Selección de algoritmos para Azure Machine Learning
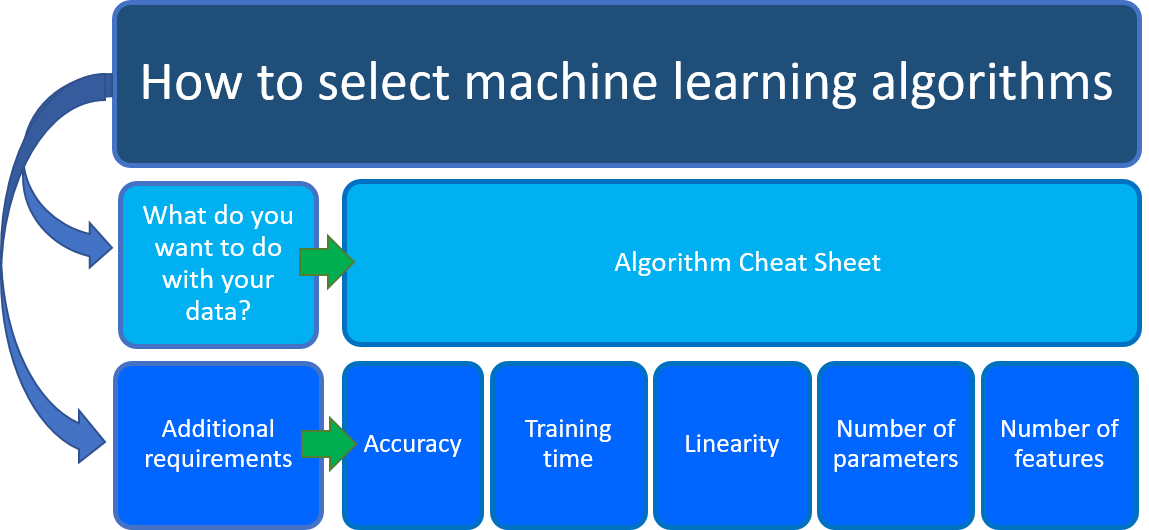
Si se pregunta qué algoritmo de aprendizaje automático usar, la respuesta depende principalmente de dos aspectos del escenario de ciencia de datos:
¿Qué quiere hacer con los datos? En concreto, ¿cuál es la pregunta empresarial que quiere responder aprendiendo de los datos anteriores?
¿Cuáles son los requisitos de su escenario de ciencia de datos? ¿Cuáles son las características, la precisión, el tiempo de entrenamiento, la linealidad y los parámetros que admite la solución?
Nota:
El diseñador de Azure Machine Learning admite dos tipos de componentes: componentes precompilados clásicos (v1) y componentes personalizados (v2). Estos dos tipos de componentes NO son compatibles.
Los componentes precompilados clásicos son principalmente para el procesamiento de datos y las tareas tradicionales de aprendizaje automático, como la regresión y la clasificación. Este tipo de componentes se sigue admitiendo, pero no se agregará ningún componente nuevo.
Los componentes personalizados le permiten ajustar su propio código como componente. Admiten el uso compartido de componentes entre áreas de trabajo y la creación sin problemas en las interfaces de Studio, CLI v2 y SDK v2.
En el caso de los nuevos proyectos, le recomendamos encarecidamente que use componentes personalizados, que son compatibles con AzureML V2 y seguirá recibiendo nuevas actualizaciones.
Este artículo se aplica a los componentes precompilados clásicos y no es compatible con la CLI v2 y SDK v2.
Hoja de características de los algoritmos de Machine Learning
La Hoja de referencia rápida de algoritmos de Azure Machine Learning le ayuda con la primera consideración: ¿Qué quiere hacer con los datos? En la hoja de referencia rápida, busque la tarea que desea realizar y busque un algoritmo Diseñador de Azure Machine Learning para la solución de análisis predictivo.
Nota:
Puede descargar la Hoja de referencia rápida de algoritmos de Machine Learning.
El diseñador proporciona una amplia cartera de algoritmos, como Bosque de decisión multiclase, Sistemas de recomendación, Regresión de red neuronal, Red neuronal multiclase, y Agrupación en clústeres K-means. Cada algoritmo está diseñado para solucionar un tipo distinto de problema de Machine Learning. Consulte la Referencia de componentes y algoritmos para obtener una lista completa junto con la documentación sobre cómo funciona cada algoritmo y cómo optimizar los parámetros para optimizar el algoritmo.
Junto con esta guía, tenga en cuenta otros requisitos al elegir un algoritmo de aprendizaje automático. A continuación se indican otros factores que deben tenerse en cuenta, como la precisión, el tiempo de entrenamiento, la linealidad, el número de parámetros y el número de características.
Comparación de algoritmos de aprendizaje automático
Algunos algoritmos realizan suposiciones concretas sobre la estructura de los datos o los resultados deseados. Si encuentra uno que se ajuste a sus necesidades, este puede ofrecerle resultados más útiles, predicciones más precisas o tiempos de entrenamiento más cortos.
En la tabla siguiente se resumen algunas de las características más importantes de los algoritmos de las familias de clasificación, regresión y agrupación en clústeres:
| Algoritmo | Precisión | Tiempo de entrenamiento | Linealidad | Parámetros | Notas |
|---|---|---|---|---|---|
| Familia de clasificación | |||||
| Regresión logística de dos clases | Bueno | Fast (rápido) | Sí | 4 | |
| Bosque de decisión de dos clases | Excelente | Moderado | No | 5 | Muestra los tiempos de puntuación más lentos. Se recomienda no trabajar Uno frente a todos multiclase, debido a tiempos de puntuación más lentos causados por el bloqueo de subproceso en la acumulación de predicciones de árbol |
| Árbol de decisión ampliado de dos clases | Excelente | Moderado | No | 6 | Uso de memoria grande |
| Red neuronal de dos clases | Bueno | Moderado | No | 8 | |
| Perceptrón promedio de dos clases | Bueno | Moderado | Sí | 4 | |
| Máquina de vectores de soporte de dos clases | Bueno | Fast (rápido) | Sí | 5 | Útil para conjuntos de características de gran tamaño |
| Regresión logística multiclase | Bueno | Fast (rápido) | Sí | 4 | |
| Bosque de decisión multiclase | Excelente | Moderado | No | 5 | Muestra los tiempos de puntuación más lentos. |
| Árbol de decisión ampliado multiclase | Excelente | Moderado | No | 6 | Tiende a mejorar la precisión a pesar de correr el riesgo de tener menor cobertura. |
| Red neuronal multiclase | Bueno | Moderado | No | 8 | |
| Uno frente a todos multiclase | - | - | - | - | Vea las propiedades del método de dos clases seleccionado |
| Familia de regresión | |||||
| Regresión lineal | Bueno | Fast (rápido) | Sí | 4 | |
| Regresión de bosque de decisión | Excelente | Moderado | No | 5 | |
| Regresión del árbol de decisión potenciado | Excelente | Moderado | No | 6 | Uso de memoria grande |
| Regresión de red neuronal | Bueno | Moderado | No | 8 | |
| Familia de agrupación en clústeres | |||||
| Agrupación en clústeres K-Means | Excelente | Moderado | Sí | 8 | Un algoritmo de agrupación en clústeres |
Requisitos del escenario de ciencia de datos
Una vez que sepa lo que quiere hacer con los datos, debe determinar otros requisitos para el escenario de ciencia de datos.
Elija las opciones y posibles compensaciones para los siguientes requisitos:
- Precisión
- Tiempo de entrenamiento
- Linealidad
- Cantidad de parámetros
- Cantidad de características
Precisión
La precisión de Machine Learning mide la eficacia de un modelo como la proporción de resultados verdaderos en comparación con el total de casos. En el diseñador, el componente Evaluate Model (Evaluar modelo) calcula un conjunto de métricas de evaluación estándar del sector. Puede usar este componente para medir la precisión de un modelo entrenado.
No siempre es necesario obtener la respuesta más precisa posible. A veces, una aproximación ya es útil, según para qué se la desee usar. Si ese es el caso, es posible que pueda reducir drásticamente el tiempo de procesamiento al seguir con métodos más aproximados. Los métodos aproximados también tienden naturalmente a evitar el sobreajuste.
Hay tres formas de usar el componente Evaluar modelo:
- Genere puntuaciones sobre los datos de entrenamiento para evaluar el modelo.
- Genere puntuaciones en el modelo, pero compare esas puntuaciones con puntuaciones en un conjunto de pruebas reservado.
- Compare las puntuaciones de dos modelos diferentes, pero relacionados, con el mismo conjunto de datos.
Para obtener una lista completa de las métricas y los enfoques que se pueden usar para evaluar la precisión de los modelos de Machine Learning, vea Componente Evaluar modelo.
Tiempo de entrenamiento
En el aprendizaje supervisado, el entrenamiento significa utilizar datos históricos para crear un modelo de Machine Learning que minimiza los errores. La cantidad de minutos u horas necesarios para entrenar un modelo varía mucho según el algoritmo. A menudo, el tiempo de entrenamiento depende en gran medida de la precisión; por lo general, un factor acompaña al otro.
Además, algunos algoritmos son más sensibles a la cantidad de puntos de datos que otros. Puede elegir un algoritmo concreto porque tiene una limitación de tiempo, sobre todo cuando el conjunto de datos es grande.
En el diseñador, la creación y el uso de un modelo de aprendizaje automático suele ser un proceso de tres pasos:
Para configurar un modelo, elija un tipo de algoritmo concreto y, posteriormente, defina sus parámetros o hiperparámetros.
Proporcione un conjunto de datos etiquetado y que tenga datos compatibles con el algoritmo. Conecte los datos y el modelo al componente entrenar modelo.
Una vez que finalice el entrenamiento, use el modelo entrenado con uno de los componentes de puntuación para realizar predicciones sobre datos nuevos.
Linealidad
La linealidad en estadísticas y aprendizaje automático significa que hay una relación lineal entre una variable y una constante en el conjunto de datos. Por ejemplo, los algoritmos de clasificación lineal asumen que las clases pueden estar separadas mediante una línea recta (o su análogo de mayores dimensiones).
Muchos algoritmos de aprendizaje automático hacen uso de la linealidad. En el diseñador de Azure Machine Learning, incluyen:
Los algoritmos de regresión lineal suponen que las tendencias de datos siguen una línea recta. Esta suposición no es perjudicial en ciertos problemas, pero en otros reduce la precisión. A pesar de sus inconvenientes, los algoritmos lineales son muy usados como primera estrategia. Tienden a ser algorítmicamente sencillos y rápidos para entrenar.
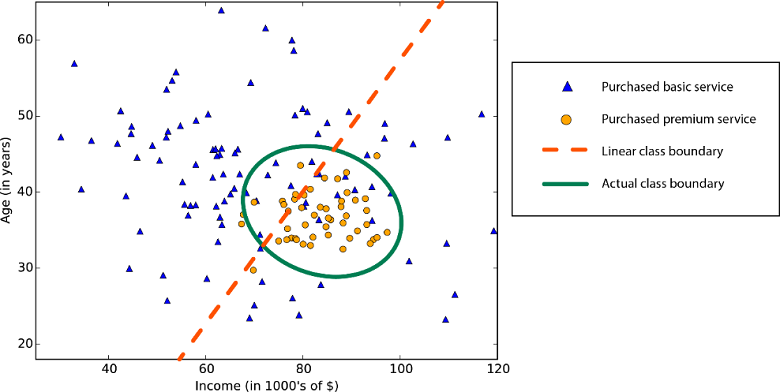
Límite de clase no lineal: la dependencia de un algoritmo de clasificación lineal se traduciría en una baja precisión.
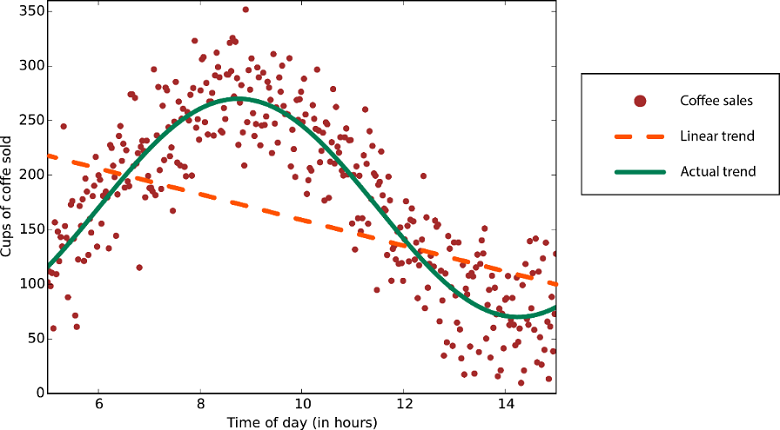
Datos con tendencia no lineal: el uso de un método de regresión lineal generaría más errores de los necesarios.
Cantidad de parámetros
Los parámetros son los botones que un científico de datos obtiene al configurar un algoritmo. Son números que afectan al comportamiento del algoritmo, como tolerancia a errores o número de iteraciones, o opciones entre variantes de cómo se comporta el algoritmo. Tanto el tiempo de entrenamiento como la precisión del algoritmo a veces pueden ser sensibles y requerir solo la configuración correcta. Normalmente, los algoritmos con parámetros de números grandes requieren la mayor cantidad de pruebas y errores posible para encontrar una buena combinación.
Como alternativa, hay el componente Ajustar hiperparámetros de modelo en el diseñador. El objetivo de este componente es determinar los hiperparámetros óptimos para un modelo de aprendizaje automático. El componente compila y prueba varios modelos con diferentes combinaciones de valores. Compara las métricas de todos los modelos para obtener las combinaciones de valores.
Aunque esta es una excelente manera de asegurarse de que ha distribuido el espacio de parámetros, el tiempo necesario para entrenar un modelo aumenta exponencialmente con el número de parámetros. La ventaja es que tener muchos parámetros normalmente indica que un algoritmo tiene mayor flexibilidad. Por lo general, puede conseguir una precisión muy elevada, siempre y cuando se encuentre la combinación correcta de configuraciones de parámetros.
Cantidad de características
En el aprendizaje automático, una característica es una variable cuantificable del fenómeno que intenta analizar. Para ciertos tipos de datos, la cantidad de características puede ser muy grande en comparación con la cantidad de puntos de datos. Este suele ser el caso de la genética o los datos textuales.
Una gran cantidad de características puede trabar algunos algoritmos de aprendizaje, lo que hace que el tiempo de entrenamiento sea demasiado largo. Máquinas de vectores de soporte técnico son adecuadas para escenarios con un gran número de características. Por esta razón, se han usado en muchas aplicaciones, desde la recuperación de información hasta la clasificación de texto e imágenes. Las máquinas de vectores de soporte pueden usarse para tareas de clasificación y regresión.
Dada una salida específica, la selección de características hace referencia al proceso de aplicación de pruebas estadísticas a las entradas. para determinar qué columnas son más predecibles de la salida. El Componente Selección de características basada en filtros en el diseñador proporciona varios algoritmos de selección de características entre los que elegir. El componente incluye métodos de correlación como la correlación de Pearson y valores de la prueba χ2.
También puede usar el componente Importancia de la característica de permutación para calcular un conjunto de puntuaciones de importancia de la característica del conjunto de resultados. A continuación, puede usar estas puntuaciones para ayudarle a determinar las mejores características que se usarán en un modelo.