores AND |
✓ | ✓ |
Filtrado de ejecuciones con comparadores OR |
||
| Cambio de nombre de experimentos | ✓ |
Nota
- 1 Consulte la sección Ordenar ejecuciones para ver instrucciones y ejemplos sobre cómo lograr la misma funcionalidad en Azure Machine Learning.
- 2
!=para etiquetas no admitidas.