Implementación de puntos de conexión en línea para la inferencia en tiempo real
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
En este artículo se describen los puntos de conexión en línea para la inferencia en tiempo real en Azure Machine Learning. La inferencia es el proceso de aplicar nuevos datos de entrada a un modelo de Machine Learning para generar salidas. Azure Machine Learning permite realizar inferencia en tiempo real en los datos usando modelos que están implementados en puntos de conexión en línea. Aunque estas salidas se suelen denominar predicciones, puede usar la inferencia para generar salidas para otras tareas de aprendizaje automático, como la clasificación y la agrupación en clústeres.
Puntos de conexión en línea
Los puntos de conexión en línea implementan modelos en un servidor web que pueden devolver predicciones con el protocolo HTTP. Los puntos de conexión en línea pueden poner en marcha modelos para la inferencia en tiempo real en solicitudes sincrónicas, de baja latencia y se usan mejor cuando:
- Tiene requisitos de baja latencia.
- El modelo puede responder a la solicitud en un período de tiempo relativamente corto.
- Las entradas del modelo se ajustan a la carga HTTP de la solicitud.
- Debe escalar verticalmente el número de solicitudes.
Para definir un punto de conexión, debe especificar:
- Nombre del punto de conexión. Este nombre debe ser único en la región de Azure. Para conocer otros requisitos de nomenclatura, consulte Puntos de conexión en línea de Azure Machine Learning y puntos de conexión por lotes.
- Modo de autenticación. Puede elegir entre el modo de autenticación basado en claves, el modo de autenticación basado en tokens de Azure Machine Learning o la autenticación basada en tokens de Microsoft Entra para el punto de conexión. Para obtener más información sobre la autenticación, vea Autenticar clientes para puntos de conexión en línea.
Puntos de conexión en línea administrados
Los puntos de conexión en línea administrados implementan los modelos de aprendizaje automático de forma cómoda, llave en mano y son la manera recomendada de usar puntos de conexión en línea de Azure Machine Learning. Los puntos de conexión en línea administrados funcionan con máquinas eficaces de CPU y GPU en Azure de una manera escalable y totalmente administrada.
Estos puntos de conexión también se encargan de atender, escalar, proteger y supervisar los modelos, lo que le libera de la sobrecarga de configurar y administrar la infraestructura subyacente. Para obtener información sobre cómo definir un punto de conexión en línea administrado, consulte definir el punto de conexión.
Puntos de conexión en línea administrados frente a Azure Container Instances o Azure Kubernetes Service (AKS) v1
El uso de puntos de conexión en línea administrados es la manera recomendada de usar puntos de conexión en línea en Azure Machine Learning. En la tabla siguiente se resaltan los atributos clave de los puntos de conexión en línea administrados en comparación con Azure Container Instances y las soluciones de Azure Kubernetes Service (AKS) v1.
| Atributos | Puntos de conexión en línea administrados (v2) | Instancias de contenedor o AKS (v1) |
|---|---|---|
| Aislamiento y seguridad de red | Control de entrada y salida sencillo con alternancia rápida | No se admiten redes virtuales ni se requiere una configuración manual compleja. |
| Servicio administrado | • Aprovisionamiento o escalado de la capacidad de proceso totalmente administrados • Configuración de red para la prevención de la filtración de datos • Actualización del sistema operativo host, lanzamiento controlado de actualizaciones en contexto |
• El escalado está limitado • El usuario debe administrar la configuración o actualización de la red |
| Concepto de punto de conexión/implementación | La distinción entre punto de conexión e implementación permite escenarios complejos, como el lanzamiento seguro de modelos. | Ningún concepto de punto de conexión. |
| Diagnóstico y supervisión | • La depuración del punto de conexión local es posible con Docker y Visual Studio Code • Análisis avanzado de métricas y registros con gráfico o consulta para compararlos entre implementaciones • Desglose del costo hasta el nivel de implementación |
Sin depuración local sencilla. |
| Escalabilidad | Escalado elástico y automático (no enlazado por el tamaño predeterminado del clúster) | • Container Instances no es escalable • AKS (v1) solo admite el escalado en clúster y requiere que se configure la escalabilidad |
| Adecuado para empresas | Vínculo privado, claves administradas por el cliente, Microsoft Entra ID, administración de cuotas, integración de facturación, Acuerdo de Nivel de Servicio (SLA) | No compatible |
| Características avanzadas de ML | • Recopilación de datos de modelos • Supervisión de modelos • Modelo champion/challenger, implementación segura, reflejo del tráfico • Extensibilidad de IA responsable |
No compatible |
Puntos de conexión en línea administrados frente a puntos de conexión en línea de Kubernetes
Si prefiere usar Kubernetes para implementar los modelos y atender puntos de conexión, y se siente a gusto administrando los requisitos de infraestructura, puede usar puntos de conexión en línea de Kubernetes. Estos puntos de conexión de Kubernetes permiten implementar modelos y atender puntos de conexión en línea en un clúster de Kubernetes totalmente configurado y administrado en cualquier lugar, con CPU o GPU.
Los puntos de conexión en línea administrados pueden simplificar el proceso de implementación y proporcionan las siguientes ventajas sobre los puntos de conexión en línea de Kubernetes:
Administración automática de la infraestructura
- Aprovisiona el proceso y hospeda el modelo. Solo tiene que especificar el tipo de máquina virtual (VM) y la configuración de escalado.
- Actualiza y aplica revisiones a la imagen del sistema operativo del host subyacente.
- Realiza la recuperación del nodo si se produce un error del sistema.
Supervisión y registros
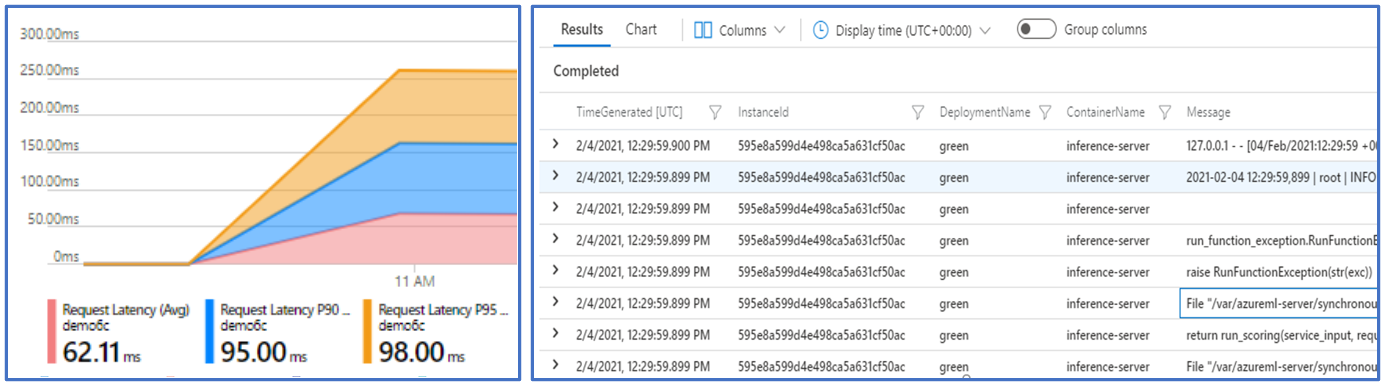
- Capacidad de supervisar la disponibilidad, el rendimiento y el Acuerdo de Nivel de Servicio del modelo mediante la integración nativa con Azure Monitor.
- Facilidad de depuración de implementaciones mediante registros e integración nativa con Log Analytics.
-

Nota:
Los puntos de conexión en línea administrados se basan en el proceso de Azure Machine Learning. Cuando se usa un punto de conexión en línea administrado, se pagan los cargos de proceso y redes. No hay ningún suplemento adicional. Para más información sobre precios, consulte Calculadora de precios de Azure.
Si usa una red virtual de Azure Machine Learning para proteger el tráfico saliente del punto de conexión en línea administrado, se le cobra por el vínculo privado de Azure y las reglas de salida de nombre de dominio completo (FQDN) que usa la red virtual administrada. Para más información, consulte Precios de la red virtual administrada.


En la tabla siguiente se resaltan las principales diferencias entre los puntos de conexión en línea administrados y los puntos de conexión en línea de Kubernetes.
| Puntos de conexión en línea administrados | Puntos de conexión en línea de Kubernetes (AKS v2) | |
|---|---|---|
| Usuarios recomendados | Usuarios que desean una implementación de modelo administrada y una experiencia de MLOps mejorada | Usuarios que prefieren Kubernetes y pueden autoadministrar los requisitos de infraestructura |
| Aprovisionamiento de nodos | Aprovisionamiento, actualización y eliminación de procesos administrados | Responsabilidad del usuario |
| Mantenimiento de nodos | Actualizaciones de imágenes del sistema operativo del host administradas y refuerzo de la seguridad | Responsabilidad del usuario |
| Ajuste de tamaño del clúster (escalado) | Administración manual y autoescalado para el aprovisionamiento de nodos adicionales | Escalado manual y automático, compatible con el escalado del número de réplicas dentro de los límites fijos del clúster |
| Compute type (Tipo de proceso) | Administrado por el servicio | Clúster de Kubernetes administrado por el cliente |
| Identidad administrada | Compatible | Compatible |
| Red virtual | Se admite a través del aislamiento de red administrada | Responsabilidad del usuario |
| Supervisión y registro integrados | Con tecnología de Azure Monitor y Log Analytics, incluidas métricas clave y tablas de registro para puntos de conexión e implementaciones | Responsabilidad del usuario |
| Registro con Application Insights ( heredado) | Compatible | Compatible |
| Vista costo | Detallado al punto de conexión o nivel de implementación | Nivel de clúster |
| Costos aplicados a | Máquinas virtuales (VM) asignadas a la implementación | Máquinas virtuales asignadas al clúster |
| Tráfico reflejado | Compatible | No compatible |
| Implementación sin código | Admite modelos MLflow y Triton | Admite modelos MLflow y Triton |
Implementaciones en línea
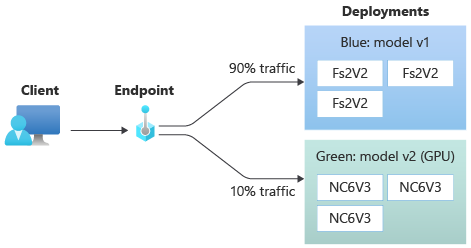
Una implementación es un conjunto de recursos y procesos necesarios para hospedar el modelo que realiza la inferencia. Un único punto de conexión puede contener varias implementaciones con diferentes configuraciones. Esta configuración ayuda a desacoplar la interfaz presentada por el punto de conexión a partir de los detalles de implementación existentes en la implementación. Un punto de conexión en línea tiene un mecanismo de enrutamiento que puede dirigir las solicitudes a implementaciones específicas en el punto de conexión.
En el siguiente diagrama se muestra un punto de conexión en línea que tiene dos implementaciones, azul y verde. En la implementación azul se usan máquinas virtuales con una SKU de CPU y ejecuta la versión 1 de un modelo. En la implementación verde se usan máquinas virtuales con una SKU que tiene GPU y se ejecuta la versión 2 del modelo. El punto de conexión está configurado para dirigir el 90 % del tráfico entrante a la implementación azul, mientras que la verde recibe el 10 % restante.
Para implementar un modelo debe tener:
Archivos de modelo, o el nombre y la versión de un modelo ya registrado en el área de trabajo.
Un script de puntuación, es decir, el código que ejecuta el modelo en una solicitud de entrada determinada.
El script de puntuación recibe los datos enviados a un servicio web implementado y los pasa al modelo. A continuación, el script ejecuta el modelo y devuelve su respuesta al cliente. El script de puntuación es específico para el modelo y debe entender los datos que el modelo espera como entrada y devuelve como salida.
Un entorno para ejecutar el modelo. El entorno puede ser una imagen de Docker con dependencias de Conda o un archivo Dockerfile.
Configuración para especificar el tipo de instancia y la capacidad de escalado.
Para obtener información sobre cómo implementar puntos de conexión en línea mediante la CLI de Azure, el SDK de Python, Azure Machine Learning Studio o una plantilla de ARM, consulte Implementación de un modelo de Machine Learning mediante un punto de conexión en línea.
Atributos clave de una implementación
En la tabla siguiente, se describen los atributos clave de una implementación:
| Atributo | Description |
|---|---|
| Nombre | Nombre de la implementación. |
| El nombre del punto de conexión | El nombre del punto de conexión en el que se creará la implementación. |
| Modelo | Modelo que se usará para la implementación. Este valor puede ser una referencia a un modelo con versiones existente en el área de trabajo o una especificación de modelo en línea. Para obtener más información sobre cómo realizar un seguimiento y especificar la ruta de acceso al modelo, consulte Especificar el modelo que se va a implementar para su uso en el punto de conexión en línea. |
| Ruta de acceso al código | Ruta de acceso al directorio en el entorno de desarrollo local que contiene todo el código fuente de Python para puntuar el modelo. Puede usar directorios y paquetes anidados. |
| Script de puntuación | La ruta de acceso relativa al archivo de puntuación en el directorio de código fuente. Este código de Python debe tener una función init() y una función run(). Se llama a la función init() después de crear o actualizar el modelo, por ejemplo, para almacenar en caché el modelo en memoria. Se llama a la función run() en cada invocación del punto de conexión para realizar la puntuación o predicción reales. |
| Entorno | Entorno para hospedar el modelo y el código. Este valor puede ser una referencia a un entorno con versiones existente en el área de trabajo o una especificación de entorno en línea. |
| Tipo de instancia | Tamaño de máquina virtual que se usará para la implementación. Para la lista de tamaños admitidos, consulte Lista de SKU de puntos de conexión en línea administrados. |
| Recuento de instancias | El número de instancias que se usarán para la implementación. Base el valor en la carga de trabajo esperada. Para lograr una alta disponibilidad, establezca el valor en al menos 3. El sistema reserva un 20 % adicional para realizar actualizaciones. Para más información, consulte Asignación de cuota de máquina virtual para implementaciones. |
Notas de las implementaciones en línea
La implementación puede hacer referencia al modelo y a la imagen de contenedor definida en Entorno en cualquier momento, por ejemplo, cuando las instancias de implementación se someten a revisiones de seguridad u otras operaciones de recuperación. Si usa un modelo registrado o una imagen de contenedor en Azure Container Registry para la implementación y quita el modelo o la imagen de contenedor, las implementaciones que dependen de estos recursos pueden producir un error al volver a crear la imagen. Si quita el modelo o la imagen de contenedor, asegúrese de volver a crear o actualizar las implementaciones dependientes con un modelo o imagen de contenedor alternativos.
El registro de contenedor al que hace referencia el entorno solo puede ser privado si la identidad del punto de conexión tiene permiso para acceder a él a través de la autenticación de Microsoft Entra y control de acceso basado en rol (RBAC) de Azure. Por el mismo motivo, no se admiten registros privados de Docker distintos de Container Registry.
Microsoft aplica revisiones periódicas de las vulnerabilidades de seguridad conocidas a las imágenes base. Debe volver a implementar el punto de conexión para usar la imagen revisada. Si proporciona su propia imagen, es usted el responsable de actualizarla. Para más información, consulte Aplicación de revisiones de imágenes.
Asignación de cuota de máquina virtual para la implementación
En el caso de los puntos de conexión en línea administrados, Azure Machine Learning reserva el 20 % de los recursos de proceso para realizar actualizaciones en algunas SKU de máquina virtual. Si solicita un número determinado de instancias para esas SKU de máquina virtual en una implementación, debe tener una cuota de ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU disponible para evitar que se produzca un error. Por ejemplo, si solicitas 10 instancias de una máquina virtual Standard_DS3_v2 (que incluye 4 núcleos) en una implementación, deberías tener disponible una cuota de 48 núcleos (12 instances * 4 cores). Esta cuota adicional está reservada para operaciones iniciadas por el sistema, como actualizaciones del sistema operativo, la recuperación de máquinas virtuales, y no incurrirá en costes a menos que se ejecute dicha operación.
Hay determinadas SKU de máquina virtual que están exentas de la reserva de cuota adicional. Para ver la lista completa, consulte Lista de SKU de puntos de conexión en línea administrados. Para ver el uso y los aumentos de cuota de solicitud, consulte Ver el uso y las cuotas en Azure Portal. Para ver el coste de ejecutar un punto de conexión en línea administrado, consulta Ver costes de punto de conexión en línea administrado.
Grupo de cuotas compartido
Azure Machine Learning proporciona un grupo de cuotas compartido desde el que los usuarios de varias regiones pueden acceder a la cuota para realizar pruebas durante un tiempo limitado, en función de la disponibilidad. Cuando se usa Studio para implementar modelos Llama-2, Phi, Nemotron, Mistral, Dolly y Deci-Deci-DeciLM desde el catálogo de modelos en un punto de conexión en línea administrado, Azure Machine Learning le permite acceder a su grupo de cuotas compartidas durante un breve tiempo para poder realizar pruebas. Para más información sobre el grupo de cuotas compartidas, consulte Cuota compartida de Azure Machine Learning.
Para implementar modelos Llama-2, Phi, Nemotron, Mistral, Dolly y Deci-DeciLM desde el catálogo de modelos a través de la cuota compartida, debe tener una suscripción de Contrato Enterprise. Para obtener más información sobre cómo usar la cuota compartida para la implementación de puntos de conexión en línea, consulte Implementación de modelos básicos mediante Studio.
Para obtener más información sobre las cuotas y los límites de los recursos de Azure Machine Learning, consulte Administración y aumento de cuotas y límites para recursos con Azure Machine Learning.
Implementación para codificadores y no codificadores
Azure Machine Learning admite la implementación de modelos en puntos de conexión en línea para codificadores y no codificadores, ya que proporciona opciones para la implementación sin código, la implementación con poco código y la implementación BYOC (Bring Your Own Container).
- La implementación sin código proporciona inferencia integrada para marcos comunes como scikit-learn, TensorFlow, PyTorch y Open Neural Network Exchange (ONNX) a través de MLflow y Triton.
- La implementación con poco código le permite proporcionar un mínimo de código junto con el modelo de Machine Learning para la implementación.
- La implementación BYOC le permite aportar virtualmente contenedores para ejecutar el punto de conexión en línea. Puede usar todas las características de la plataforma Azure Machine Learning, como la escalabilidad automática, GitOps, la depuración y el lanzamiento seguro para administrar las canalizaciones de MLOps.
En la tabla siguiente se indican los aspectos clave de las opciones de implementación en línea:
| Sin código | Con poco código | BYOC | |
|---|---|---|---|
| Resumen | Usa inferencia integrada para marcos populares, como scikit-learn, TensorFlow, PyTorch y ONNX, a través de MLflow y Triton. Para más información, consulte Implementación de modelos de MLflow en puntos de conexión en línea. | Usa imágenes mantenidas públicas para marcos populares, con actualizaciones cada dos semanas para solucionar vulnerabilidades. Usted proporciona el script de puntuación o las dependencias de Python. Para más información, consulte Entornos mantenidos de Azure Machine Learning. | Usted proporciona la pila completa a través de la compatibilidad de Azure Machine Learning con imágenes personalizadas. Para más información, consulte Uso de un contenedor personalizado para implementar un modelo en un punto de conexión en línea. |
| Imagen base personalizada | Ninguno. Los entornos mantenidos proporcionan la imagen base para facilitar la implementación. | Puede usar una imagen seleccionada o una imagen personalizada. | Traiga una ubicación de imagen de contenedor accesible, como docker.io, Container Registry o Microsoft Artifact Registry, o un Dockerfile que pueda compilar o insertar con Container Registry para el contenedor. |
| Dependencias personalizadas | Ninguno. Los entornos mantenidos proporcionan dependencias para facilitar la implementación. | Traiga el entorno de Azure Machine Learning en el que se ejecuta el modelo, una imagen de Docker con dependencias de Conda o un Dockerfile. | Las dependencias personalizadas se incluyen en la imagen de contenedor. |
| Código personalizado | Ninguno. El script de puntuación se genera automáticamente para facilitar la implementación. | Traiga su script de puntuación. | El script de puntuación se incluye en la imagen de contenedor. |
Nota:
Las ejecuciones de AutoML crean automáticamente un script de puntuación y dependencias para los usuarios. Para la implementación sin código, puede implementar cualquier modelo de AutoML sin crear otro código. Para la implementación con poco código, puede modificar los scripts generados automáticamente a sus necesidades empresariales. Para aprender a implementar con modelos de AutoML, consulte Implementación de un modelo AutoML en un punto de conexión en línea.
Depuración de puntos de conexión en línea
Si es posible, ejecute el punto de conexión localmente para validar y depurar el código y la configuración antes de implementarlo en Azure. La CLI de Azure y el SDK de Python admiten puntos de conexión e implementaciones locales, mientras que las plantillas de ARM y Estudio de Azure Machine Learning, no.
Azure Machine Learning proporciona varias formas de depurar puntos de conexión en línea en modo local y mediante registros de contenedor:
- Depuración local con el servidor HTTP de inferencia de Azure Machine Learning
- Depuración local con punto de conexión local
- Depuración local con punto de conexión local y Visual Studio Code
- Depuración con registros de contenedor
Depuración local con el servidor HTTP de inferencia de Azure Machine Learning
Puede depurar el script de puntuación localmente usando el servidor HTTP de inferencia de Azure Machine Learning. El servidor HTTP es un paquete de Python que expone la función de puntuación como un punto de conexión HTTP y encapsula el código y las dependencias del servidor Flask en un mismo paquete.
Azure Machine Learning incluye un servidor HTTP en las imágenes de Docker precompiladas para la inferencia que se usa para implementar un modelo. El uso del paquete por sí solo le permite implementar el modelo localmente para la producción, y también puede validar fácilmente su script de puntuación (entrada) en un entorno de desarrollo local. Si hay un problema con el script de puntuación, el servidor devolverá un error y la ubicación donde se produjo el error. También puede usar Visual Studio Code para la depuración con el servidor HTTP de inferencia de Azure Machine Learning.
Sugerencia
Puede usar el paquete de Python del servidor HTTP de inferencia de Azure Machine Learning para depurar el script de puntuación localmente sin Docker Engine. La depuración con el servidor de inferencia le ayuda a depurar el script de puntuación antes de implementar en los puntos de conexión locales para que pueda depurar sin verse afectado por las configuraciones del contenedor de implementación.
Para más información sobre la depuración con el servidor HTTP, consulte Depuración del script de puntuación con el servidor HTTP de inferencia de Azure Machine Learning.
Depuración local con punto de conexión local
Para la depuración local, necesita un modelo implementado en un entorno de Docker local. Puede usar esta implementación local para probar y depurar el punto de conexión antes de implementarlo en la nube.
Para la implementación local, debe tener instalado y en ejecución el motor de Docker. Después, Azure Machine Learning crea una imagen de Docker local para imitar la imagen en línea. Azure Machine Learning creará y ejecutará las implementaciones de forma local y almacenará en caché la imagen para lograr unas iteraciones rápidas.
Sugerencia
Si el motor de Docker no se inicia cuando se inicia el equipo, puede solucionar problemas del motor de Docker. Puede usar herramientas del lado cliente, como Docker Desktop para depurar lo que sucede en el contenedor.
La depuración local suele implicar los pasos siguientes:
- En primer lugar, compruebe que la implementación local se realizó correctamente.
- A continuación, invoque el punto de conexión local para la inferencia.
- Por último, revise los registros de salida de la operación
invoke.
Los puntos de conexión locales tienen las siguientes limitaciones:
No se admiten reglas de tráfico, autenticación ni configuración de sondeo.
Compatibilidad con solo una implementación por punto de conexión.
Compatibilidad solo con archivos de modelo local y entorno con el archivo conda local.
Para probar los modelos registrados, primero descárguelos mediante la CLI o el SDK y, después, use
pathen la definición de implementación para hacer referencia a la carpeta primaria.Para probar entornos registrados, compruebe el contexto del entorno en Estudio de Azure Machine Learning y prepare el archivo conda local para usarlo.
Para obtener más información sobre la depuración local, consulte Implementación y depuración locales mediante un punto de conexión local.
Depuración local con punto de conexión local y Visual Studio Code (versión preliminar)
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Al igual que con la depuración local, primero debe tener instalado y en ejecución el motor de Docker y, a continuación, implementar un modelo en el entorno de Docker local. Una vez que tenga una implementación local, los puntos de conexión locales de Azure Machine Learning usan contenedores de desarrollo de Docker y Visual Studio Code para compilar y configurar un entorno de depuración local.
Con los contenedores de desarrollo, puede aprovechar las características de Visual Studio Code, como la depuración interactiva, desde un contenedor de Docker. Para más información sobre la depuración interactiva de puntos de conexión en línea en Visual Studio Code, consulte Depuración de puntos de conexión en línea localmente en Visual Studio Code.
Depuración con registros de contenedor
No puede obtener acceso directo a una máquina virtual donde se implementa un modelo, pero puede obtener registros de los siguientes contenedores que se ejecutan en la máquina virtual:
- El registro de consola del servidor de inferencia contiene la salida de las funciones de impresión y registro del script del código de puntuación score.py.
- Inicializador de almacenamiento: estos registros contienen información sobre si el código y los datos del modelo se descargaron correctamente en el contenedor. El contenedor se ejecuta antes de que se inicie la ejecución del contenedor del servidor de inferencia.
Para más información sobre la depuración con registros de contenedor, consulte Obtención de registros de contenedor.
Enrutamiento y reflejo del tráfico en implementaciones en línea
Un único punto de conexión puede tener varias implementaciones. A medida que el punto de conexión recibe tráfico entrante (o solicitudes), puede dirigir porcentajes de tráfico a cada implementación, como se usa en la estrategia de implementación azul/verde nativa. Además, puede reflejar (o copiar) el tráfico de una implementación en otra, lo que también se denomina creación de reflejo o sesión concurrente del tráfico.
Enrutamiento del tráfico en una implementación azul/verde
La implementación azul/verde es una estrategia de implementación que permite llevar a cabo una nueva implementación (verde) en un pequeño subconjunto de usuarios o solicitudes antes de implementarla por completo. El punto de conexión puede implementar equilibrio de carga para asignar determinados porcentajes del tráfico a cada implementación, de modo que la suma total de las asignaciones de todas las implementaciones es el 100 %.
Sugerencia
Una solicitud puede omitir el equilibrio de carga de tráfico configurado incluyendo un encabezado HTTP de azureml-model-deployment. Establezca el valor de encabezado en el nombre de la implementación a la que desea enrutar la solicitud.
En la imagen siguiente se muestra la configuración en Estudio de Azure Machine Learning para asignar tráfico entre una implementación azul y una verde.
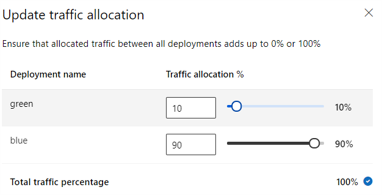
La asignación de tráfico anterior enruta el 10 % del tráfico a la implementación verde y el 90 % del tráfico a la implementación azul, como se muestra en la siguiente imagen.
Creación de reflejo del tráfico en implementaciones en línea
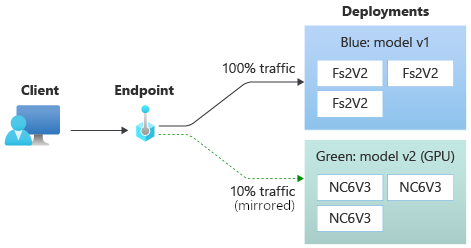
El punto de conexión también puede reflejar (o copiar) el tráfico de una implementación a otra. La creación de reflejo del tráfico (también denominada sesión concurrente de prueba) es útil cuando se desea probar una nueva implementación con tráfico de producción sin que afecte a los resultados que los clientes reciben de las implementaciones actuales.
Por ejemplo, una implementación azul/verde en la que el 100 % del tráfico se enruta a azul y un 10 % se refleja en la implementación verde. Con la creación de reflejo, los resultados del tráfico hacia la implementación verde no se devuelven a los clientes, pero se recopilan métricas y registros.
Para obtener más información sobre cómo usar la creación de reflejo del tráfico, consulte Implementación segura de nuevas implementaciones para la inferencia en tiempo real.
Más funcionalidades de punto de conexión en línea
En las secciones siguientes se describen otras funcionalidades de los puntos de conexión en línea de Azure Machine Learning.
Autenticación y cifrado
- Autenticación: claves y tokens de Azure Machine Learning
- Identidad administrada: asignada por el usuario y asignada por el sistema
- Capa de socket seguro (SSL) de forma predeterminada para la invocación de punto de conexión
Escalabilidad automática
El escalado automático ejecuta automáticamente la cantidad adecuada de recursos para controlar la carga en la aplicación. Los puntos de conexión administrados admiten el escalado automático mediante la integración con la característica de escalado automático de Azure Monitor. Puede configurar el escalado basado en métricas, como el uso de CPU del >70 %, el escalado basado en programación, como las reglas de horas laborables punta o ambas.

Para más información, consulte Escalabilidad automática de puntos de conexión en línea en Azure Machine Learning.
Aislamiento de red gestionada
Al implementar un modelo de Machine Learning en un punto de conexión en línea administrado, puede proteger la comunicación con el punto de conexión en línea mediante puntos de conexión privados. Puede configurar la seguridad para las solicitudes de puntuación de entrada y las comunicaciones salientes por separado.
Las comunicaciones entrantes usan el punto de conexión privado del área de trabajo de Azure Machine Learning, mientras que las comunicaciones salientes usan puntos de conexión privados creados para la red virtual administrada del área de trabajo. Para obtener más información, consulte Aislamiento de red con puntos de conexión en línea administrados.
Supervisión de los puntos de conexión en línea y las implementaciones
Los puntos de conexión de Azure Machine Learning se integran con Azure Monitor. La integración de Azure Monitor permite ver métricas en gráficos, configurar alertas, tablas de registro de consultas y usar Application Insights para analizar eventos de contenedores de usuarios. Para obtener más información, consulte Supervisión de los puntos de conexión en línea.
Inyección secreta en implementaciones en línea (versión preliminar)
La inserción de secretos para una implementación en línea implica recuperar secretos como claves de API de almacenes secretos e insertarlos en el contenedor de usuarios que se ejecuta dentro de la implementación. Para proporcionar un consumo secreto seguro para el servidor de inferencia que ejecuta el script de puntuación o la pila de inferencia en la implementación BYOC, puede usar variables de entorno para acceder a secretos.
Puede insertar secretos usted mismo, mediante identidades administradas, o puede usar la característica de inserción de secretos. Para obtener más información, consulte Inserción de secretos en puntos de conexión en línea (versión preliminar).
Contenido relacionado
- Implementación y puntuación de un modelo de aprendizaje automático mediante un punto de conexión en línea
- Puntos de conexión por lotes
- Protección de los puntos de conexión en línea administrados con aislamiento de red
- Implementación de modelos con REST
- Supervisión de los puntos de conexión en línea
- Visualización de los costos de un punto de conexión en línea administrado de Azure Machine Learning
- Administración y aumento de cuotas y límites para recursos con Azure Machine Learning