Solución de problemas de ParallelRunStep
SE APLICA A: SDK de Python azureml v1
SDK de Python azureml v1
En este artículo aprenderá a solucionar los errores que se producen al usar la clase ParallelRunStep con el SDK de Azure Machine Learning.
Para obtener sugerencias generales sobre la solución de problemas de una canalización, consulte Solución de problemas de canalizaciones de aprendizaje automático.
Prueba de scripts de forma local
La clase ParallelRunStep se ejecuta como un paso de las canalizaciones de Machine Learning. Es posible que quiera probar los scripts localmente como primer paso.
Requisitos del script de entrada
El script de entrada de una clase ParallelRunStepdebe contener una función run() y contiene, opcionalmente, una función init():
-
init(): utilice esta función en preparaciones costosas o comunes para el procesamiento posterior. Por ejemplo, para cargar el modelo en un objeto global. Solo se llama a esta función una vez al principio del proceso.Nota:
Si el método
initcrea un directorio de salida, especifique queparents=Trueyexist_ok=True. Al métodoinitse le llama desde cada proceso de trabajo en cada nodo en el que se ejecuta el trabajo. -
run(mini_batch): la función se ejecuta para cada instancia demini_batch.-
mini_batch:ParallelRunStepinvoca el método run y pasará una lista oDataFramede Pandas como argumento al método. Cada entrada de mini_batch puede ser una ruta de acceso de archivo si la entrada es unFileDataseto un pandasDataFramesi la entrada es unTabularDataset. -
response: El método run() debe devolverDataFramede Pandas o una matriz. Para append_row output_action, estos elementos devueltos se anexan al archivo de salida común. Para summary_only, se omite el contenido de los elementos. Para todas las acciones de salida, cada elemento de salida devuelto indica una ejecución correcta del elemento de entrada en el minilote de entrada. Asegúrese de que se incluyen suficientes datos en el resultado de la ejecución para asignar la entrada al resultado de la salida de la ejecución. Las salidas de ejecución se escriben en el archivo de salida y no se garantiza que estén en orden, debe usar alguna clave en la salida para asignarla a la entrada.Nota:
Se espera un elemento de salida para un elemento de entrada.
-
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Si tiene otro archivo o carpeta en el mismo directorio que el script de inferencia, puede hacer referencia a él buscando el directorio de trabajo actual. Si desea importar los paquetes, también puede anexar la carpeta del paquete a sys.path.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
packages_dir = os.path.join(file_path, '<your_package_folder>')
if packages_dir not in sys.path:
sys.path.append(packages_dir)
from <your_package> import <your_class>
Parámetros para ParallelRunConfig
ParallelRunConfig es la configuración principal de la instancia de ParallelRunStep dentro de la canalización de Azure Machine Learning. Se usa para encapsular el script y configurar los parámetros necesarios, incluidos los de las siguientes entradas:
entry_script: un script de usuario como ruta de acceso del archivo local que se va a ejecutar en paralelo en varios nodos. Sisource_directoryestá presente, se debe usar la ruta de acceso relativa. De lo contrario, use cualquier ruta de acceso accesible desde la máquina.mini_batch_size: tamaño del minilote que se pasa a una sola llamada derun(). (Opcional; el valor predeterminado es10archivos paraFileDataset, y1MBparaTabularDataset).- En el caso de
FileDataset, es el número de archivos con un valor mínimo de1. Puede combinar varios archivos en un solo minilote. - En el caso de
TabularDataset, es el tamaño de los datos. Los valores posibles son1024,1024KB,10MBy1GB.1MBes el valor recomendado. El minilote deTabularDatasetnunca cruzará los límites de los archivos. Por ejemplo, si hay varios archivos .csv con varios tamaños, el más pequeño es de 100 KB y el más grande es de 10 MB. Si se establecemini_batch_size = 1MB, los archivos menores de 1 MB se tratarán como un miniproceso y los archivos de más de 1 MB se dividirán en varios mini lotes.Nota:
TabularDatasets respaldados por SQL no se pueden crear particiones. TabularDatasets de un solo archivo parquet y un único grupo de filas no se pueden particionar.
- En el caso de
error_threshold: número de errores de registro paraTabularDatasety errores de archivo paraFileDatasetque se deben omitir durante el procesamiento. Una vez que el recuento de errores de toda la entrada supera este valor, se anula el trabajo. El umbral de error es para toda la entrada y no para los minilotes individuales que se envían al métodorun(). El intervalo es[-1, int.max].-1indica que se omiten todos los errores durante el procesamiento.output_action: uno de los valores siguientes indica cómo se organiza la salida:-
summary_only: el script de usuario debe almacenar los archivos de salida. Las salidas derun()solo se usan para el cálculo del umbral de error. -
append_row: para todas las entradas,ParallelRunStepcrea un único archivo en la carpeta de salida para anexar todas las salidas separadas por línea.
-
append_row_file_name: para personalizar el nombre del archivo de salida de append_row output_action (opcional; el valor predeterminado esparallel_run_step.txt).source_directory: rutas de acceso a las carpetas que contienen todos los archivos que se van a ejecutar en el destino de proceso (opcional).compute_target: Solo se admiteAmlCompute.node_count: número de nodos de proceso que se usarán para ejecutar el script de usuario.process_count_per_node: número de procesos de trabajo por nodo para ejecutar el script de entrada en paralelo. En el caso de una máquina de GPU, el valor predeterminado es 1. En una máquina de CPU, el valor predeterminado es el número de núcleos por nodo. Un proceso de trabajo llama arun()repetidamente pasando el mini lote que obtiene como parámetro. El número total de procesos de trabajo del trabajo esprocess_count_per_node * node_count, que decide el número máximo derun()que se van a ejecutar en paralelo.environment: definición del entorno de Python. Puede configurarla para usar un entorno de Python existente o un entorno temporal. La definición también es responsable de establecer las dependencias de la aplicación necesarias (opcional).logging_level: nivel de detalle del registro. Los valores con nivel de detalle en aumento son:WARNING,INFOyDEBUG. (Opcional; el valor predeterminado esINFO).run_invocation_timeout: tiempo de espera de invocación del métodorun()en segundos. (Opcional; el valor predeterminado es60).run_max_try: número máximo de intentos derun()para un minilote. Se produce un error enrun()si se genera una excepción o no se devuelve nada cuando se alcanzarun_invocation_timeout(opcional; el valor predeterminado es3).
Puede especificar mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout y run_max_try como PipelineParameter, de modo que, cuando vuelva a enviar una ejecución de la canalización, pueda optimizar los valores de los parámetros.
Visibilidad de dispositivos CUDA
En el caso de los destinos de proceso equipados con GPU, la variable de entorno CUDA_VISIBLE_DEVICES se establece en los procesos de trabajo. En AmlCompute, puede encontrar el número total de dispositivos GPU en la variable de entorno AZ_BATCHAI_GPU_COUNT_FOUND, que se establece automáticamente. Si desea que cada proceso de trabajo tenga una GPU dedicada, establezca process_count_per_node igual al número de dispositivos GPU de una máquina. A continuación, cada proceso de trabajo se asigna con un índice único para CUDA_VISIBLE_DEVICES. Cuando un proceso de trabajo se detiene por cualquier motivo, el siguiente proceso de trabajo iniciado adopta el índice de GPU publicado.
Cuando el número total de dispositivos GPU es menor que process_count_per_node, los procesos de trabajo con un índice de GPU más pequeño se pueden asignar hasta que se hayan ocupado todas las GPU.
Dado que el total de dispositivos GPU es 2 y process_count_per_node = 4 como ejemplo, el proceso 0 y el proceso 1 toma el índice 0 y 1. El proceso 2 y 3 no tiene la variable de entorno. Si una biblioteca usa esta variable de entorno para la asignación de GPU, los procesos 2 y 3 no tendrán GPU y no intentarán adquirir dispositivos de GPU. El proceso 0 libera el índice de GPU 0 cuando se detiene. El siguiente proceso, si procede, que es el proceso 4, tendrá asignado el índice de GPU 0.
Para más información, consulte CUDA Pro Tip: Control de la visibilidad de GPU con CUDA_VISIBLE_DEVICES.
Parámetros para crear ParallelRunStep
Cree ParallelRunStep mediante el script, la configuración del entorno y los parámetros. Especifique el destino de proceso que ya adjuntó a su área de trabajo como destino de ejecución del script de inferencia. Use ParallelRunStep para crear el paso de canalización de inferencias por lotes, que toma todos los parámetros siguientes:
-
name: el nombre del paso, con las siguientes restricciones de nomenclatura: unique, 3-32 caracteres y regex ^[a-z]([-a-z0-9]*[a-z0-9])?$. -
parallel_run_config: objetoParallelRunConfig, tal y como se definió anteriormente. -
inputs: uno o varios conjuntos de datos de Azure Machine Learning de tipo único que se van a particionar para el procesamiento en paralelo. -
side_inputs: uno o varios datos de referencia o conjuntos de datos que se usan como entradas laterales sin necesidad de crear particiones. -
output: Un objetoOutputFileDatasetConfigque representa la ruta de acceso del directorio en la que se deben almacenar los datos de salida. -
arguments: lista de los argumentos pasados al script de usuario. Use unknown_args para recuperarlos en el script de entrada (opcional). -
allow_reuse: sirve para decidir si el paso debe volver a usar los resultados anteriores cuando se ejecuta con la misma configuración o entrada. Si este parámetro esFalse, siempre se generará una nueva ejecución para este paso durante la ejecución de la canalización. (Opcional; el valor predeterminado esTrue).
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Depuración de scripts desde un contexto remoto
La transición de la depuración de un script de puntuación de forma local, a la depuración de un script de puntuación en una canalización real puede resultar difícil. Para información sobre cómo buscar los registros en el portal, consulte la sección de canalizaciones de aprendizaje automático en la depuración de scripts desde un contexto remoto. La información de esa sección también se aplica a ParallelRunStep.
Dada la naturaleza distribuida de los trabajos de ParallelRunStep, hay registros de distintos orígenes. Sin embargo, se crean dos archivos consolidados que proporcionan información de alto nivel:
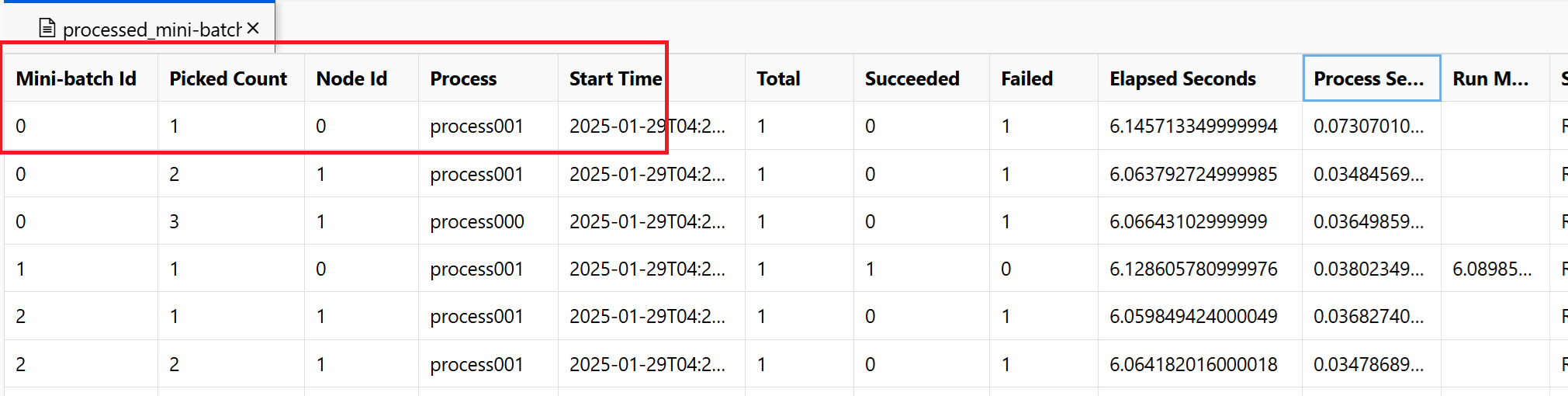
~/logs/job_progress_overview.txt: Este archivo proporciona información de alto nivel sobre el número de minilotes (también conocidos como tareas) que se han creado hasta el momento y el número de minilotes que se han procesado hasta ahora. En este extremo, se muestra el resultado del trabajo. Si se produce un error en el trabajo, muestra el mensaje de error y dónde iniciar la solución de problemas.~/logs/job_result.txt: muestra el resultado del trabajo. Si se produjo un error en el trabajo, muestra el mensaje de error y dónde iniciar la solución de problemas.~/logs/job_error.txt: este archivo resume los errores del script.~/logs/sys/master_role.txt: Este archivo proporciona la vista del nodo principal (también conocido como orquestador) del trabajo en ejecución. Incluye la creación de tareas, la supervisión del progreso y el resultado de la ejecución.~/logs/sys/job_report/processed_mini-batches.csv: una tabla de todos los minilotes que se procesaron. Muestra el resultado de cada ejecución de minilote, su identificador de nodo del agente de ejecución y el nombre del proceso. Además, se incluyen el tiempo transcurrido y los mensajes de error. Los registros de cada ejecución de minilotes se pueden encontrar siguiendo el identificador de nodo y el nombre del proceso.
Los registros generados a partir del script de entrada mediante el asistente entryScript y las instrucciones de impresión se pueden encontrar en los archivos siguientes:
~/logs/user/entry_script_log/<node_id>/<process_name>.log.txt: estos archivos son los registros escritos desde entry_script con el asistente EntryScript.~/logs/user/stdout/<node_id>/<process_name>.stdout.txt: estos archivos son los registros de stdout (por ejemplo, la instrucción print) de entry_script.~/logs/user/stderr/<node_id>/<process_name>.stderr.txt: estos archivos son los registros de stderr de entry_script.
Por ejemplo, el recorte de pantalla muestra que el minilote 0 produjo un error en el nodo 0 process001. Los registros correspondientes para el script de entrada se pueden encontrar en ~/logs/user/entry_script_log/0/process001.log.txt, ~/logs/user/stdout/0/process001.log.txt y ~/logs/user/stderr/0/process001.log.txt
Cuando necesite comprender en detalle cómo ejecuta cada nodo el script de puntuación, examine los registros de proceso individuales para cada nodo. Los registros de proceso se pueden encontrar en la carpeta ~/logs/sys/node, agrupados por nodos de trabajo:
~/logs/sys/node/<node_id>/<process_name>.txt: este archivo proporciona información detallada acerca de cada minilote que un trabajador ha recogido o completado. Para cada minilote, este archivo incluye:- La dirección IP y el PID del proceso de trabajo.
- El número total de elementos, el número de elementos procesados correctamente y el número de elementos con errores.
- Hora de inicio, duración, tiempo de proceso y tiempo del método de ejecución.
También puede ver los resultados de las comprobaciones periódicas del uso de recursos de cada nodo. Los archivos de registro y los archivos de configuración se encuentran en esta carpeta:
~/logs/perf: establezca--resource_monitor_intervalpara cambiar el intervalo de comprobación en segundos. El intervalo predeterminado es600, que son aproximadamente 10 minutos. Para detener la supervisión, establezca el valor en0. Cada carpeta<node_id>incluye:-
os/: información acerca de todos los procesos en ejecución en el nodo. Una comprobación ejecuta un comando del sistema operativo y guarda el resultado en un archivo. En Linux, el comando esps. Para Windows, usetasklist.-
%Y%m%d%H: el nombre de la subcarpeta es la fecha y hora.-
processes_%M: el archivo finaliza con el minuto de la hora de la comprobación.
-
-
-
node_disk_usage.csv: detalles de uso del disco del nodo. -
node_resource_usage.csv: información general sobre el uso de recursos del nodo. -
processes_resource_usage.csv: información general sobre el uso de recursos de cada proceso.
-
Motivos comunes del error del trabajo
SystemExit: 42
Las salidas 41 y 42 son códigos de salida diseñados de PRS. Los nodos de trabajo salen con 41 para notificar al administrador de procesos que finalizó de forma independiente. Este es el comportamiento esperado. Un nodo líder puede salir con 0 o 42, lo que indica el resultado del trabajo. La salida 42 significa que se produjo un error en el trabajo. El motivo del error se puede encontrar en ~/logs/job_result.txt. Puede seguir la sección anterior para depurar el trabajo.
Permiso de datos
El error del trabajo indica que el proceso no puede acceder a los datos de entrada. Si se usa la identidad basada en identidades para el clúster de proceso y el almacenamiento, puede consultar Autenticación de datos basada en identidad.
Procesos finalizados inesperadamente
Los procesos pueden bloquearse debido a excepciones inesperadas o no controladas, el sistema elimina los procesos debido a excepciones de memoria insuficiente. En los registros del sistema PRS ~/logs/sys/node/<node-id>/_main.txt, se pueden encontrar errores como los siguientes.
<process-name> exits with returncode -9.
Memoria insuficiente
~/logs/perf registra el consumo de recursos de cálculo de los procesos. Se puede encontrar el uso de memoria de cada procesador de tareas. Puede calcular el uso total de memoria en el nodo.
Error de memoria insuficiente en ~/system_logs/lifecycler/<node-id>/execution-wrapper.txt.
Sugerimos reducir el número de procesos por nodo o aumentar el tamaño de la máquina virtual si los recursos de proceso están cerca de los límites.
Excepciones no controladas
En algunos casos, los procesos de Python no pueden detectar la pila con errores. Puede agregar una variable de entorno env["PYTHONFAULTHANDLER"]="true" para habilitar el controlador de errores integrado de Python.
Tiempo de espera de minilote
Puede ajustar run_invocation_timeout argumento según las tareas de minilote. Cuando vea que las funciones run() tardan más tiempo de lo esperado, estas son algunas sugerencias.
Compruebe el tiempo transcurrido y el tiempo de proceso del minilote. El tiempo del proceso mide el tiempo de CPU del proceso. Cuando el tiempo de proceso es significativamente menor que el transcurrido, puede comprobar si hay algunas operaciones de E/S pesadas o solicitudes de red en las tareas. La latencia larga de esas operaciones es la razón común del tiempo de espera de minilote.
Algunos minilotes específicos tardan más tiempo que otros. Puede actualizar la configuración o intentar trabajar con datos de entrada para equilibrar el tiempo de procesamiento del minilote.
¿Cómo me puedo registrar desde mi script de usuario en un contexto remoto?
ParallelRunStep puede ejecutar varios procesos en un nodo basado en process_count_per_node. Con el fin de organizar los registros de cada proceso en el nodo y combinar la impresión y la declaración de registro, se recomienda el registrador ParallelRunStep como se indica a continuación. Puede obtener un registrador de EntryScript, y hacer que los registros aparezcan en la carpeta logs/user del portal.
Uso del registrador por un script de entrada de ejemplo:
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
logger = entry_script.logger
logger.info("This will show up in files under logs/user on the Azure portal.")
def run(mini_batch):
"""Call once for a mini batch. Accept and return the list back."""
# This class is in singleton pattern. It returns the same instance as the one in init()
entry_script = EntryScript()
logger = entry_script.logger
logger.info(f"{__file__}: {mini_batch}.")
...
return mini_batch
¿Dónde se recibe el mensaje logging de Python?
ParallelRunStep establece un controlador en el registrador raíz, que recibe el mensaje en logs/user/stdout/<node_id>/processNNN.stdout.txt.
El valor predeterminado de logging es el nivel INFO. De manera predeterminada, los niveles por debajo de INFO no se mostrarán, como DEBUG.
¿Cómo puedo escribir en un archivo para que aparezca en el portal?
Los archivos escritos en /logs carpeta se cargarán y se mostrarán en el portal.
Puede obtener la carpeta logs/user/entry_script_log/<node_id> como se muestra a continuación y crear la ruta de acceso del archivo para escribir:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
log_dir = entry_script.log_dir
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
fil_path = log_dir / f"{proc_name}_<file_name>" # Avoid conflicting among worker processes with proc_name.
¿Cómo controlar el registro en nuevos procesos?
Puede generar nuevos procesos en el script de entrada con el módulo subprocess, conectarse a sus canalizaciones de entrada, salida o error y obtener sus códigos de retorno.
El enfoque recomendado es usar la función run() con capture_output=True. Los errores aparecen en logs/user/error/<node_id>/<process_name>.txt.
Si desea usar Popen(), stdout/stderr debe redirigirse a los archivos, como:
from pathlib import Path
from subprocess import Popen
from azureml_user.parallel_run import EntryScript
def init():
"""Show how to redirect stdout/stderr to files in logs/user/entry_script_log/<node_id>/."""
entry_script = EntryScript()
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
stdout_file = str(log_dir / f"{proc_name}_demo_stdout.txt")
stderr_file = str(log_dir / f"{proc_name}_demo_stderr.txt")
proc = Popen(
["...")],
stdout=open(stdout_file, "w"),
stderr=open(stderr_file, "w"),
# ...
)
Nota:
Un proceso de trabajo ejecuta el código "system" y el código de script de entrada en el mismo proceso.
Si no se especifica ningún stdout o stderr, los subprocesos creados con Popen() en el script de entrada heredarán la configuración del proceso de trabajo.
stdout escribe en ~/logs/sys/node/<node_id>/processNNN.stdout.txt y stderr en ~/logs/sys/node/<node_id>/processNNN.stderr.txt.
¿Cómo se escribe un archivo en el directorio de salida y se ve luego en el portal?
Puede obtener el directorio de salida de EntryScript clase y escribir en él. Para ver los archivos escritos, en el paso Ejecutar vista del portal de Azure Machine Learning, seleccione la pestaña Resultados y registros. Elija el vínculo Data outputs (Resultados de datos) y, luego, complete los pasos que se describen en el cuadro de diálogo.
Use EntryScript en el script de entrada, como en este ejemplo:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def run(mini_batch):
output_dir = Path(entry_script.output_dir)
(Path(output_dir) / res1).write...
(Path(output_dir) / res2).write...
¿Cómo puedo pasar una entrada lateral, como un archivo o archivos que contienen una tabla de búsqueda, a todos mis trabajadores?
El usuario puede pasar datos de referencia al script mediante el parámetro side_inputs de ParalleRunStep. Todos los conjuntos de datos proporcionados como side_inputs se montan en cada nodo de trabajo. El usuario puede obtener la ubicación del montaje pasando el argumento.
Construya un conjunto de datos que contenga los datos de referencia, especifique una ruta de acceso de montaje local y regístrelo con su área de trabajo. Páselo al parámetro side_inputs de ParallelRunStep. Además, puede agregar su ruta de acceso en la sección arguments para acceder fácilmente a su ruta de acceso montada.
Nota
Use FileDatasets solo para side_inputs.
local_path = "/tmp/{}".format(str(uuid.uuid4()))
label_config = label_ds.as_named_input("labels_input").as_mount(local_path)
batch_score_step = ParallelRunStep(
name=parallel_step_name,
inputs=[input_images.as_named_input("input_images")],
output=output_dir,
arguments=["--labels_dir", label_config],
side_inputs=[label_config],
parallel_run_config=parallel_run_config,
)
Después de ello, puede acceder a él en el script (por ejemplo, en el método init() como se indica a continuación:
parser = argparse.ArgumentParser()
parser.add_argument('--labels_dir', dest="labels_dir", required=True)
args, _ = parser.parse_known_args()
labels_path = args.labels_dir
¿Cómo se usan los conjuntos de datos de entrada con la autenticación de entidad de servicio?
El usuario puede pasar conjuntos de datos de entrada con la autenticación de entidad de servicio usada en el área de trabajo. El uso de un conjunto de datos de este tipo en ParallelRunStep requiere que se registre el conjunto para que construya la configuración de ParallelRunStep.
service_principal = ServicePrincipalAuthentication(
tenant_id="***",
service_principal_id="***",
service_principal_password="***")
ws = Workspace(
subscription_id="***",
resource_group="***",
workspace_name="***",
auth=service_principal
)
default_blob_store = ws.get_default_datastore() # or Datastore(ws, '***datastore-name***')
ds = Dataset.File.from_files(default_blob_store, '**path***')
registered_ds = ds.register(ws, '***dataset-name***', create_new_version=True)
Comprobación y análisis del progreso
En esta sección se explica cómo comprobar el progreso de un trabajo ParallelRunStep y la causa de un comportamiento inesperado.
¿Cómo se comprueba el progreso del trabajo?
Además de consultar el estado general de StepRun, el recuento de lotes de pequeño tamaño programados o procesados y el progreso de la generación de salida se pueden ver en ~/logs/job_progress_overview.<timestamp>.txt. El archivo gira diariamente. Puede comprobar la que tiene la marca de tiempo más grande para obtener la información más reciente.
¿Qué debo comprobar si no hay progreso durante un tiempo?
Puede ir a ~/logs/sys/error para ver si hay alguna excepción. Si no hay ninguno, es probable que el script de entrada esté tardando mucho tiempo, puede imprimir información de progreso en el código para buscar el elemento que consume mucho tiempo o agregar "--profiling_module", "cProfile" a la arguments de ParallelRunStep para generar un archivo de perfil denominado como <process_name>.profile en ~/logs/sys/node/<node_id> carpeta.
¿Cuándo se detiene un trabajo?
Si no se cancela, el trabajo puede detenerse con el estado :
- Completed. Todos los miniprocesos se procesan correctamente y la salida se genera para el modo
append_row. - Failed. Si
error_thresholdenParameters for ParallelRunConfigse supera o se produce un error del sistema durante el trabajo.
¿Dónde se encuentra la causa principal del error?
Puede seguir el ejemplo de ~/logs/job_result.txt para encontrar la causa y el registro de errores detallado.
¿Afectará el error del nodo al resultado del trabajo?
No, si hay otros nodos disponibles en el clúster de proceso designado. ParallelRunStep se puede ejecutar independientemente en cada nodo. El error de nodo único no produce un error en todo el trabajo.
¿Qué ocurre si la función init del script de entrada produce un error?
ParallelRunStep tiene un mecanismo para reintentarlo un número determinado de veces a fin de dar la oportunidad de recuperarse de problemas transitorios sin retrasar el error del trabajo durante demasiado tiempo. El mecanismo es el siguiente:
- Si después de que se inicia un nodo,
initsigue produciendo errores en todos los agentes, dejaremos de intentarlo después de3 * process_count_per_nodeerrores. - Si después de iniciar el trabajo,
initsigue produciendo errores en todos los agentes de todos los nodos, dejaremos de intentarlo si el trabajo se ejecuta más de 2 minutos y hay2 * node_count * process_count_per_nodeerrores. - Si todos los agentes se bloquean en
initdurante más de3 * run_invocation_timeout + 30segundos, se producirá un error en el trabajo debido a que no hay progreso durante demasiado tiempo.
¿Qué ocurre en OutOfMemory? ¿Cómo puedo comprobar la causa?
El sistema puede terminar el proceso. ParallelRunStep establece el intento actual de procesar el minilote al estado de error e intenta reiniciar el proceso con errores. Puede comprobar ~logs/perf/<node_id> para encontrar el proceso de consumo de memoria.
¿Por qué tengo muchos archivos processNNN?
ParallelRunStep inicia nuevos procesos de trabajo en reemplazo de los que se han salido de forma anormal. Y cada proceso genera un conjunto de archivos processNNN como registro. Sin embargo, si se produjo un error en el proceso debido a una excepción durante la función init del script de usuario y ese error se repitió continuamente durante 3 * process_count_per_node veces, no se iniciará ningún nuevo proceso de trabajo.
Pasos siguientes
Consulte estos cuadernos de Jupyter Notebook que muestran canalizaciones de Azure Machine Learning.
Vea la referencia del SDK para obtener ayuda con el paquete azureml-pipeline-steps.
Vea la documentación de referencia de la clase ParallelRunConfig y la documentación para la clase ParallelRunStep.
Realice el tutorial avanzado sobre cómo usar canalizaciones con ParallelRunStep. En este tutorial se explica cómo pasar otro archivo como entrada lateral.