Registros de Machine Learning para MLOps
Este artículo describe cómo los registros de Azure Machine Learning desacoplan los recursos de aprendizaje automático de las áreas de trabajo, lo que le permite usar MLOps en entornos de desarrollo, pruebas y producción. Los entornos pueden variar en función de la complejidad de los sistemas de TI. Los siguientes factores influyen en el número y el tipo de entornos que necesita:
- Directivas de seguridad y cumplimiento. Es posible que tenga que aislar los entornos de producción de los de desarrollo en términos de controles de acceso, arquitectura de red y exposición de datos.
- Suscripciones. Los entornos de desarrollo y los entornos de producción suelen usar suscripciones independientes para fines de facturación, presupuesto y administración de costos.
- Regiones. Es posible que tenga que implementar en diferentes regiones de Azure para admitir los requisitos de latencia y redundancia.
En los escenarios anteriores, puede usar diferentes áreas de trabajo de Azure Machine Learning para desarrollo, pruebas y producción. Esta configuración presenta los siguientes desafíos potenciales para el entrenamiento y la implementación del modelo:
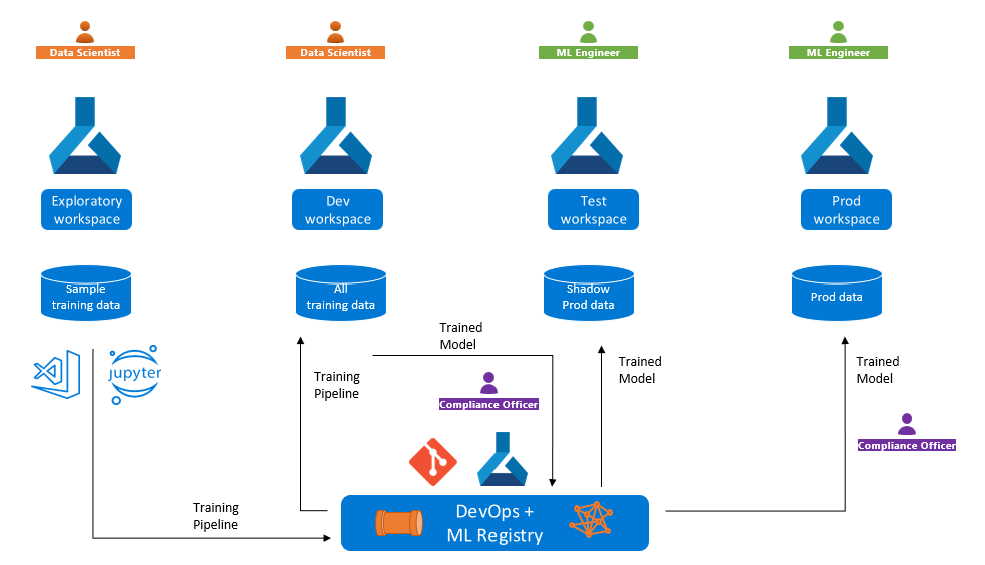
Es posible que tenga que entrenar un modelo en un área de trabajo de desarrollo, pero implementarlo en un área de trabajo de producción, posiblemente en otra suscripción o región de Azure. En este caso, debe poder hacer un seguimiento del trabajo de entrenamiento. Por ejemplo, si encuentra problemas de precisión o rendimiento con la implementación de producción, debe analizar las métricas, los registros, el código, el entorno y los datos que usó para entrenar el modelo.
Es posible que tenga que desarrollar una canalización de entrenamiento con datos de prueba o datos anónimos en el área de trabajo de desarrollo, pero volver a entrenar el modelo con datos de producción en el área de trabajo de producción. En este caso, es posible que tenga que comparar las métricas de entrenamiento en los datos de ejemplo frente a los datos de producción para asegurarse de que las optimizaciones de entrenamiento funcionan bien con los datos reales.
MLOps entre áreas de trabajo con registros
Un registro, al igual que un repositorio de Git, desacopla los recursos de aprendizaje automático de las áreas de trabajo y hospeda los recursos en una ubicación central, lo que hace que estén disponibles para todas las áreas de trabajo de la organización. Puede usar registros para almacenar y compartir recursos como modelos, entornos, componentesy conjuntos de datos.
Para promover modelos en entornos de desarrollo, prueba y producción, puede empezar por desarrollar de forma iterativa un modelo en el entorno de desarrollo. Cuando tenga un buen modelo candidato, podrá publicarlo en un registro. Después, puede implementar el modelo desde el registro en puntos de conexión en diferentes áreas de trabajo.
Sugerencia
Si ya tiene modelos registrados en un área de trabajo, puede promover los modelos a un registro. También puede registrar un modelo directamente en un registro desde la salida de un trabajo de entrenamiento.
Para desarrollar una canalización en una área de trabajo y, a continuación, ejecutarla en otras áreas de trabajo, empiece por registrar los componentes y entornos que forman los bloques de creación de la canalización. Al enviar el trabajo de canalización, el proceso y los datos de entrenamiento, que son únicos para cada área de trabajo, determinan el área de trabajo en la que se va a ejecutar.
El siguiente diagrama muestra la promoción de canalizaciones de entrenamiento entre las áreas de trabajo exploratorias y de desarrollo y, a continuación, la promoción del modelo entrenado a los de prueba y producción.