Configurar un proyecto de etiquetado de texto y exportación de etiquetas
En Azure Machine Learning, aprenda a crear y ejecutar proyectos de etiquetado de datos para etiquetar datos de texto. Especifique una o varias etiquetas para aplicarlas a cada elemento de texto.
También puede usar la herramienta de etiquetado de datos de Azure Machine Learning para crear un proyecto de etiquetado de imágenes.
Funcionalidades del etiquetado de texto
El etiquetado de datos de Azure Machine Learning es una herramienta que puede usar para crear, administrar y supervisar proyectos de etiquetado de datos. Utilícelo para:
- Coordine los datos, las etiquetas y los miembros del equipo para administrar de forma eficaz las tareas de etiquetado.
- Realización de un seguimiento del progreso y mantenimiento de la cola de tareas de etiquetado incompletas.
- Inicio y detención del proyecto, y control del progreso de etiquetado.
- Examen y exportación de los datos etiquetados como un conjunto de datos de Azure Machine Learning.
Importante
Los datos de texto con los que trabaja en la herramienta de etiquetado de datos de Azure Machine Learning deben estar disponibles en un almacén de datos de Azure Blob Storage. Si aún no tiene un almacén de datos, puede cargar los archivos de datos en un nuevo almacén de datos en el momento que cree un proyecto.
Estos formatos de datos están disponibles para datos de texto:
- TXT: cada archivo representa un elemento que se va a etiquetar.
- CSV o TSV: cada fila representa un elemento que presenta el etiquetador. Decida qué columnas puede ver el etiquetador cuando etiqueta la fila.
Requisitos previos
Estos elementos se usan para configurar el etiquetado de texto en Azure Machine Learning:
- Los datos que quiere etiquetar, ya sea en archivos locales o en Azure Blob Storage.
- Conjunto de etiquetas que quiere aplicar.
- Instrucciones para el etiquetado.
- Suscripción a Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
- Un área de trabajo de Azure Machine Learning. Consulte Creación de un área de trabajo de Azure Machine Learning.
Creación de un proyecto de etiquetado de texto
Los proyectos de etiquetado se administran en Azure Machine Learning. Use la página Etiquetado de datos de Machine Learning para administrar los proyectos.
Si los datos ya están en Azure Blob Storage, asegúrese de que están disponibles como un almacén de datos antes de crear el proyecto de etiquetado.
Para crear un proyecto, seleccione Agregar proyecto.
En Nombre del proyecto, escriba un nombre para el proyecto.
No puede volver a usar el mismo nombre del proyecto, aunque elimine el proyecto.
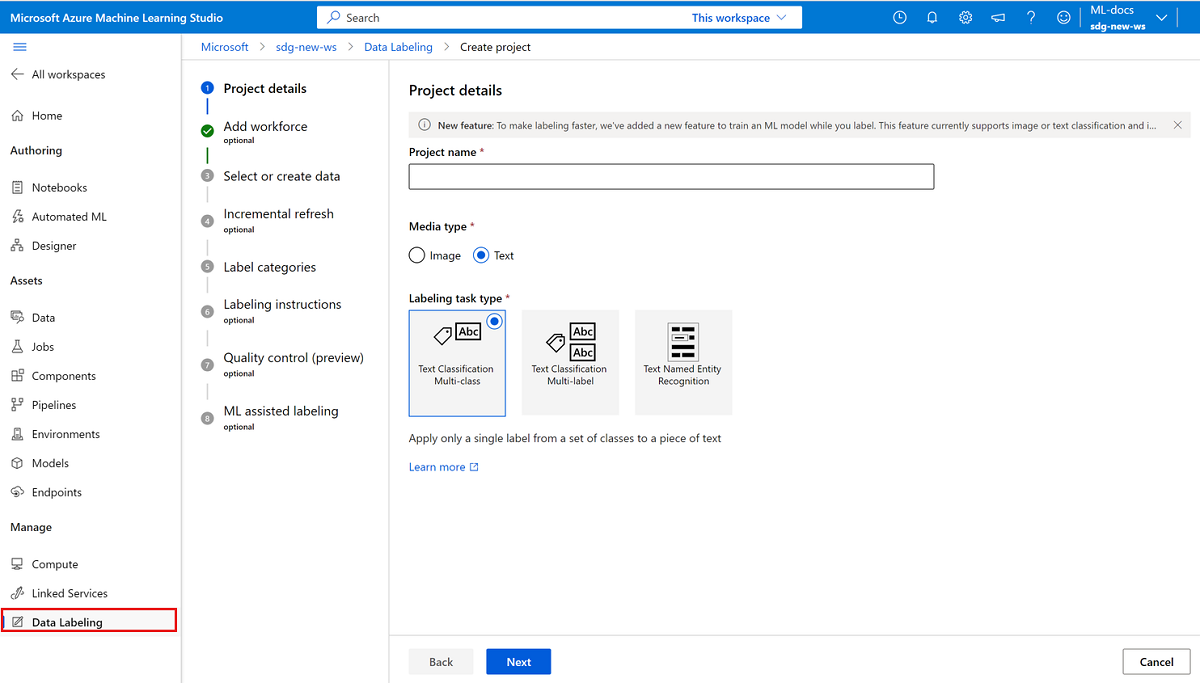
Para crear un proyecto de etiquetado de texto, en Tipo de medio, seleccione Texto.
En Etiquetado de tipos de tareas, seleccione una opción para su caso:
- Para aplicar solo una etiqueta única de un conjunto de etiquetas a cada fragmento de texto, seleccione Clasificación de texto de varias clases.
- Para aplicar una o más etiquetas de un conjunto de etiquetas a cada fragmento de texto, seleccione Clasificación de texto de varias clases.
- Para aplicar etiquetas a palabras de texto individuales o a varias palabras de texto en cada entrada, seleccione Reconocimiento de texto de entidades con nombre.
Seleccione Next (Siguiente) para continuar.
Agregar recursos (opcional)
Seleccione Usar una empresa proveedora de etiquetado de Azure Marketplace solo si ha interactuado con una empresa de etiquetado de datos de Azure Marketplace. A continuación, seleccione el proveedor. Si el proveedor no aparece en la lista, borre esta opción.
Asegúrese de ponerse en contacto primero con el proveedor y firmar un contrato. Para obtener más información, vea Trabajar con una empresa proveedora de etiquetado de datos (versión preliminar).
Seleccione Next (Siguiente) para continuar.
Selección o creación de un conjunto de datos
Si ya ha creado un conjunto de datos que contiene los datos, selecciónelo en la lista desplegable Seleccione un conjunto de datos existente. También puede seleccionar Crear un conjunto de datos para usar un almacén de información de Azure existente o cargar archivos locales.
Nota
Un proyecto no puede contener más de 500 000 archivos. Si el conjunto de datos supera este número de archivos, solo se cargarán los primeros 500 000 archivos.
Creación de un conjunto de datos a partir de un almacén de datos de Azure
En muchos casos, puede cargar archivos locales. Sin embargo, Explorador de Azure Storage es una forma más rápida y eficaz de transferir una gran cantidad de datos. Se recomienda usar Explorador de Storage de forma predeterminada para migrar archivos.
Para crear un conjunto de datos a partir de los datos que ya ha almacenado en Blob Storage:
- Seleccione Crear.
- En Nombre, escriba un nombre para el conjunto de datos. Si lo desea, escriba una descripción.
- Elija el Tipo de conjunto de datos:
- Si usa un archivo CSV o TSV y cada fila contiene una respuesta, seleccione Tabular.
- Si usa archivos TXT para cada respuesta, seleccione Archivo.
- Seleccione Next (Siguiente).
- Seleccione Desde Azure Storage y, después, Siguiente.
- Seleccione el almacén de datos y, a continuación, seleccione Siguiente.
- Si los datos están en una subcarpeta del Blob Storage, elija Examinar para seleccionar la ruta de acceso.
- Para incluir todos los archivos que haya en las subcarpetas de la ruta de acceso seleccionada, anexe
/**a la ruta. - Para incluir todos los datos que haya en el contenedor actual y sus subcarpetas, anexe
**/*.*a la ruta.
- Para incluir todos los archivos que haya en las subcarpetas de la ruta de acceso seleccionada, anexe
- Seleccione Crear.
- Seleccione el recurso de datos que ha creado.
Creación de un conjunto de datos a partir de los datos cargados
Para cargar los datos directamente:
- Seleccione Crear.
- En Nombre, escriba un nombre para el conjunto de datos. Si lo desea, escriba una descripción.
- Elija el Tipo de conjunto de datos:
- Si usa un archivo CSV o TSV y cada fila contiene una respuesta, seleccione Tabular.
- Si usa archivos TXT para cada respuesta, seleccione Archivo.
- Seleccione Next (Siguiente).
- Seleccione Desde archivos locales y, a continuación, seleccione Siguiente.
- (Opcional) Seleccione un almacén de datos. Por defecto, carga al almacén predeterminado de blob (workspaceblobstore) del área de trabajo de Machine Learning.
- Seleccione Next (Siguiente).
- Seleccione Cargar>Cargar archivos o Cargar>Cargar carpeta para seleccionar los archivos o carpetas locales que quiera cargar.
- Busque los archivos o la carpeta en la ventana del explorador y, a continuación, seleccione Abrir.
- Después, seleccione Cargar hasta que tenga todos los archivos o carpetas.
- Opcionalmente, active la casilla Sobrescribir si los archivos ya existen. Compruebe la lista de archivos y carpetas.
- Seleccione Next (Siguiente).
- Confirme los detalles. Seleccione Atrás para modificar la configuración o Crear para crear el conjunto de datos.
- Por último, seleccione el recurso de datos que ha creado.
Configuración de la actualización incremental
Si tiene pensado agregar nuevos archivos al conjunto de datos, utilice la actualización incremental para agregarlos al proyecto.
Cuando se configura Habilitar la actualización incremental a intervalos regulares, el conjunto de datos se comprueba periódicamente para agregar nuevos archivos a un proyecto en función de la velocidad de finalización del etiquetado. La comprobación de los nuevos datos se detiene cuando el proyecto alcanza el número máximo de 500 000 archivos.
Active Habilitar la actualización incremental a intervalos regulares cuando desee que el proyecto supervise continuamente los nuevos datos del almacén de datos.
Borre la selección si no quiere que los nuevos archivos del almacén de datos se agreguen automáticamente al proyecto.
Importante
Cuando esté habilitada la actualización incremental, no cree una nueva versión para el conjunto de datos que quiere actualizar. Si lo hace, no se verán las actualizaciones, puesto que el proyecto de etiquetado de datos se ancla a la versión inicial. En su lugar, use el Explorador de Azure Storage para modificar los datos en la carpeta adecuada de Blob Storage.
Además, no quite los datos. Eliminar datos del conjunto de datos que usa el proyecto provocará un error en el proyecto.
Una vez creado el proyecto, use la pestaña Detalles para cambiar la actualización incremental, ver la marca de tiempo de la última actualización y solicitar una actualización inmediata de los datos.
Nota
Los proyectos que usan la entrada de conjuntos de datos tabulares (CSV o TSV) podrán usar la actualización incremental. Pero la actualización incremental solo agrega nuevos archivos tabulares. La actualización no reconoce los cambios en los archivos tabulares existentes.
Especificar categorías de etiquetas
En la página Categorías de etiquetas, especifique un conjunto de clases para clasificar los datos.
La precisión y velocidad de los etiquetadores resultan afectadas por su capacidad para elegir entre las clases. Por ejemplo, en lugar de deletrear el género y la especie completos para plantas o animales, use códigos de campo o abrevie el género.
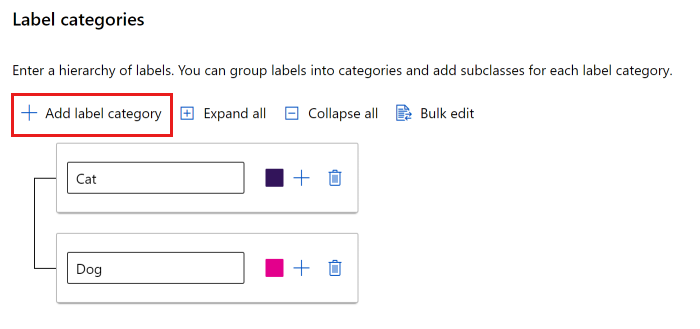
Puede usar una lista plana o crear grupos de etiquetas.
Para crear una lista plana, seleccione Añadir categoría de etiqueta para crear cada etiqueta.
Para crear etiquetas en distintos grupos, seleccione Añadir categoría de etiqueta para crear las etiquetas de nivel superior. Después, seleccione el siglo más (+) en cada nivel superior a fin de crear el siguiente nivel de etiquetas para esa categoría. Puede crear hasta seis niveles para cualquier agrupación.
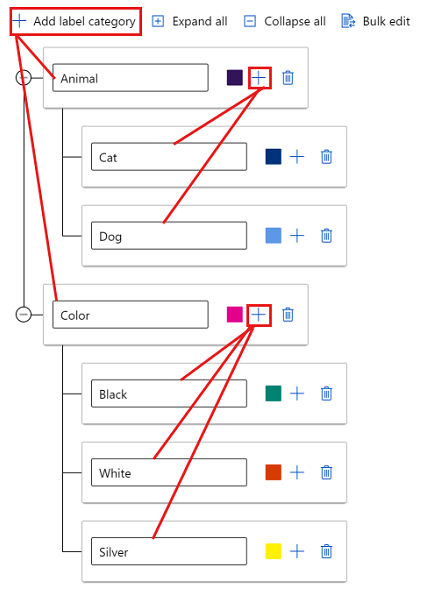
Se pueden seleccionar las etiquetas de cualquier nivel durante el proceso de etiquetado. Por ejemplo, las etiquetas Animal, Animal/Cat, Animal/Dog, Color, Color/Black, Color/White y Color/Silver son todas opciones disponibles para una etiqueta. En un proyecto con varias etiquetas, no es necesario elegir una de cada categoría. Pero si es lo que intenta, asegúrese de incluir esta información en las instrucciones.
Descripción de la tarea de etiquetado de texto
Es importante explicar claramente la tarea de etiquetado. En la página Instrucciones de etiquetado, puede agregar un vínculo a un sitio externo que contenga las instrucciones de etiquetado o bien incluir instrucciones en el cuadro de edición de la página. Mantenga las instrucciones orientadas a tareas y adecuadas para el público. Tenga en cuenta estas preguntas:
- ¿Cuáles son las etiquetas que verán los etiquetadores y cómo las elegirán? ¿Hay un texto de referencia que puedan consultar?
- ¿Qué debe hacer si ninguna etiqueta parece adecuada?
- ¿Qué debe hacer si varias etiquetas parecen adecuadas?
- ¿Qué umbral de confianza debe aplicarse a una etiqueta? ¿Quiere que los etiquetadores usen una conjetura si no están seguros?
- ¿Qué debe hacer con los objetos de interés ocluidos o superpuestos?
- ¿Qué debe hacer si un objeto de interés se corta con el borde de la imagen?
- ¿Qué deben hacer si, después de enviar una etiqueta, creen que han cometido un error?
- ¿Qué hay que hacer si detectan problemas de calidad de imagen, como condiciones de iluminación deficientes, reflejos, pérdida de enfoque, fondos no deseados incluidos o ángulos anómalos de cámara, entre otros?
- ¿Qué deben hacer si varios revisores tienen opiniones diferentes sobre cómo aplicar una etiqueta?
Nota
Los etiquetadores pueden seleccionar las nueve primeras etiquetas usando el teclado numérico del 1 a 9.
Control de calidad (versión preliminar)
Para obtener etiquetas más precisas, use la página Control de calidad para enviar cada elemento a varios etiquetadores.
Importante
El etiquetado de consenso se encuentra actualmente en versión preliminar pública.
Se ofrece la versión preliminar sin Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Para que cada elemento se envíe a varios etiquetadores, seleccione Habilitar etiquetado de consenso (versión preliminar). A continuación, establezca los etiquetadores mínimos y máximos para especificar cuántos etiquetadores usar. Asegúrese de que tiene tantos etiquetadores disponibles como el número máximo especificado. No se puede cambiar más adelante esta configuración una vez que se haya iniciado el proyecto.
Si se alcanza un consenso desde el número mínimo de etiquetadores, se etiqueta el elemento. Si no se llega a un consenso, el elemento se envía a más etiquetadores. Si no existe un consenso después de que el elemento pase por el número máximo de etiquetadores, su estado será Necesita revisión y el propietario del proyecto será responsable de etiquetar el elemento.
Uso del etiquetado de datos asistido por Machine Learning
Para acelerar la tarea de etiquetado, la página Etiquetado asistido por ML permite desencadenar automáticamente modelos de aprendizaje automático. El etiquetado asistido por aprendizaje automático (ML) puede administrar tanto las entradas de datos de texto de archivos (TXT) como las tabulares (CSV).
Para usar el etiquetado asistido por ML:
- Seleccione la opción de habilitar el etiquetado asistido por ML.
- Seleccione el lenguaje del conjunto de datos para el proyecto. En esta lista se muestran todos los idiomas que admite la clase TextDNNLanguages.
- Especifique un destino de proceso que se usará. Si no tiene un destino de proceso en el área de trabajo, este paso crea un clúster de proceso y lo agrega al área de trabajo. El clúster se crea con un mínimo de cero nodos, lo que significa que no cuesta nada cuando no está en uso.
Más información sobre el etiquetado asistido por aprendizaje automático (ML)
Al principio del proyecto de etiquetado, los elementos se presentan en orden aleatorio para reducir el posible sesgo. Sin embargo, el modelo entrenado refleja los sesgos presentes en el conjunto de datos. Por ejemplo, si el 80 por ciento de los elementos son de una sola clase, aproximadamente el 80 por ciento de los datos que se usan para entrenar el modelo serán de esa clase.
Para entrenar el modelo DNN de texto que utiliza el etiquetado asistido por ML, el texto de entrada por ejemplo de entrenamiento se limita aproximadamente a las primeras 128 palabras del documento. Para la entrada tabular, todas las columnas de texto se concatenan antes de aplicar este límite. Este límite práctico permite que el entrenamiento del modelo se complete en un período de tiempo razonable. El texto real de un documento (para la entrada de archivo) o el conjunto de columnas de texto (para la entrada tabular) puede superar las 128 palabras. El límite se aplica solo a lo que el modelo usa internamente durante el proceso de entrenamiento.
El número de elementos etiquetados que son necesarios para iniciar el etiquetado asistido no es un número fijo. Este número puede variar considerablemente de un proyecto de etiquetado a otro. La varianza depende de muchos factores, incluido el número de clases de etiqueta y la distribución de etiquetas.
Cuando se usa el etiquetado de consenso, se usa la etiqueta de consenso para el entrenamiento.
Dado que las etiquetas finales se siguen basando en la entrada del etiquetador, a veces esta tecnología se denomina etiquetado con intervención humana.
Nota
El etiquetado de datos asistido por ML no es compatible con las cuentas de almacenamiento predeterminadas que están protegidas en una red virtual. Debe usar una cuenta de almacenamiento no predeterminada para el etiquetado de datos asistidos por ML. La cuenta de almacenamiento no predeterminada se puede proteger en la red virtual.
Etiquetado previo
Después de enviar suficientes etiquetas para el entrenamiento, el modelo entrenado se usa para predecir etiquetas. Ahora el etiquetador ve las páginas que muestran las etiquetas predichas ya presentes en cada elemento. La tarea implica revisar estas predicciones y corregir los elementos etiquetados de forma incorrecta antes del envío de la página.
Después de entrenar el modelo de Machine Learning en los datos etiquetados manualmente, el modelo se evalúa en un conjunto de prueba de elementos etiquetados manualmente. La evaluación ayuda a determinar la precisión del modelo en distintos umbrales de confianza. El proceso de evaluación determina un umbral de confianza más allá del cual el modelo es lo suficientemente preciso como para mostrar las etiquetas previas. A continuación, el modelo se evalúa con datos sin etiquetar. Los elementos que tienen predicciones más seguras que el umbral se usan para el etiquetado previo.
Inicialización del proyecto de etiquetado de texto
Una vez inicializado el proyecto de etiquetado, algunos aspectos del proyecto son inmutables. No se puede cambiar el tipo de tarea ni el conjunto de datos. Se pueden modificar las etiquetas y la dirección URL de la descripción de la tarea. Repase atentamente la configuración antes de crear el proyecto. Después de enviar el proyecto, vuelva a la página de información general etiquetado de datos, que muestra el proyecto como Inicialización.
Nota:
Es posible que la página de información general no se actualice automáticamente. Espere un momento y actualice la página manualmente para ver el estado del proyecto como Creado.
Solución de problemas
Para obtener problemas al crear un proyecto o acceder a los datos, vea Solución de problemas de etiquetado de datos.