Autorización en puntos de conexión por lotes
Los puntos de conexión de Batch admiten la autenticación de Microsoft Entra o aad_token. Esto significa que para poder invocar un punto de conexión por lotes, el usuario debe presentar un token de autenticación válido de Microsoft Entra al URI del punto de conexión por lotes. La autorización se aplica en el nivel de punto de conexión. En el siguiente artículo se explica cómo interactuar correctamente con los puntos de conexión por lotes y los requisitos de seguridad para ello.
Funcionamiento de la autorización
Para poder invocar un punto de conexión por lotes, el usuario debe presentar un token válido de Microsoft Entra que represente una entidad de seguridad. Esta entidad de seguridad puede ser una entidad de seguridad de usuario o una entidad de servicio. En cualquier caso, una vez invocado un punto de conexión, se crea un trabajo de implementación por lotes en la identidad asociada al token. La identidad necesita los siguientes permisos para crear correctamente un trabajo:
- Leer puntos de conexión o implementaciones por lotes.
- Crear trabajos en puntos de conexión o implementación de inferencia por lotes.
- Crear experimentos/ejecuciones.
- Leer y escribir desde/hacia los almacenes de datos.
- Enumerar los secretos del almacén de datos.
Consulte Configuración de RBAC para la invocación de puntos de conexión por lotes para obtener una lista detallada de los permisos de RBAC.
Importante
Es posible que la identidad utilizada para invocar un punto de conexión por lotes no se use para leer los datos subyacentes dependiendo de cómo esté configurado el almacén de datos. Consulte Configuración de clústeres de proceso para el acceso a datos para obtener más detalles.
Ejecución de trabajos con diferentes tipos de credenciales
En los ejemplos siguientes se muestran diferentes formas de iniciar trabajos de implementación por lotes mediante distintos tipos de credenciales:
Importante
Al trabajar en áreas de trabajo habilitadas para vínculo privado, los puntos de conexión por lotes no se pueden invocar desde la interfaz de usuario de Estudio de Azure Machine Learning. En su lugar, use la CLI v2 de Azure Machine Learning para la creación de trabajos.
Requisitos previos
- En este ejemplo se supone que usted tiene un modelo implementado correctamente como punto de conexión por lotes. En particular, estamos usando el clasificador de enfermedades cardíacas creado en el tutorial Uso de modelos de MLflow en implementaciones por lotes.
Ejecución de trabajos mediante las credenciales del usuario
En este caso, queremos ejecutar un punto de conexión por lotes mediante la identidad del usuario que ha iniciado sesión actualmente. Siga estos pasos:
Use la CLI de Azure para iniciar sesión mediante la autenticación interactiva o de código de dispositivo:
az loginUna vez autenticado, use el siguiente comando para ejecutar un trabajo de implementación por lotes:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Ejecución de trabajos mediante una entidad de servicio
En este caso, queremos ejecutar un punto de conexión por lotes utilizando una entidad de seguridad de servicio ya creada en Microsoft Entra ID. Para completar la autenticación, tendrás que crear un secreto para realizar la autenticación. Siga estos pasos:
Cree un secreto para usarlo en la autenticación, tal como se explica en Opción 3: Crear un nuevo secreto de cliente.
Para autenticarse mediante una entidad de servicio, usa el siguiente comando. Para obtener más detalles, consulte Inicio de sesión con la CLI de Azure.
az login --service-principal \ --tenant <tenant> \ -u <app-id> \ -p <password-or-cert>Una vez autenticado, use el siguiente comando para ejecutar un trabajo de implementación por lotes:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/
Ejecución de trabajos mediante una identidad administrada
Puedes usar identidades administradas para invocar el punto de conexión y las implementaciones por lotes. Tenga en cuenta que esta identidad de administración no pertenece al punto de conexión por lotes, pero es la identidad que se usa para ejecutar el punto de conexión y, por tanto, crear un trabajo por lotes. Tanto las identidades asignadas por el usuario como las asignadas por el sistema se pueden usar en este escenario.
En los recursos configurados para las identidades administradas para los recursos de Azure, puede iniciar sesión con la identidad administrada. El inicio de sesión con la identidad del recurso se realiza mediante la marca --identity. Para obtener más detalles, consulte Inicio de sesión con la CLI de Azure.
az login --identity
Una vez autenticado, use el siguiente comando para ejecutar un trabajo de implementación por lotes:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Configuración de RBAC para la invocación de puntos de conexión por lotes
Los puntos de conexión por lotes exponen un consumidor de API duradero que puede usar para generar trabajos. El invocador solicita el permiso adecuado para poder generar esos trabajos. Puede usar uno de los roles de seguridad integrados o crear uno nuevo para estos fines.
Para invocar correctamente un punto de conexión por lotes, necesita que se concedan las siguientes acciones explícitas a la identidad usada para invocar los puntos de conexión. Consulte Pasos para asignar un rol de Azure para obtener instrucciones para asignarlos.
"actions": [
"Microsoft.MachineLearningServices/workspaces/read",
"Microsoft.MachineLearningServices/workspaces/data/versions/write",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/write",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/write",
"Microsoft.MachineLearningServices/workspaces/datastores/read",
"Microsoft.MachineLearningServices/workspaces/datastores/write",
"Microsoft.MachineLearningServices/workspaces/datastores/listsecrets/action",
"Microsoft.MachineLearningServices/workspaces/listStorageAccountKeys/action",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/jobs/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/jobs/write",
"Microsoft.MachineLearningServices/workspaces/computes/read",
"Microsoft.MachineLearningServices/workspaces/computes/listKeys/action",
"Microsoft.MachineLearningServices/workspaces/metadata/secrets/read",
"Microsoft.MachineLearningServices/workspaces/metadata/snapshots/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/write",
"Microsoft.MachineLearningServices/workspaces/experiments/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/submit/action",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/write",
"Microsoft.MachineLearningServices/workspaces/metrics/resource/write",
"Microsoft.MachineLearningServices/workspaces/modules/read",
"Microsoft.MachineLearningServices/workspaces/models/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/write",
"Microsoft.MachineLearningServices/workspaces/environments/read",
"Microsoft.MachineLearningServices/workspaces/environments/write",
"Microsoft.MachineLearningServices/workspaces/environments/build/action",
"Microsoft.MachineLearningServices/workspaces/environments/readSecrets/action"
]
Configuración de clústeres de proceso para el acceso a datos
Los puntos de conexión de Batch garantizan que solo los usuarios autorizados puedan invocar implementaciones por lotes y generar trabajos. Sin embargo, dependiendo de cómo se configuren los datos de entrada, se pueden usar otras credenciales para leer los datos subyacentes. Use la tabla siguiente para comprender qué credenciales se usan:
| Tipo de entrada de datos | Credenciales en el almacén | Credenciales usadas | Acceso concedido por |
|---|---|---|---|
| Almacén de datos | Sí | Credenciales del almacén de datos en el área de trabajo | Clave de acceso o SAS |
| Recurso de datos | Sí | Credenciales del almacén de datos en el área de trabajo | Clave de acceso o SAS |
| Almacén de datos | No | Identidad del trabajo + Identidad administrada del clúster de proceso | RBAC |
| Recurso de datos | No | Identidad del trabajo + Identidad administrada del clúster de proceso | RBAC |
| Azure Blob Storage | No aplicar | Identidad del trabajo + Identidad administrada del clúster de proceso | RBAC |
| Azure Data Lake Storage Gen1 | No aplicar | Identidad del trabajo + Identidad administrada del clúster de proceso | POSIX |
| Azure Data Lake Storage Gen2 | No aplicar | Identidad del trabajo + Identidad administrada del clúster de proceso | POSIX y RBAC |
Para esos elementos de la tabla donde se muestra la Identidad del trabajo y la identidad administrada del clúster de proceso, se usa la identidad administrada del clúster de proceso para montar y configurar cuentas de almacenamiento. Pero la identidad del trabajo se sigue usando para leer los datos subyacentes, lo que le permite obtener un control de acceso pormenorizado. Esto significa que para leer correctamente los datos del almacenamiento, la identidad administrada del clúster de proceso en el que se ejecuta la implementación debe tener al menos Lector de datos de Blob Storage acceso a la cuenta de almacenamiento.
Para configurar el clúster de proceso para el acceso a datos, siga estos pasos:
Vaya a Azure Machine Learning Studio.
Vaya a Proceso y continuación, a Clústeres de proceso y seleccione el clúster de proceso que usa la implementación.
Asigne una identidad administrada al clúster de proceso:
En la sección Identidad administrada, compruebe si el proceso tiene asignada una identidad administrada. Si no es así, seleccione la opción Editar.
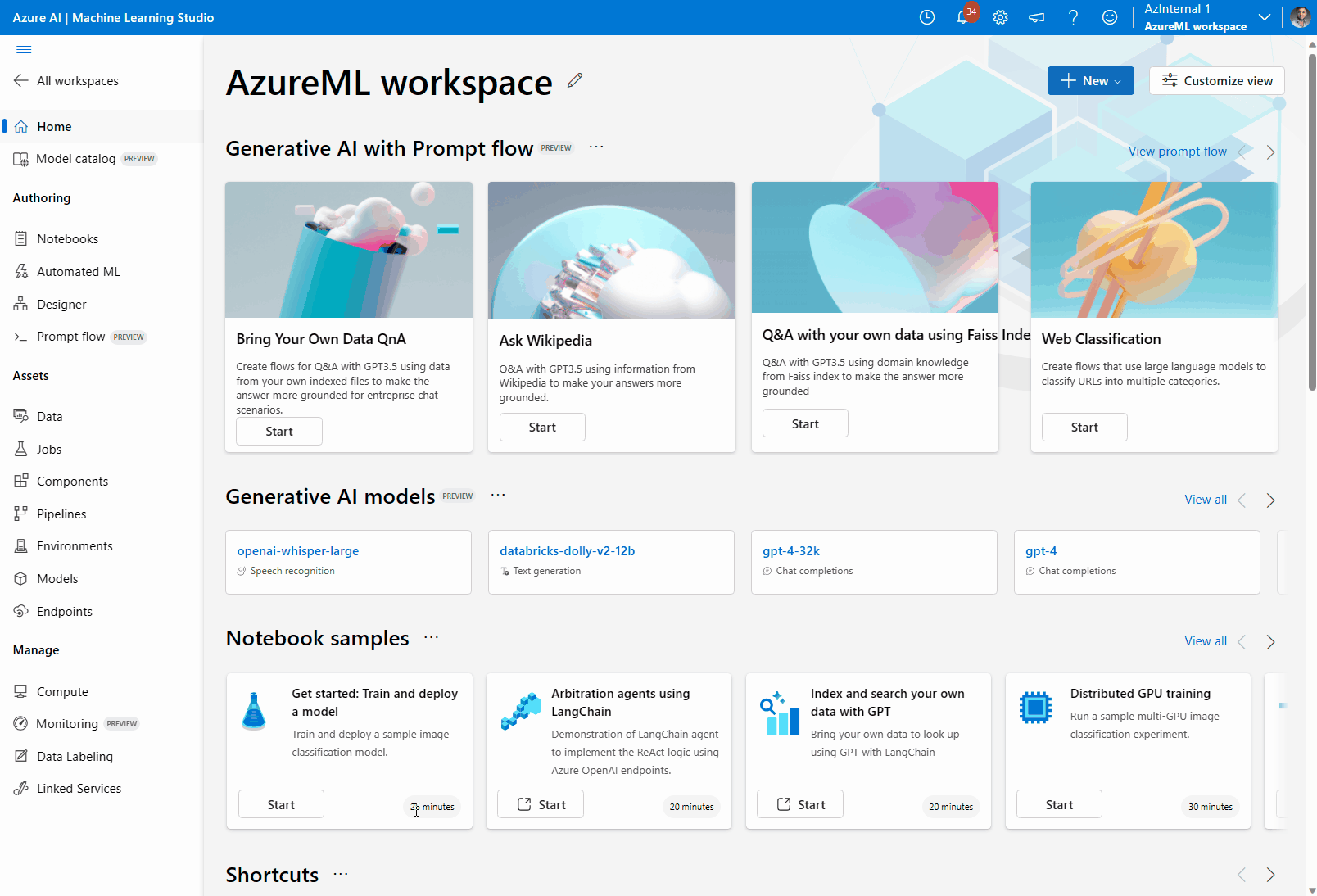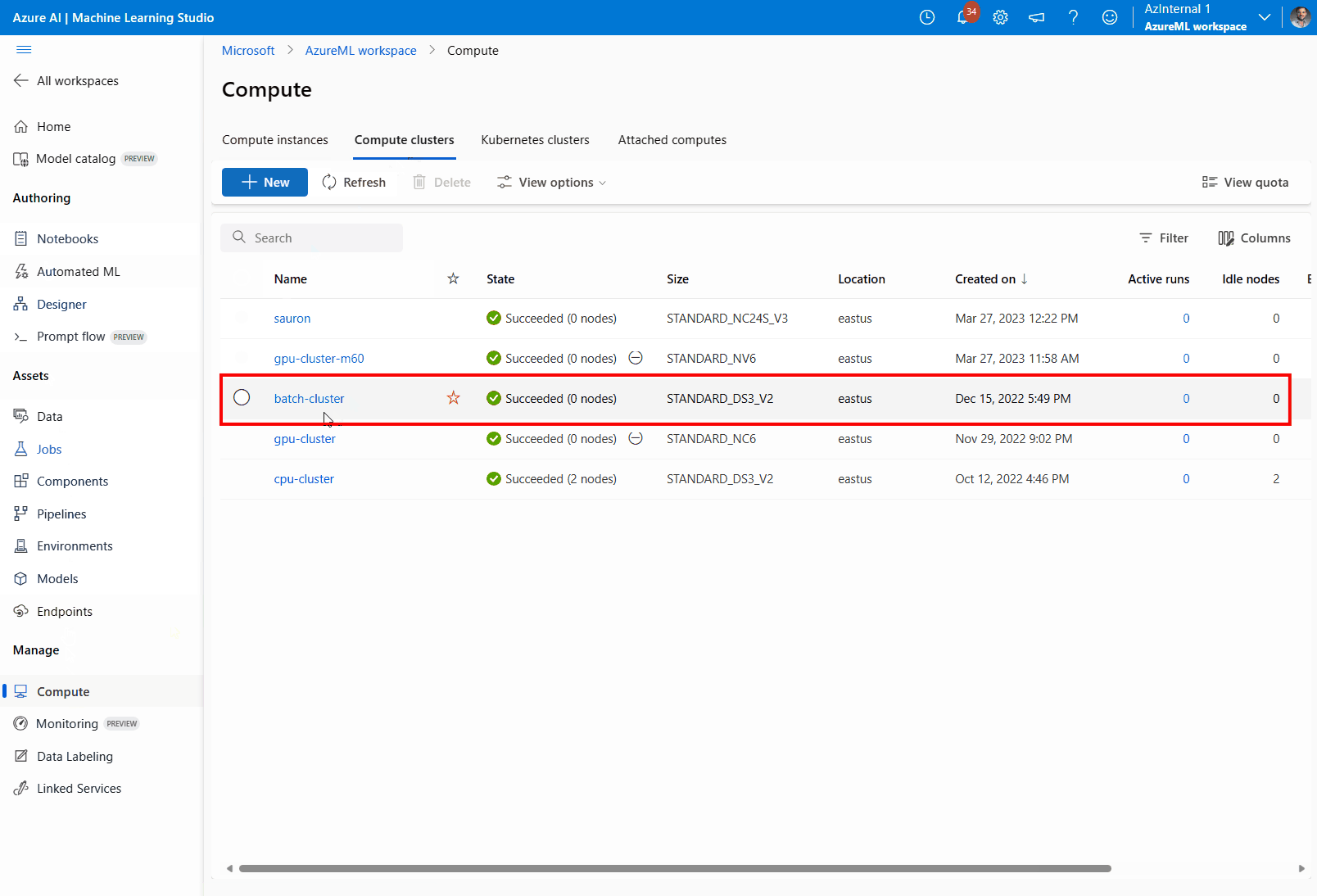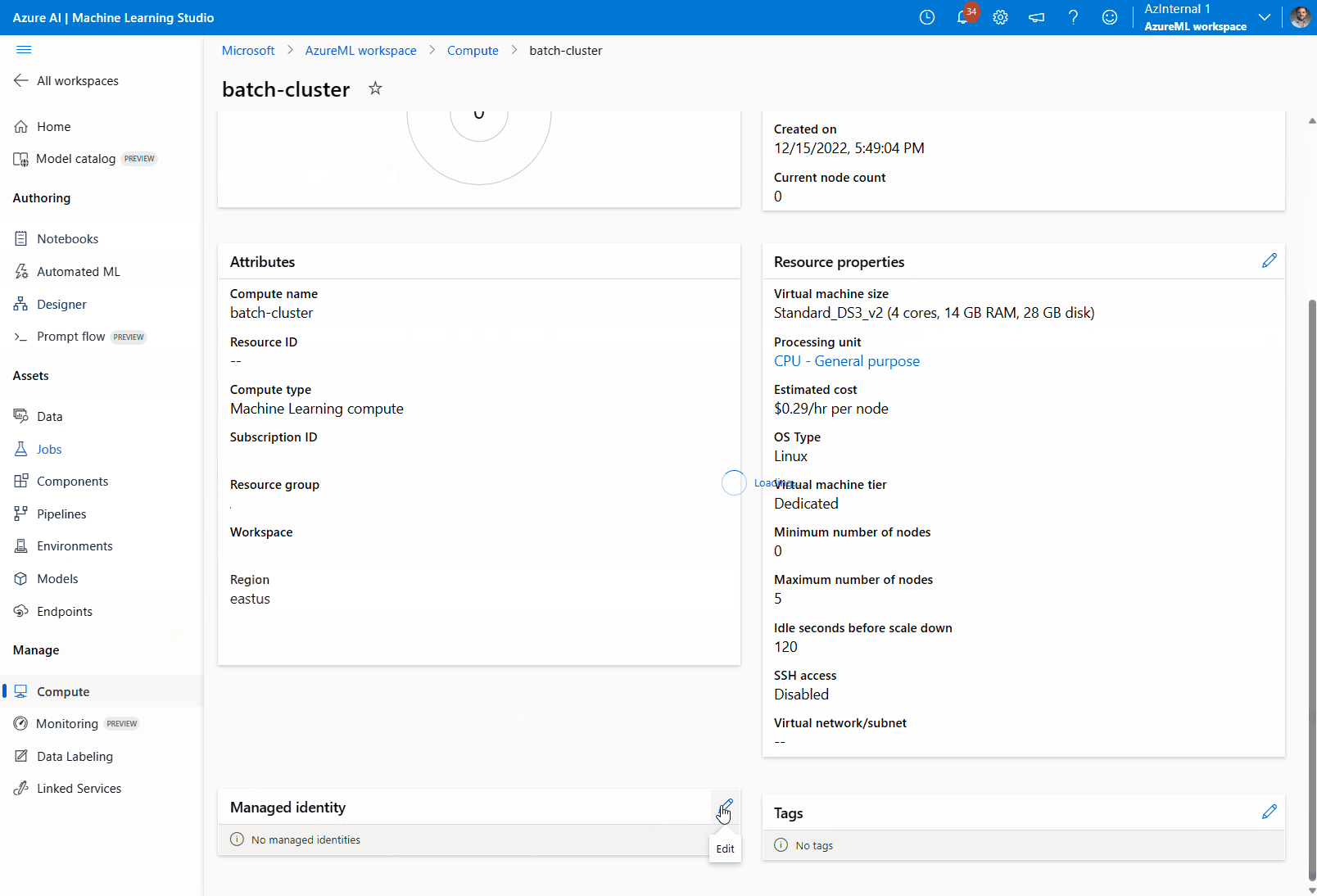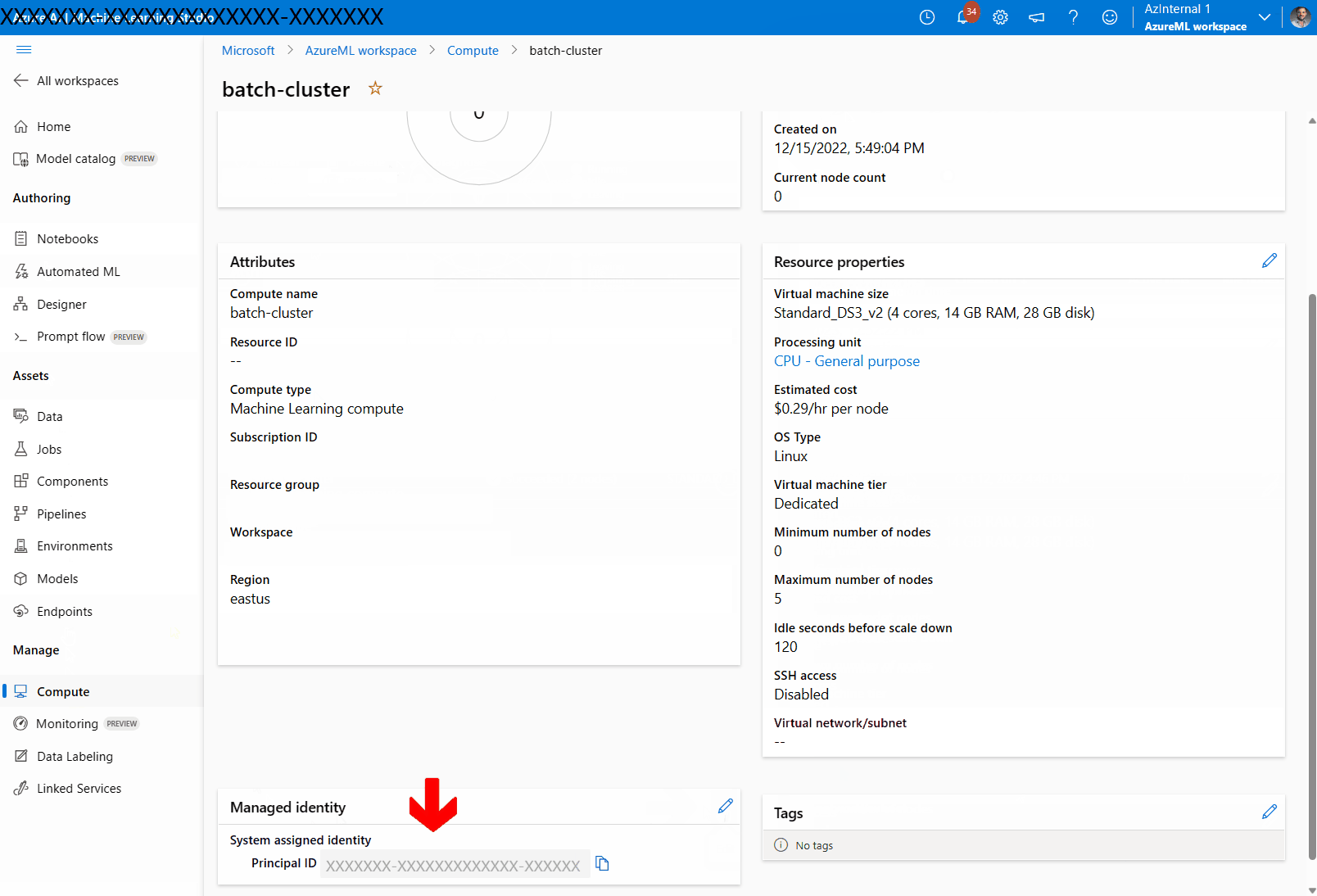
Seleccione Asignar una identidad administrada y configúrela según sea necesario. Puede usar una identidad administrada asignada por el sistema o asignada por el usuario. Si usa una identidad administrada asignada por el sistema, se denomina "[nombre del área de trabajo]/computes/[nombre del clúster de proceso]".
Guarde los cambios.
Vaya a Azure Portal y vaya a la cuenta de almacenamiento asociada donde se encuentran los datos. Si la entrada de datos es un recurso de datos o un almacén de datos, busque la cuenta de almacenamiento donde se colocan esos recursos.
Asigne el nivel de acceso lector de datos de Storage Blob en la cuenta de almacenamiento:
Vaya a la sección Control de acceso (IAM).
Seleccione la pestaña Asignación de roles, y haga clic en Agregar>asignación de roles.
Busque el rol denominado Lector de datos de Storage Blob, selecciónelo y haga clic en Siguiente.
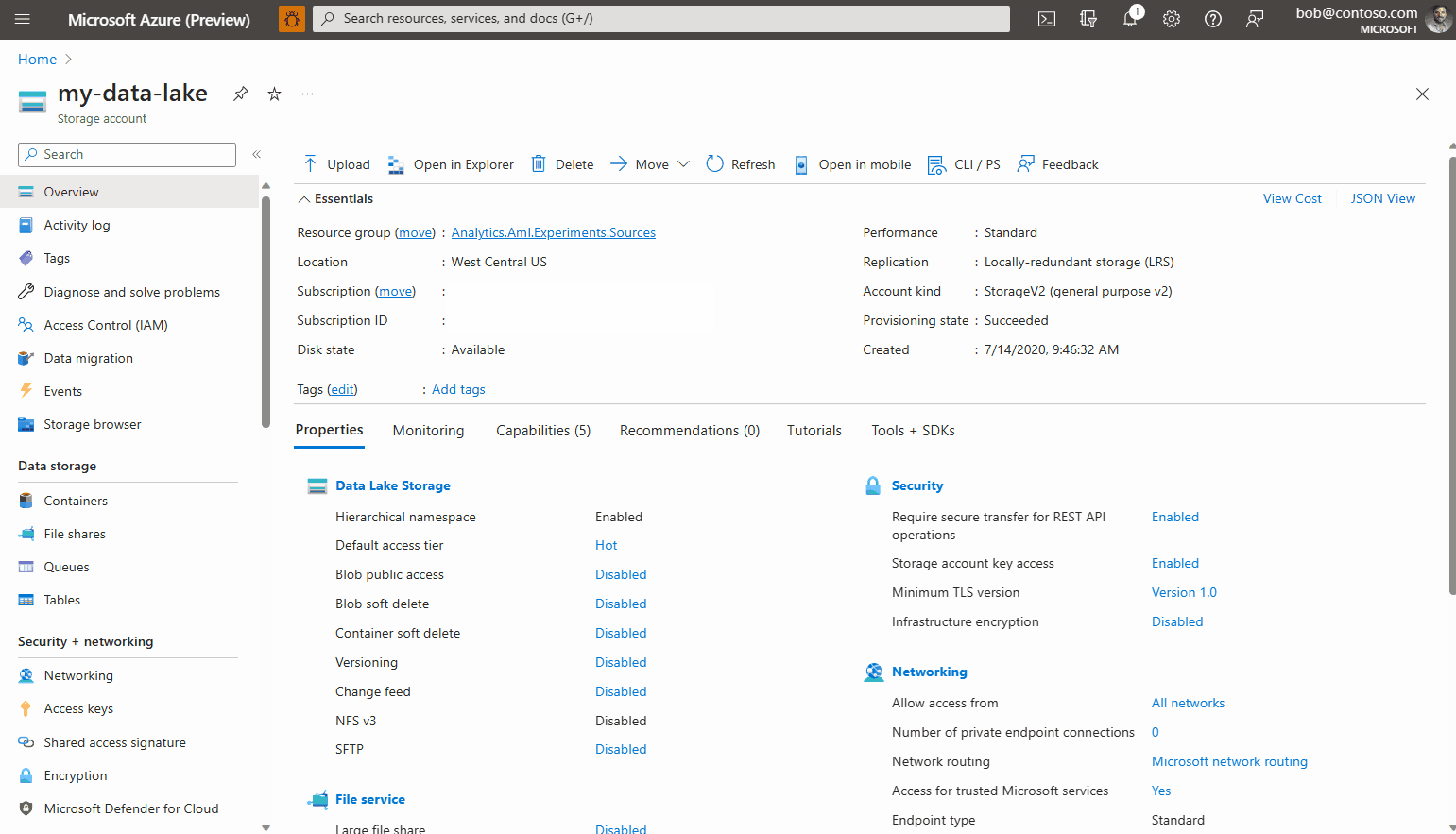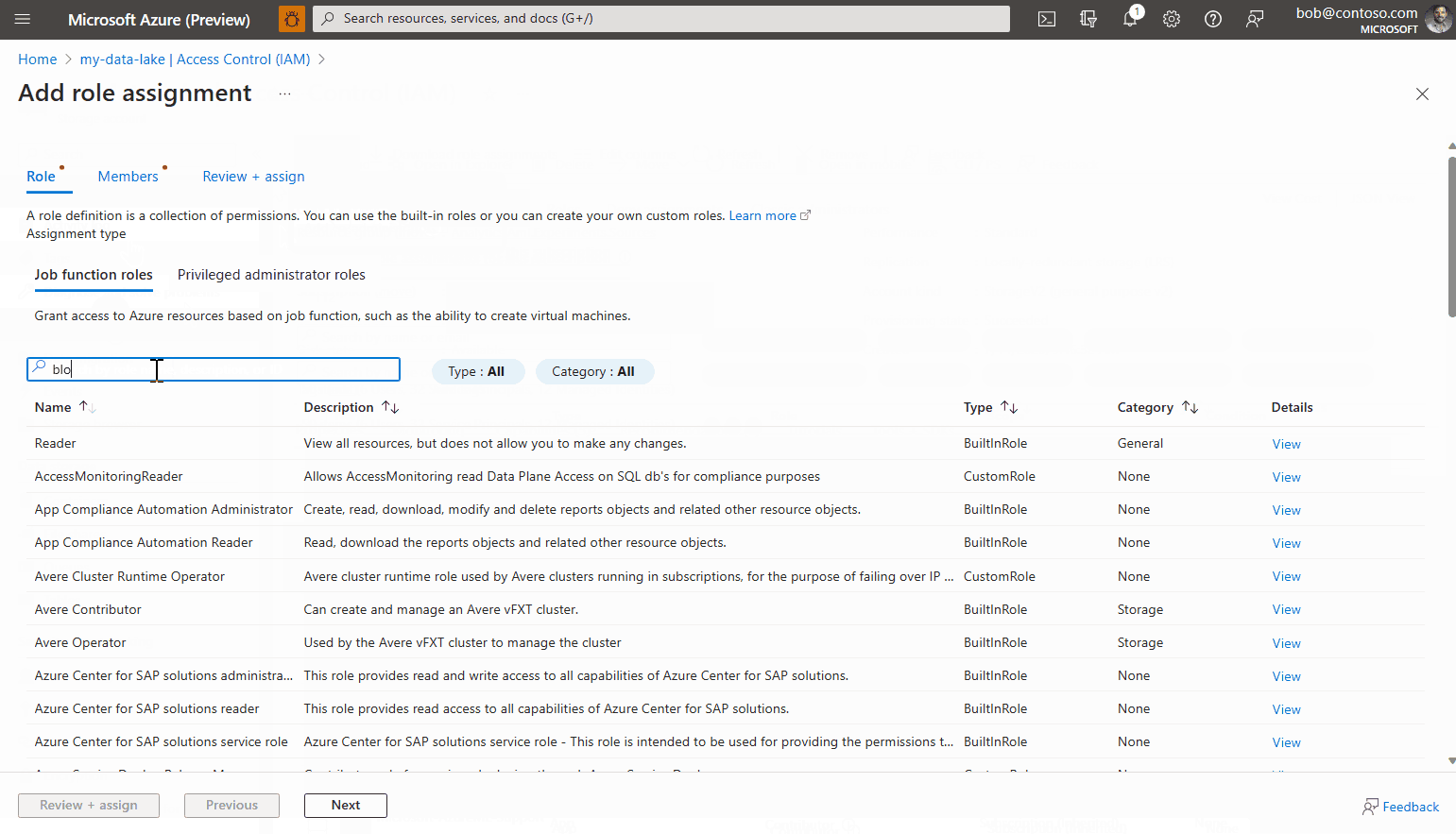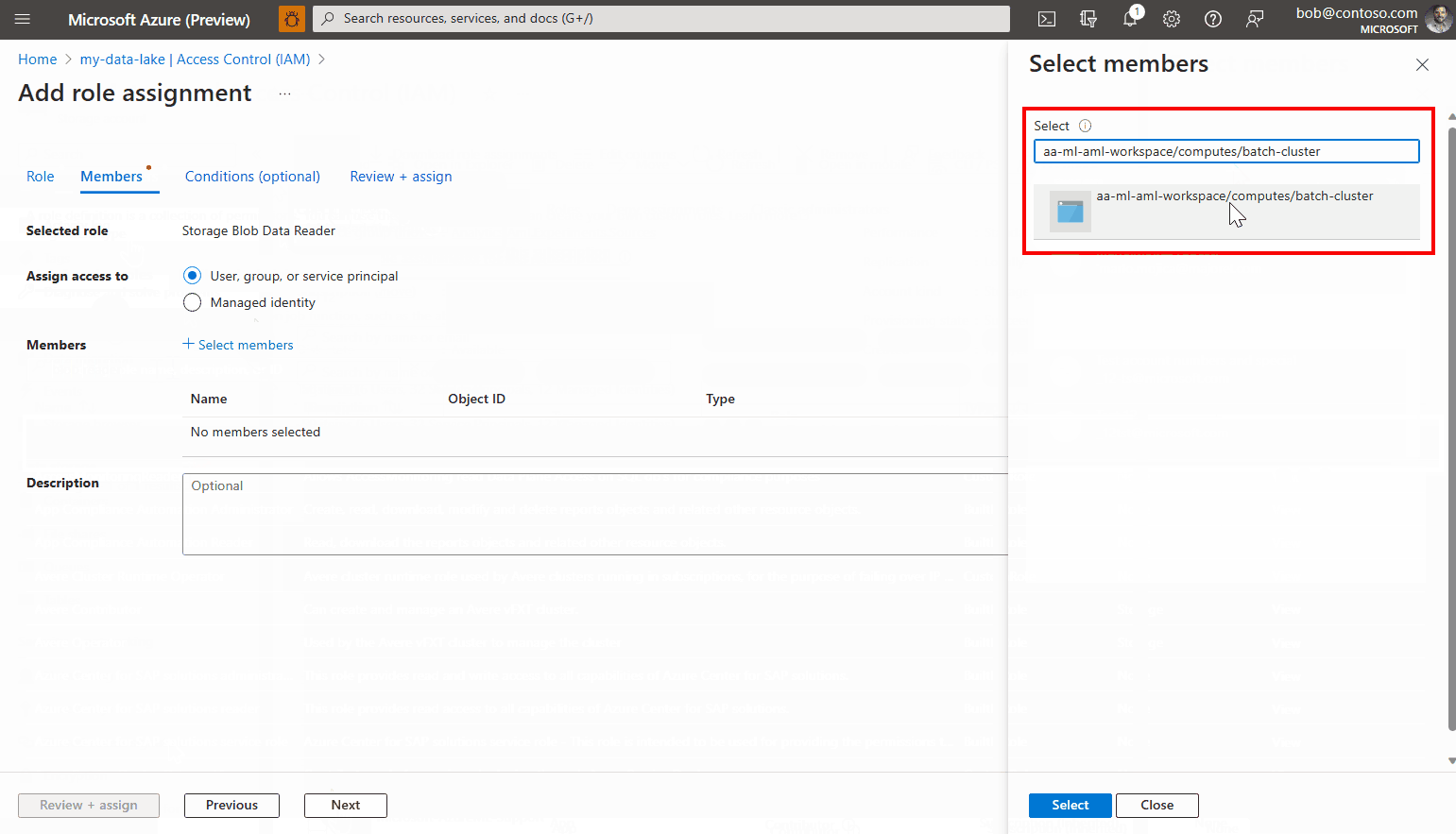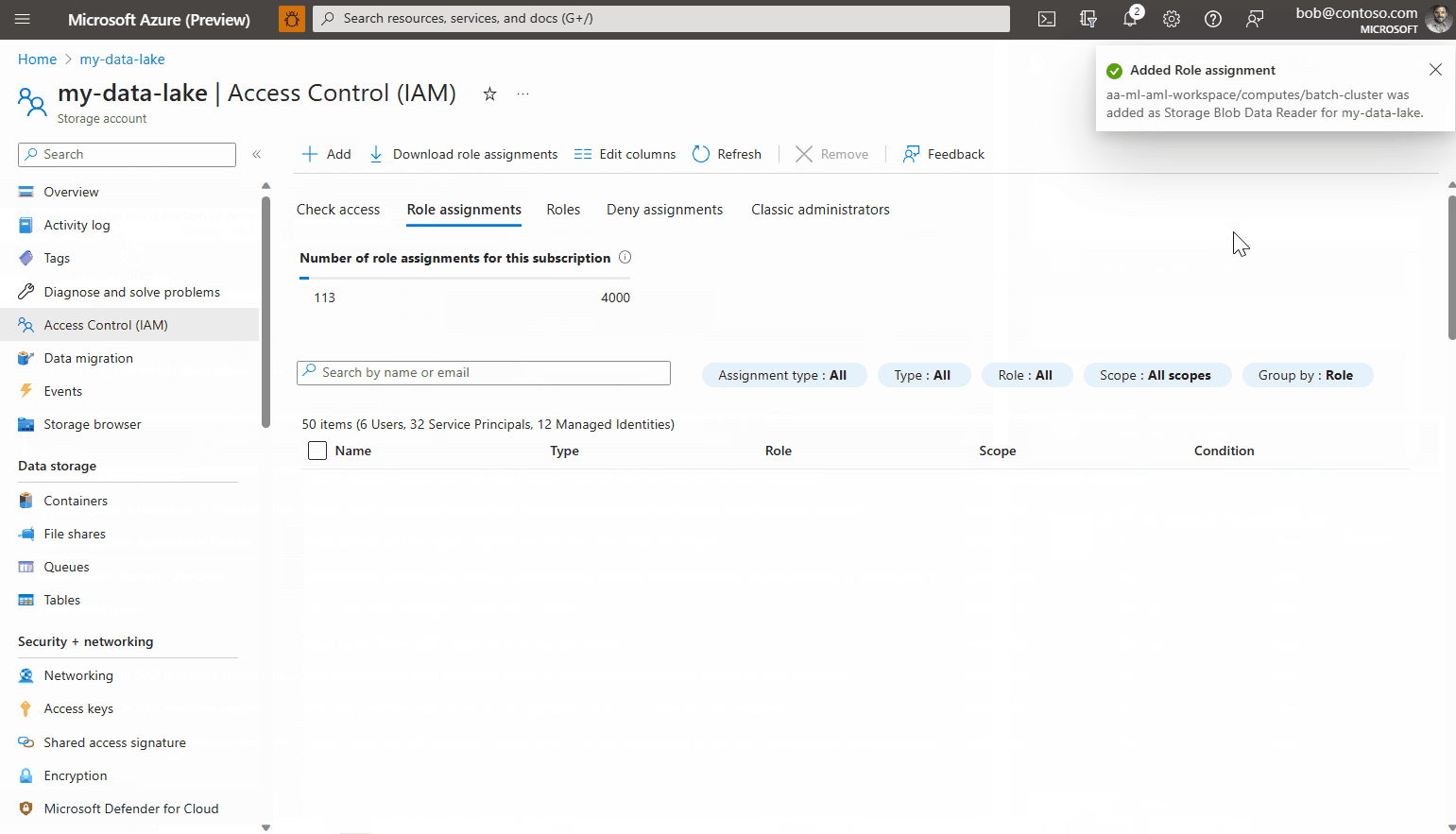
Haga clic en Seleccionar miembros.
Busque la identidad administrada que ha creado. Si usa una identidad administrada asignada por el sistema, se denomina "[nombre del área de trabajo]/computes/[nombre del clúster de proceso]".
Agregue la cuenta y complete el asistente.
El punto de conexión está listo para recibir trabajos y datos de entrada de la cuenta de almacenamiento seleccionada.