Implementación de un modelo en un clúster de Azure Kubernetes Service con v1
Importante
En este artículo se explica cómo usar la CLI de Azure Machine Learning (v1) y el SDK de Azure Machine Learning para Python (v1) para implementar un modelo. Para obtener el enfoque recomendado para v2, consulte Implementación y puntuación de un modelo de Machine Learning con un punto de conexión en línea.
Aprenda a usar Azure Machine Learning para implementar un modelo como un servicio web en Azure Kubernetes Service (AKS). AKS útil para las implementaciones de producción a gran escala. Use AKS si necesita una o varias de las siguientes funcionalidades:
- Tiempo de respuesta rápido
- Escalado automático del servicio implementado
- Logging
- Recopilación de datos de modelos
- Autenticación
- Finalización de TLS
- Opciones de aceleración de hardware, como GPU y matrices de puertas programables (FPGA)
Al implementar en una instancia de AKS, la implementación se realiza en el clúster de AKS que está conectado al área de trabajo. Para obtener información sobre cómo conectar un clúster de AKS al área de trabajo, consulte Creación y conexión de un clúster de Azure Kubernetes Service.
Importante
Se recomienda depurar localmente antes de la implementación en el servicio web. Para obtener más información, consulte Solución de problemas con una implementación de modelo local.
Nota:
Los puntos de conexión de Azure Machine Learning (v2) proporcionan una experiencia de implementación mejorada y más sencilla. Los puntos de conexión admiten escenarios de inferencia por lotes y en tiempo real. Los puntos de conexión proporcionan una interfaz unificada para invocar y administrar implementaciones de modelos entre tipos de proceso. Consulte ¿Qué son los puntos de conexión de Azure Machine Learning?.
Prerrequisitos
Un área de trabajo de Azure Machine Learning. Para más información, consulte Creación de un área de trabajo de Azure Machine Learning.
Un modelo de Machine Learning registrado en el área de trabajo. Si no tiene un modelo registrado, consulte Implementación de modelos de Machine Learning en Azure.
La extensión de la CLI de Azure (v1) para Machine Learning Service, el SDK de Python para Azure Machine Learning o la extensión de Visual Studio Code para Azure Machine Learning.
Importante
Algunos de los comandos de la CLI de Azure de este artículo usan la extensión
azure-cli-mlo v1 para Azure Machine Learning. La compatibilidad con la extensión v1 finalizará el 30 de septiembre de 2025. Puede instalar y usar la extensión v1 hasta esa fecha.Se recomienda pasar a la extensión
ml, o v2, antes del 30 de septiembre de 2025. Para más información sobre la extensión v2, consulte extensión de la CLI de Azure Machine Learning y SDK de Python v2.En los fragmentos de código de Python de este artículo se supone que se han establecido las siguientes variables:
-
ws: establézcalo en su área de trabajo. -
model: establézcalo en el modelo registrado. -
inference_config: establézcalo en la configuración de inferencia del modelo.
Para más información acerca de cómo establecer estas variables, consulte el artículo en el que se explica cómo y dónde se implementan los modelos.
-
En los fragmentos de código de la CLI de este artículo se supone que ya ha creado un documento de inferenceconfig.json. Para más información sobre cómo crear este documento, consulte Implementación de modelos de Machine Learning en Azure.
Un clúster de AKS conectado al área de trabajo. Para obtener más información, consulte Creación y conexión de un clúster de Azure Kubernetes Service.
- Si quiere implementar modelos en nodos de GPU o en nodos de FPGA (o en cualquier producto específico), debe crear un clúster con el producto específico. No se admite la creación de un grupo de nodos secundarios en un clúster existente ni la implementación de modelos en el grupo de nodos secundarios.
Comprender los procesos de implementación
La palabra implementación se usa en Kubernetes y Azure Machine Learning.
Implementación tiene significados diferentes en estos dos contextos. En Kubernetes, una implementación es una entidad concreta, que se especifica con un archivo YAML declarativo. Una implementación de Kubernetes tiene un ciclo de vida definido y relaciones concretas con otras entidades de Kubernetes, como Pods y ReplicaSets. Puede obtener información sobre Kubernetes desde documentos y vídeos en ¿Qué es Kubernetes?.
En Azure Machine Learning, implementación se usa en el sentido general de poner a disposición y limpiar los recursos del proyecto. Los pasos que Azure Machine Learning considera parte de la implementación son:
- Comprimir los archivos de la carpeta del proyecto y omitir los especificados en .amlignore o .gitignore
- Escalar verticalmente el clúster de proceso (se relaciona con Kubernetes)
- Compilar o descargar el Dockerfile en el nodo de proceso (se relaciona con Kubernetes)
- El sistema calcula un valor de hash de:
- La imagen base
- Pasos personalizados de Docker (consulte Implementación de un modelo con una imagen base de Docker personalizada)
- El archivo YAML de definición de Conda (consulte Creación y uso de entornos de software en Azure Machine Learning)
- El sistema utiliza este valor de hash como clave en una búsqueda de la instancia de Azure Container Registry (ACR) del área de trabajo.
- Si no la encuentra, busca una coincidencia en la instancia de ACR global
- Si no existe, el sistema genera una imagen que se almacena en la memoria caché y se inserta en la instancia de ACR del área de trabajo
- El sistema calcula un valor de hash de:
- Descargar el archivo de proyecto comprimido en el almacenamiento temporal del nodo de proceso.
- Descomprimir el archivo de proyecto.
- El nodo de proceso que ejecuta
python <entry script> <arguments>. - Guardar registros, archivos de modelo y otros archivos escritos en ./outputs en la cuenta de almacenamiento asociada con el área de trabajo
- Reducir verticalmente el proceso, incluida la eliminación del almacenamiento temporal (se relaciona con Kubernetes)
Enrutador de Azure Machine Learning
El componente de front-end (azureml-fe) que enruta las solicitudes de inferencia entrantes a los servicios implementados se escala automáticamente según sea necesario. El escalado de azureml-fe se basa en el propósito y el tamaño (número de nodos) del clúster de AKS. El propósito y los nodos del clúster se configuran cuando se crea o conecta un clúster de AKS. Hay un servicio azureml-fe por clúster, que puede ejecutarse en varios pods.
Importante
- Al usar un clúster configurado como
dev-test, el escalador automático está deshabilitado. Incluso para los clústeres fastProd/DenseProd, Self-Scaler solo está habilitado cuando la telemetría muestra que es necesario. - Azure Machine Learning no carga ni almacena automáticamente registros de ningún contenedor, ni siquiera de los contenedores del sistema. Para una depuración completa, se recomienda habilitar Container Insights para el clúster de AKS. Esto le permite guardar, administrar y compartir registros de contenedor con el equipo de AML cuando sea necesario. Sin esto, AML no puede garantizar la compatibilidad con los problemas relacionados con azureml-fe.
- La carga máxima de la solicitud es de 100 MB.
Azureml-fe escala tanto verticalmente para usar más núcleos cono horizontalmente para usar más pods. Al tomar la decisión de escalar verticalmente, se utiliza el tiempo que se tarda en enrutar las solicitudes de inferencia entrantes. Si este tiempo supera el umbral, se produce una escalabilidad vertical. Si el tiempo para enrutar las solicitudes entrantes sigue superando el umbral, se produce una escalabilidad horizontal.
Al reducir vertical y horizontalmente, se emplea el uso de la CPU. Si se cumple el umbral de uso de la CPU, el front-end se reducirá verticalmente en primer lugar. Si el uso de la CPU desciende hasta el umbral de reducción horizontal, se produce una operación de reducción horizontal. El escalado vertical y horizontal solo se producirá si hay suficientes recursos de clúster disponibles.
Al escalar o reducir verticalmente, se reiniciarán los pods azureml-fe para aplicar los cambios de CPU o de memoria. Los reinicios no afectan a las solicitudes de inferencia.
Descripción de los requisitos de conectividad para el clúster de inferencia de AKS
Cuando Azure Machine Learning crea o adjunta un clúster de AKS, el clúster de AKS se implementa con uno de los dos modelos de red siguientes:
- Red de kubenet: los recursos de la red normalmente se crean y se configuran cuando se implementa el clúster de AKS.
- Redes Azure Container Networking Interface (CNI): el clúster de AKS está conectado a configuraciones y a un recurso de red virtual existente.
En el caso de las redes Kubenet, la red se crea y configura correctamente para Azure Machine Learning Service. En el caso de las redes CNI, debe comprender los requisitos de conectividad y garantizar la resolución de DNS y la conectividad saliente para la inferencia de AKS. Por ejemplo, puede que esté usando un firewall para bloquear el tráfico de red.
En el diagrama siguiente se muestran todos los requisitos de conectividad para la inferencia de AKS. Las flechas negras representan la comunicación real y las flechas azules representan los nombres de dominio. Es posible que tenga que agregar entradas para estos hosts al firewall o al servidor DNS personalizado.
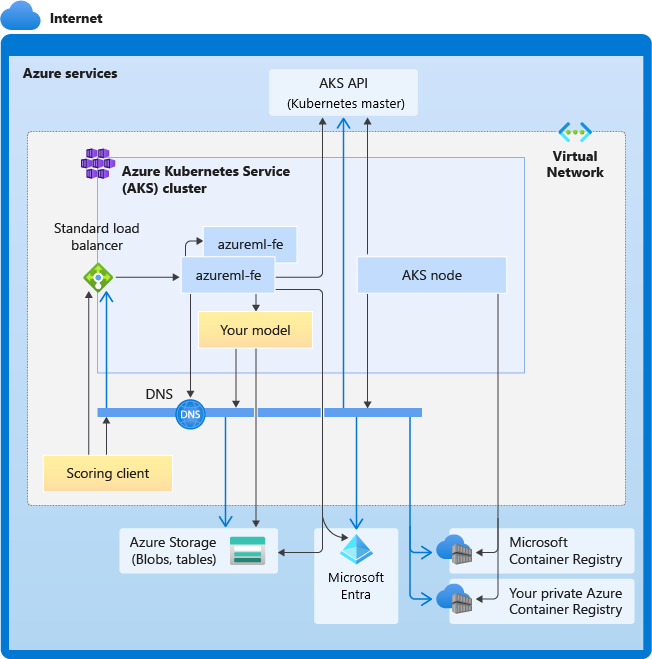
Para conocer los requisitos generales de conectividad de AKS, consulte Limitar el tráfico de red con Azure Firewall en AKS.
Para acceder a los servicios de Azure Machine Learning detrás de un firewall, vea Configuración del tráfico de red entrante y saliente.
Requisitos generales de resolución de DNS
La resolución DNS dentro de una red virtual existente está bajo su control. Por ejemplo, un firewall o un servidor DNS personalizado. Los hosts siguientes deben ser accesibles:
| Nombre de host | Usado por |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Servidor de API de AKS |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Su instancia de Azure Container Registry (ACR) |
<account>.table.core.windows.net |
Cuenta de Azure Storage (Table Storage) |
<account>.blob.core.windows.net |
Cuenta de Azure Storage (Blob Storage) |
api.azureml.ms |
Autenticación de Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Punto de conexión de Kusto para cargar telemetría |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Nombre de dominio del punto de conexión, si lo generó automáticamente con Azure Machine Learning. Si usó un nombre de dominio personalizado, no necesita esta entrada. |
Requisitos de conectividad en orden cronológico
En el proceso de creación o conexión de AKS, el enrutador de Azure Machine Learning (azureml-fe) se implementa en el clúster de AKS. Para implementar el enrutador de Azure Machine Learning, el nodo de AKS debe ser capaz de lo siguiente:
- Resolver DNS para el servidor de API de AKS
- Resolver DNS para MCR a fin de descargar imágenes de Docker para el enrutador de Azure Machine Learning
- Descargar imágenes de MCR, donde se requiere conectividad saliente
Justo después de implementar azureml-fe, se intentará iniciar, y esto requiere:
- Resolver DNS para el servidor de API de AKS
- Consultar el servidor de API de AKS para detectar otras instancias de sí mismo (es un servicio multipod)
- Conectarse a otras instancias de sí mismo
Una vez iniciado azureml-fe, requiere conectividad adicional para funcionar correctamente:
- Conectarse a Azure Storage para descargar la configuración dinámica
- Resolver DNS para el servidor de autenticación de Microsoft Entra api.azureml.ms y comunicarse con él cuando el servicio implementado use la autenticación de Microsoft Entra.
- Consultar al servidor API de AKS para detectar modelos implementados
- Comunicar con modelos POD implementados
En el momento de la implementación del modelo, para un nodo AKS de implementación de modelo correcta, debe ser capaz de:
- Resolver DNS para ACR del cliente
- Descargar imágenes del ACR del cliente
- Resolver DNS para Azure BLOB donde se almacena el modelo
- Descargar modelos de Azure BLOB
Una vez implementado el modelo y cuando se inicie el servicio, azureml-fe lo detectará automáticamente mediante la API de AKS y estará listo para enrutar la solicitud al mismo. Debe ser capaz de comunicarse con los POD modelo.
Nota:
Si el modelo implementado requiere cualquier conectividad (por ejemplo, consultar la base de datos externa u otro servicio REST, descargar un BLOB), se debe habilitar tanto la resolución DNS como la comunicación saliente para estos servicios.
Implementación en AKS
Para implementar un modelo en AKS, cree una configuración de implementación que describa los recursos de proceso necesarios. Por ejemplo, el número de núcleos y la memoria. También necesita una configuración de inferencia, que describe el entorno necesario para hospedar el modelo y el servicio web. Para más información sobre cómo crear la configuración de inferencia, consulte Cómo y dónde implementar modelos.
Nota
El número de modelos que se implementará se limita a 1000 modelos por implementación (por contenedor).
SE APLICA A: Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Para más información acerca de las clases, los métodos y los parámetros que se usan en este ejemplo, consulte los siguientes documentos de referencia:
Escalado automático
SE APLICA A:Azure ML del SDK de Python v1
El componente que controla el escalado automático para las implementaciones de modelos de Azure Machine Learning es azureml-fe, que es un enrutador de solicitudes inteligente. Dado que todas las solicitudes de inferencia pasan por él, tiene los datos necesarios para escalar automáticamente los modelos implementados.
Importante
No habilite el Escalador horizontal automático de pods (HPA) de Kubernetes para las implementaciones de modelos. Si lo hace, los dos componentes de escalado automático competirán entre sí. Azureml-fe está diseñado para el escalado automático de modelos implementados por Azure Machine Learning, donde HPA tendría que adivinar o estimar el uso del modelo a partir de una métrica genérica, como el uso de la CPU o una configuración de métricas personalizada.
Azureml-fe no escala el número de nodos en un clúster de AKS, ya que esto podría provocar un aumento inesperado en los costos. En su lugar, escala el número de réplicas para el modelo dentro de los límites del clúster físico. Si necesita escalar el número de nodos dentro del clúster, puede escalar manualmente el clúster o configurar el escalador automático del clúster de AKS.
Para controlar el escalado automático, se puede establecer autoscale_target_utilization, autoscale_min_replicas y autoscale_max_replicas para el servicio web de AKS. En el ejemplo siguiente se muestra cómo habilitar el escalado automático:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
Las decisiones de escalar o reducir verticalmente se basan en el uso de las réplicas de contenedores actuales. El número de réplicas que están ocupadas (procesando una solicitud) dividido por el número total de réplicas actuales es el uso actual. Si este número supera autoscale_target_utilization, se crean más réplicas. Si es menor, se reducen las réplicas. De manera predeterminada, la utilización de destino es del 70 %.
Las decisiones de agregar réplicas son diligentes y rápidas (aproximadamente un segundo). Las decisiones de quitar réplicas son conservadoras (aproximadamente un minuto).
Puede calcular las réplicas necesarias mediante el código siguiente:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Para obtener más información sobre cómo configurar autoscale_target_utilization, autoscale_max_replicas y autoscale_min_replicas, consulte la referencia de módulo AksWebservice.
Autenticación de servicio web
Cuando se implementa en Azure Kubernetes Service, la autenticación basada en claves se habilita de manera predeterminada. También puede habilitar la autenticación basada en tokens. Para la autenticación basada en tokens, los clientes deben usar una cuenta de Microsoft Entra para solicitar un token de autenticación, que se usa para hacer solicitudes al servicio implementado.
Para deshabilitar la autenticación, establezca el parámetro auth_enabled=False al crear la configuración de implementación. En el siguiente ejemplo se deshabilita la autenticación mediante el SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Para obtener información sobre la autenticación desde una aplicación cliente, consulte Consumir un modelo de Azure Machine Learning que está implementado como un servicio web.
Autenticación con claves
Si la autenticación con claves está habilitada, puede usar el método get_keys para recuperar una clave de autenticación primaria y secundaria:
primary, secondary = service.get_keys()
print(primary)
Importante
Si necesita regenerar una clave, use service.regen_key.
Autenticación con tokens
Para habilitar la autenticación por tokens, establezca el parámetro token_auth_enabled=True cuando cree o actualice una implementación. En el ejemplo siguiente se habilita la autenticación por tokens con el SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Si la autenticación por tokens está habilitada, puede usar el método get_token para recuperar un token JWT y la hora de expiración de los tokens:
token, refresh_by = service.get_token()
print(token)
Importante
Tendrá que solicitar un nuevo token después de la hora refresh_by del token.
Microsoft recomienda crear el área de trabajo de Azure Machine Learning en la misma región que el clúster de AKS. Para autenticarse con un token, el servicio web hará una llamada a la región en la que se crea el área de trabajo de Azure Machine Learning. Si la región del área de trabajo no está disponible, no se podrá capturar un token para el servicio web, incluso si el clúster está en una región distinta del área de trabajo. Esto produce que la autenticación basada en tokens no esté disponible hasta que la región del área de trabajo vuelva a estar disponible. Además, cuanto mayor sea la distancia entre la región del clúster y la región del área de trabajo, más tiempo tardará la captura de un token.
Para recuperar un token, debe usar el SDK de Azure Machine Learning o el comando az ml service get-access-token.
Examen de vulnerabilidades
Microsoft Defender for Cloud proporciona características unificadas de administración para la seguridad y protección contra amenazas en todas las cargas de trabajo en la nube híbrida. Debe permitir que Microsoft Defender for Cloud analice los recursos y siga sus recomendaciones. Para obtener más información, consulte Seguridad de los contenedores en Microsoft Defender para contenedores.
Contenido relacionado
- Uso del control de acceso basado en roles de Azure para la autorización de Kubernetes
- Protección de un entorno de inferencia de Azure Machine Learning con redes virtuales
- Uso de un contenedor personalizado para implementar un modelo en un punto de conexión en línea
- Solución de problemas de una implementación de modelo remota
- Actualización de un servicio web implementado
- Uso de TLS para proteger un servicio web con Azure Machine Learning
- Consumir un modelo de Azure Machine Learning que está implementado como un servicio web
- Supervisión y recopilación de datos de los puntos de conexión del servicio web ML
- Recopilación de datos de modelos en producción