Ciencia de datos con una instancia de Data Science Virtual Machine para Windows
Windows Data Science Virtual Machine (DSVM) es un entorno de desarrollo de ciencia de datos que admite tareas de exploración y modelado de datos. El entorno viene precompilado y preagrupado con varias herramientas populares de análisis de datos que facilitan el inicio del análisis de implementaciones locales, híbridas o en la nube.
DSVM trabaja estrechamente con los servicios de Azure. Puede leer y procesar datos ya almacenados en Azure, Azure Synapse (anteriormente SQL DW), Azure Data Lake, Azure Storage o Azure Cosmos DB. También puede aprovechar otras herramientas de análisis como Azure Machine Learning.
En este artículo, aprenderá a usar DSVM para controlar las tareas de ciencia de datos e interactuar con otros servicios de Azure. Se trata de un ejemplo de tareas que DSVM puede cubrir:
- Usar un cuaderno de Jupyter Notebook para experimentar con los datos en un explorador mediante Python 2, Python 3 y Microsoft R. (Microsoft R es una versión de R preparada para las empresas y diseñada para ofrecer un alto rendimiento).
- Explorar datos y desarrollar modelos localmente en DSVM con Microsoft Machine Learning Server y Python.
- Administrar los recursos de Azure mediante Azure Portal o PowerShell.
- Ampliar el espacio de almacenamiento y compartir código o conjuntos de datos de gran escala entre todo el equipo, con un recurso compartido de Azure Files como una unidad que se puede montar en DSVM.
- Compartir código con su equipo con GitHub. Acceder al repositorio con los clientes Git preinstalados: Git Bash y Git GUI.
- Acceder a servicios de análisis y datos de Azure:
- Almacenamiento de blobs de Azure
- Azure Cosmos DB
- Azure Synapse (anteriormente SQL DW)
- Azure SQL Database
- Crear informes y un panel con la instancia de Power BI Desktop (preinstalada en DSVM) e implementarlos en la nube.
- Instalar más herramientas en la máquina virtual.
Nota:
A muchos de los servicios de almacenamiento y análisis de datos que se enumeran en este artículo se les aplican cargos de uso adicionales. Para más información, consulte la página de precios de Azure.
Requisitos previos
- Suscripción a Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
- Una instancia de DSVM aprovisionada en Azure Portal. Para obtener más información, visite el recurso Creación de una máquina virtual.
Nota:
Se recomienda usar el módulo Azure Az de PowerShell para interactuar con Azure. Para comenzar, consulte Instalación de Azure PowerShell. Para más información sobre cómo migrar al módulo Az de PowerShell, consulte Migración de Azure PowerShell de AzureRM a Az.
Uso de Jupyter Notebooks
Jupyter Notebook proporciona un IDE basado en el explorador para explorar y modelar datos. En un cuaderno de Jupyter Notebook se pueden usar Python 2, Python 3 o R.
Para iniciar el cuaderno de Jupyter Notebook, seleccione el icono Jupyter Notebook en el menú Inicio o en el escritorio. En el símbolo del sistema de DSVM, también puede ejecutar el comando jupyter notebook desde el directorio que hospeda cuadernos existentes o donde quiere crear cuadernos.
Después de iniciar Jupyter, vaya al directorio /notebooks. Este directorio hospeda cuadernos de ejemplo que se empaquetan previamente en DSVM. Puede:
- Seleccionar el cuaderno para ver el código.
- Seleccione Mayús+Escriba para ejecutar cada celda.
- Seleccione Celda>Ejecutar para ejecutar todo el cuaderno.
- Crear un cuaderno; seleccione el icono de Jupyter (esquina superior izquierda), seleccione el botón Nuevo y, a continuación, elija el idioma del cuaderno (también conocido como kernels).
Nota:
En este momento, se admiten los kernels de Python 2.7, Python 3.6, R, Julia y PySpark en Jupyter. El kernel de R admite la programación tanto en R de código abierto como en Microsoft R. En el cuaderno, puede explorar los datos, compilar el modelo y probar ese modelo con su elección de bibliotecas.
Exploración de datos y desarrollo de modelos con Microsoft Machine Learning Server
Nota:
La compatibilidad con Machine Learning Server independiente finalizó el 1 de julio de 2021. Se quitó de las imágenes de DSVM después del 30 de junio de 2021. Las implementaciones existentes todavía pueden acceder al software, pero el soporte técnico finalizó después del 1 de julio de 2021.
Puede usar R y Python para el análisis de datos directamente en DSVM.
Para R, puede usar Herramientas de R para Visual Studio. Microsoft proporciona otras bibliotecas, además del recurso CRAN R de código abierto. Estas bibliotecas permiten análisis escalables y analizar masas de datos que superan las limitaciones de tamaño de memoria del análisis fragmentado paralelo.
En el caso de Python, puede usar un IDE (por ejemplo, Visual Studio Community Edition) que ya tiene preinstalada la extensión Herramientas de Python para Visual Studio (PTVS). De forma predeterminada, solo Python 3.6, el entorno raíz de Conda, se configura en PTVS. Para habilitar Anaconda Python 2.7:
- Cree entornos personalizados para cada versión. Seleccione Herramientas>Herramientas de Python>Entornos de Pythony, a continuación, seleccione + Personalizar en Visual Studio Community Edition.
- Proporcione una descripción y establezca la ruta de acceso del prefijo del entorno como c:\anaconda\envs\python2 para Anaconda Python 2.7.
- Seleccione Detectar automáticamente>Aplicar para guardar el entorno.
Visite el recurso Documentación de PTVS para obtener más información sobre cómo crear entornos de Python.
Ahora puede crear un nuevo proyecto de Python. Seleccione Archivo>Nuevo>Proyecto>Python y seleccione el tipo de aplicación de Python que desea compilar. Puede establecer el entorno de Python del proyecto actual en la versión que quiera (Python 2.7 o 3.6) si hace clic con el botón derecho en Entornos de Python y selecciona Agregar o quitar entornos de Python. Visite la documentación del producto para obtener más información sobre cómo trabajar con PTVS.
Administración de recursos de Azure
DSVM permite compilar su solución de análisis de forma local en la máquina virtual. sino que también le permite acceder a los servicios de la plataforma en la nube de Azure. Azure proporciona varios servicios, como proceso, almacenamiento, análisis de datos, etc., que puede administrar y acceder desde DSVM.
Tiene dos opciones disponibles para administrar la suscripción de Azure y los recursos en la nube:
Visite Azure Portal en el explorador.
Use scripts de PowerShell. Ejecute Azure PowerShell desde un acceso directo del escritorio o desde el menú Inicio. Visite el recurso Documentación de Microsoft Azure PowerShell para obtener más información.
Extensión del almacenamiento mediante sistemas de archivos compartidos
Los científicos de datos pueden compartir grandes conjuntos de datos, código u otros recursos dentro del equipo. DSVM tiene aproximadamente 45 GB de espacio disponible. Para expandir el almacenamiento, puede usar Azure Files y montarlo en una o varias instancias de DSVM, o bien acceder a él con una API de REST. También puede usar Azure Portal o Azure PowerShell para agregar discos de datos dedicados adicionales.
Nota:
El espacio máximo en un recurso compartido de archivos de Azure es de 5 TB. Cada archivo tiene un límite de tamaño de 1 TB.
Este script de Azure PowerShell crea un recurso compartido de Azure Files:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
Puede montar un recurso compartido de Azure Files en cualquier máquina virtual de Azure. Se recomienda colocar la máquina virtual y la cuenta de almacenamiento en el mismo centro de datos de Azure para evitar cargos de latencia y transferencia de datos. Estos comandos de Azure PowerShell montan la unidad en DSVM:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
Puede acceder a esta unidad del mismo modo que a cualquier otra unidad normal de la máquina virtual.
Código compartido en GitHub
El repositorio de código de GitHub hospeda ejemplos de código y orígenes de código para muchas herramientas que comparte la comunidad de desarrolladores. Utiliza Git como tecnología para realizar un seguimiento de las versiones de los archivos de código y almacenarlas. GitHub también sirve como plataforma para crear su propio repositorio. Su propio repositorio puede almacenar el código compartido y la documentación del equipo, implementar el control de versiones y controlar los permisos de acceso para las partes interesadas que quieran ver y contribuir con código. GitHub admite la colaboración dentro de su equipo, el uso del código desarrollado por la comunidad y las contribuciones de código a la comunidad. Para más información sobre Git, visite las páginas de ayuda de GitHub.
DSVM incluye herramientas de cliente en la línea de comandos y en la GUI para poder acceder al repositorio de GitHub. La herramienta de línea de comandos de Git Bash funciona con Git y GitHub. Visual Studio está instalado en DSVM y cuenta con las extensiones de Git. Tanto el menú Inicio como el escritorio tienen iconos para estas herramientas.
Use el comando git clone para descargar código de un repositorio de GitHub. Para descargar el repositorio de ciencia de datos publicado por Microsoft en el directorio actual, por ejemplo, ejecute este comando en Git Bash:
git clone https://github.com/Azure/DataScienceVM.git
Visual Studio puede controlar la misma operación de clonación. En esta captura de pantalla, se muestra cómo acceder a las herramientas de Git y GitHub en Visual Studio:

Puede trabajar con recursos de github.com disponibles en el repositorio de GitHub. Para obtener más información, visite el recurso Hoja de características clave de GitHub.
Acceso a servicios de análisis y datos de Azure
Almacenamiento de blobs de Azure
Azure Blob Storage es un servicio de almacenamiento en la nube confiable y económico para recursos de datos grandes y pequeños. En esta sección se describe cómo mover los datos a Blob Storage y cómo acceder a los datos almacenados en un blob de Azure.
Requisitos previos
Una cuenta de Azure Blob Storage, creada en Azure Portal.

Confirme que la herramienta AzCopy de la línea de comandos está preinstalada con este comando:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exeEl directorio que hospeda el archivo azcopy.exe ya se encuentra en la variable de entorno PATH para que no tenga que escribir la ruta de acceso completa del comando al ejecutar esta herramienta. Para obtener más información sobre la herramienta AzCopy, lea la documentación de AzCopy.
Inicie el Explorador de Azure Storage desde aquí. Puede descargarla desde la página web del Explorador de Storage.


Traslado de datos de una máquina virtual a un blob de Azure: AzCopy
Para mover datos entre los archivos locales y Blob Storage, puede usar AzCopy en la línea de comandos o en PowerShell:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
- Reemplace C:\myfolder con la ruta de acceso del directorio que hospeda el archivo
- Reemplace mystorageaccount con el nombre de la cuenta de Blob Storage
- Reemplace mycontainer con el nombre del contenedor
- Reemplace clave de cuenta de almacenamiento con la clave de acceso de Blob Storage
Puede encontrar las credenciales de su cuenta de almacenamiento en Azure Portal.
Ejecute el comando de AzCopy en PowerShell o desde un símbolo del sistema. Estos son ejemplos de comandos de AzCopy:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
Después de ejecutar el comando de AzCopy para copiar el archivo en un blob de Azure, el archivo aparecerá en el Explorador de Azure Storage.

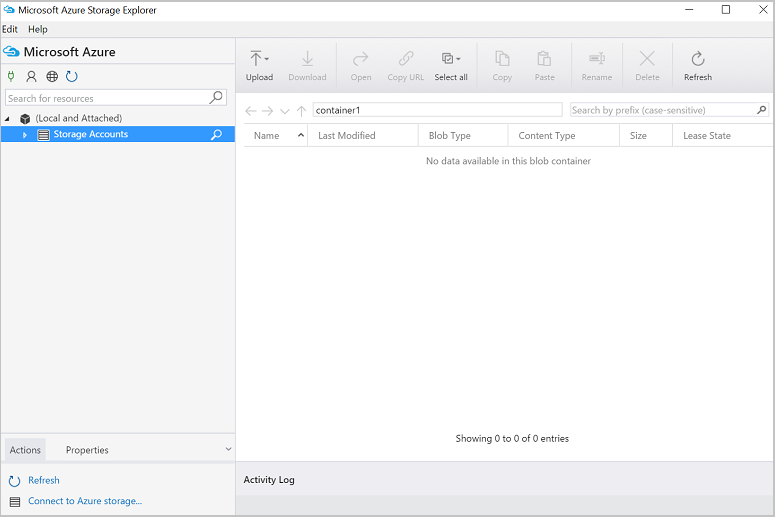
Traslado de datos de una máquina virtual a un blob de Azure: Explorador de Azure Storage
También puede cargar datos desde el archivo local en la máquina virtual con el Explorador de Azure Storage:
Para cargar datos en un contenedor, seleccione el contenedor de destino y seleccione en el botón Cargar.
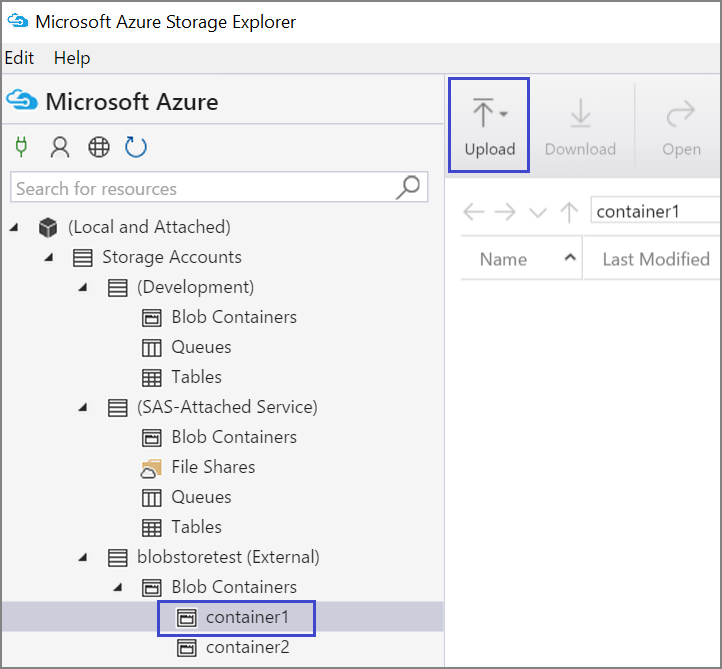
A la derecha del cuadro Archivos, seleccione los puntos suspensivos (...), seleccione uno o varios archivos para cargar desde el sistema de archivos y seleccione Cargar para empezar a cargar los archivos.


Lectura de datos desde un blob de Azure: ODBC de Python
La biblioteca BlobService puede leer datos directamente desde un blob ubicado en un Jupyter Notebook o en un programa de Python. En primer lugar, importe los paquetes necesarios:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Especifique las credenciales de su cuenta de Blob Storage y lea los datos del blob:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
Los datos se leen como una trama de datos:

Azure Synapse Analytics y bases de datos
Azure Synapse Analytics es un "almacén de datos elástico que funciona como un servicio" con una experiencia de SQL Server de clase empresarial. Este recurso describe cómo aprovisionar Azure Synapse Analytics. Después de aprovisionar Azure Synapse Analytics, este tutorial explica cómo controlar la carga, exploración y modelado de datos mediante el uso de datos en Azure Synapse Analytics.
Azure Cosmos DB
Azure Cosmos DB es una base de datos NoSQL basada en la nube. Puede controlar documentos JSON, por ejemplo, y puede almacenar y consultar los documentos. En estos pasos de ejemplo se muestra cómo acceder a Azure Cosmos DB desde DSVM:
El SDK de Python de Azure Cosmos DB ya está instalado en DSVM. Para actualizarlo, ejecute
pip install pydocumentdb --upgradedesde un símbolo del sistema.Cree una base de datos y una cuenta de Azure Cosmos DB en Azure Portal.
Descargue la herramienta de migración de datos de Azure Cosmos DB desde el Centro de descarga de Microsoft y extráigala en el directorio que quiera.
Importe los datos JSON (datos de volcanes) almacenados en un blob público en Azure Cosmos DB con los siguientes parámetros de comando en la herramienta de migración. (Use dtui.exe desde el directorio en el que ha instalado la herramienta de migración de datos de Azure Cosmos DB). Especifique las ubicaciones de origen y destino con estos parámetros:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
Después de importar los datos, puede ir a Jupyter y abrir el cuaderno titulado DocumentDBSample. Contiene el código de Python para acceder a Azure Cosmos DB y controlar algunas consultas básicas. Visite la página de documentación del servicio Azure Cosmos DB para más información sobre Azure Cosmos DB.
Uso de informes y paneles de Power BI
Puede visualizar el archivo JSON Volcano descrito en el ejemplo anterior de Azure Cosmos DB en Power BI Desktop para obtener información visual sobre los propios datos. Este artículo de Power BI ofrece pasos detallados. Estos son los pasos, en un nivel alto:
- Abra Power BI Desktop y seleccione Obtener datos. Especifique esta dirección URL:
https://cahandson.blob.core.windows.net/samples/volcano.json. - Los registros JSON, importados como una lista, deben estar visibles. Convierta la lista en una tabla para que Power BI pueda trabajar con ella.
- Seleccione el icono expandir (flecha) para expandir las columnas.
- La ubicación es un campo de Registro. Expanda el registro y seleccione solo las coordenadas. Coordenada es una columna de la lista.
- Agregue una nueva columna para convertir la columna de coordenadas de la lista en una columna LatLong separada por comas. Use la fórmula
Text.From([coordinates]{1})&","&Text.From([coordinates]{0})para concatenar los dos elementos del campo de lista de coordenadas. - Convierta la columna Elevación en decimal y seleccione los botones Cerrar y Aplicar.
Puede usar el siguiente código como alternativa a los pasos anteriores. Incluye en el script los pasos usados en el Editor avanzado de Power BI para escribir las transformaciones de datos en un lenguaje de consulta:
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
Ya tiene los datos en el modelo de datos de Power BI. La instancia de Power BI Desktop debe aparecer de la siguiente forma:

Puede empezar a crear informes y visualizaciones con el modelo de datos. Este artículo de Power BI explica cómo crear un informe.
Escalado dinámico de DSVM
Puede escalar y reducir verticalmente DSVM para satisfacer las necesidades del proyecto. Si no necesita usar la máquina virtual por la noche o durante los fines de semana, puede apagarla desde Azure Portal.
Nota:
Incurrirá en cargos de proceso si solo usa el botón de apagado para el sistema operativo en la máquina virtual. En su lugar, debe desasignar el DSVM mediante Azure Portal o Cloud Shell.
Para un proyecto de análisis a gran escala, es posible que necesite más capacidad de CPU, memoria o disco. Si es así, puede encontrar máquinas virtuales de diferentes números de núcleos de CPU, capacidad de memoria, tipos de disco (incluidas unidades de estado sólido) e instancias basadas en GPU para el aprendizaje profundo que satisfagan sus necesidades presupuestarias y de proceso. La página de precios de Azure Virtual Machines muestra la lista completa de máquinas virtuales, junto con sus precios de proceso por hora.
Adición de más herramientas
DSVM ofrece herramientas precompiladas que pueden satisfacer muchas necesidades comunes de análisis de datos. Ahorran tiempo porque no es necesario instalar y configurar individualmente los entornos. También le ahorran dinero, ya que solo paga por los recursos que usa.
Para mejorar su entorno de análisis, puede usar otros servicios de datos y análisis de Azure que se han descrito en este artículo. En algunos casos, es posible que necesite otras herramientas, incluidas herramientas específicas de propietarios asociados. Tiene acceso administrativo completo en la máquina virtual para instalar las herramientas que necesita. También puede instalar otros paquetes en Python y R que no estén preinstalados. En el caso de Python, puede usar conda o pip. En cuanto a R, puede usar install.packages() en la consola de R o recurrir al IDE y seleccionar Paquetes>Instalar paquetes.
Aprendizaje profundo
Además de los ejemplos basados en marcos, también obtiene un conjunto de tutoriales completos que se validaron en DSVM. Estos tutoriales le ayudan a iniciar el desarrollo de aplicaciones de aprendizaje profundo en dominios de análisis de imágenes y texto o lenguaje.
Ejecución de redes neuronales en distintos marcos: en este tutorial se muestra cómo migrar código de un marco a otro. También se muestra cómo comparar el rendimiento de los modelos y el tiempo de ejecución entre marcos.
Guía paso a paso para compilar una solución de un extremo a otro para detectar productos dentro de imágenes: la técnica de detección de imágenes puede localizar y clasificar objetos dentro de las imágenes. Esta tecnología tiene el potencial de aportar grandes ventajas a muchos ámbitos comerciales de uso real. Por ejemplo, los minoristas pueden usar esta técnica para identificar un producto que un cliente ha recogido del estante. Esta información ayuda a las tiendas minoristas a administrar el inventario de productos.
Aprendizaje profundo para audio: en este tutorial se muestra cómo entrenar un modelo de aprendizaje profundo para detectar eventos de audio en el conjunto de datos de sonidos urbanos. También se proporciona información general sobre cómo trabajar con datos de audio.
Clasificación de documentos de texto: en este tutorial se muestra cómo compilar y entrenar dos arquitecturas de redes neuronales: red de atención jerárquica y red de memoria a corto y largo plazo (LSTM). Estas redes neuronales usan la API de Keras de aprendizaje profundo, para clasificar documentos de texto.
Resumen
En este artículo se han descrito algunas de las cosas que puede hacer en Microsoft Data Science Virtual Machine, pero puede hacer muchas más para convertir DSVM en un entorno de análisis eficaz.