Aprendizaje profundo con la previsión de AutoML
Este artículo se centra en los métodos de aprendizaje profundo para la previsión de series temporales en AutoML. Encontrará instrucciones y ejemplos para entrenar modelos de previsión en AutoML en nuestro artículo configuración de AutoML para la previsión de series temporales.
El aprendizaje profundo tiene numerosos casos de uso que van desde el modelado del lenguaje hasta el plegado de proteínas, entre muchos otros. La previsión de series temporales también se beneficia de los avances recientes en la tecnología de aprendizaje profundo. Por ejemplo, los modelos de red neuronal profunda (DNN) se presentan de forma destacada en los modelos de alto rendimiento de la cuarta y quinta iteraciones de la competición de previsión de Makridakis de perfil alto.
En este artículo, describimos la estructura y el funcionamiento del modelo TCNForecaster en AutoML para ayudarle a aplicar mejor el modelo a su escenario.
Introducción a TCNForecaster
TCNForecaster es una red convolucional temporal, o TCN, que tiene una arquitectura de DNN diseñada para datos de series temporales. El modelo usa datos históricos para una cantidad objetivo, junto con las características relacionadas, para realizar previsiones probabilísticas del objetivo hasta un horizonte de previsión especificado. En la imagen siguiente, se muestran los principales componentes de la arquitectura de TCNForecaster:
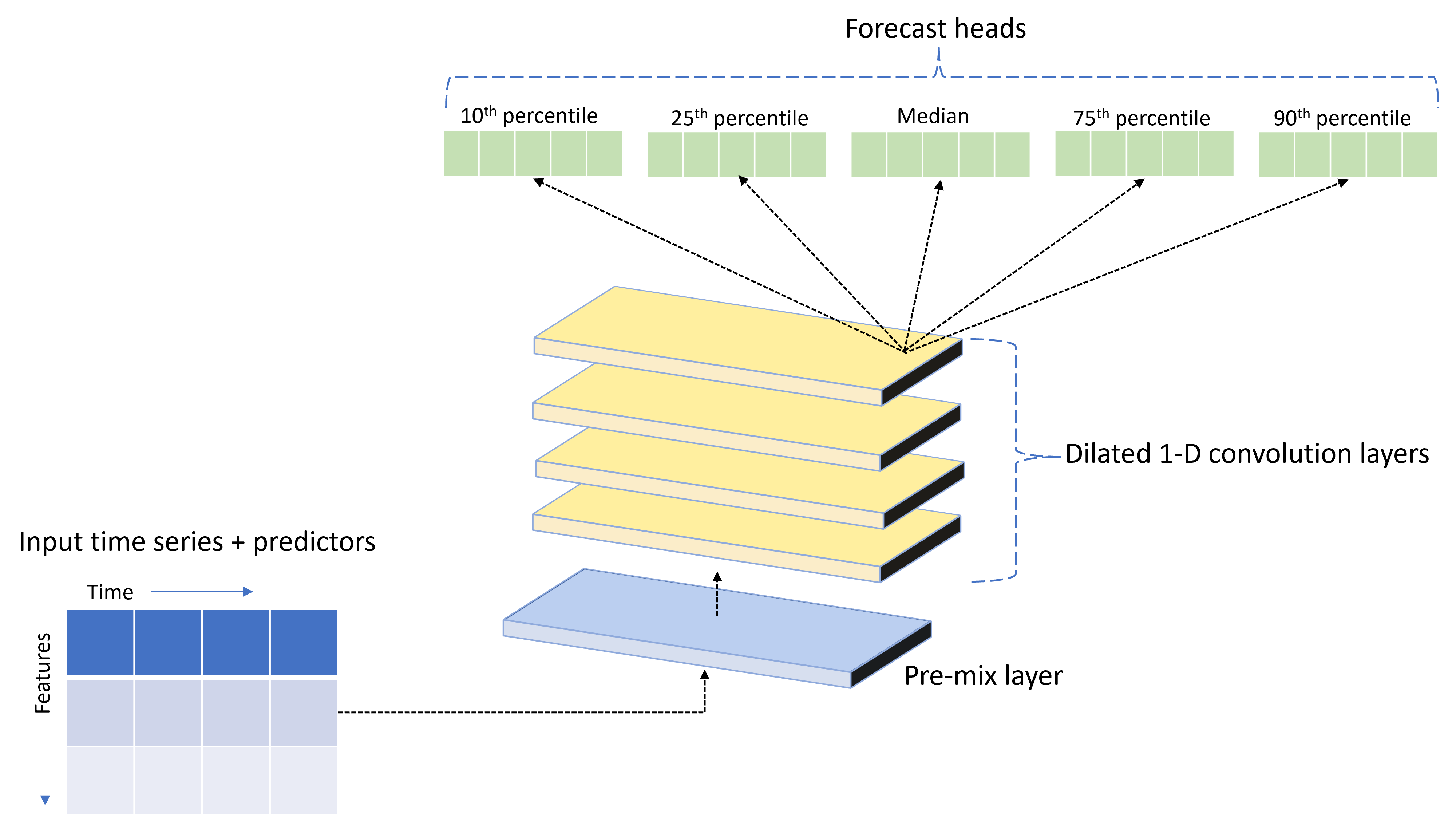
TCNForecaster consta de los siguientes componentes principales:
- Una capa de combinación previa que combina los datos de características y series temporales de entrada en una matriz de canales de señal que procesa la pila convolucional.
- Una pila de capas de convolución dilatada que procesa la matriz de canales secuencialmente; cada capa de la pila procesa la salida de la capa anterior para generar una nueva matriz de canales. Cada canal de esta salida contiene una combinación de señales filtradas mediante convolución de los canales de entrada.
- Colección de unidades principales de previsión que fusiona las señales de salida de las capas de convolución y genera previsiones de la cantidad objetivo a partir de esta representación latente. Cada unidad principal genera previsiones hasta el horizonte de un cuantil de la distribución de la predicción.
Convolución causal dilatada
La operación central de una TCN es una convolución causal dilatada a lo largo de la dimensión del tiempo de una señal de entrada. Intuitivamente, la convolución combina valores de puntos de tiempo cercanos en la entrada. Las proporciones de la mezcla son el kernel, o las ponderaciones, de la convolución, mientras que la separación entre puntos de la mezcla es la dilatación. La señal de salida se genera a partir de la entrada deslizando el kernel en el tiempo a lo largo de la entrada y acumulando la mezcla en cada posición. Una convolución causal es aquella en la que el kernel solo mezcla los valores de entrada en el pasado con respecto a cada punto de salida, lo que impide que la salida "examine" el futuro.
El apilamiento de convoluciones dilatadas proporciona a la TCN la capacidad de modelar correlaciones durante largas duraciones en señales de entrada con relativamente pocas ponderaciones del kernel. Por ejemplo, la imagen siguiente muestra tres capas apiladas con un kernel de dos ponderaciones en cada capa y factores de dilatación exponencialmente crecientes:
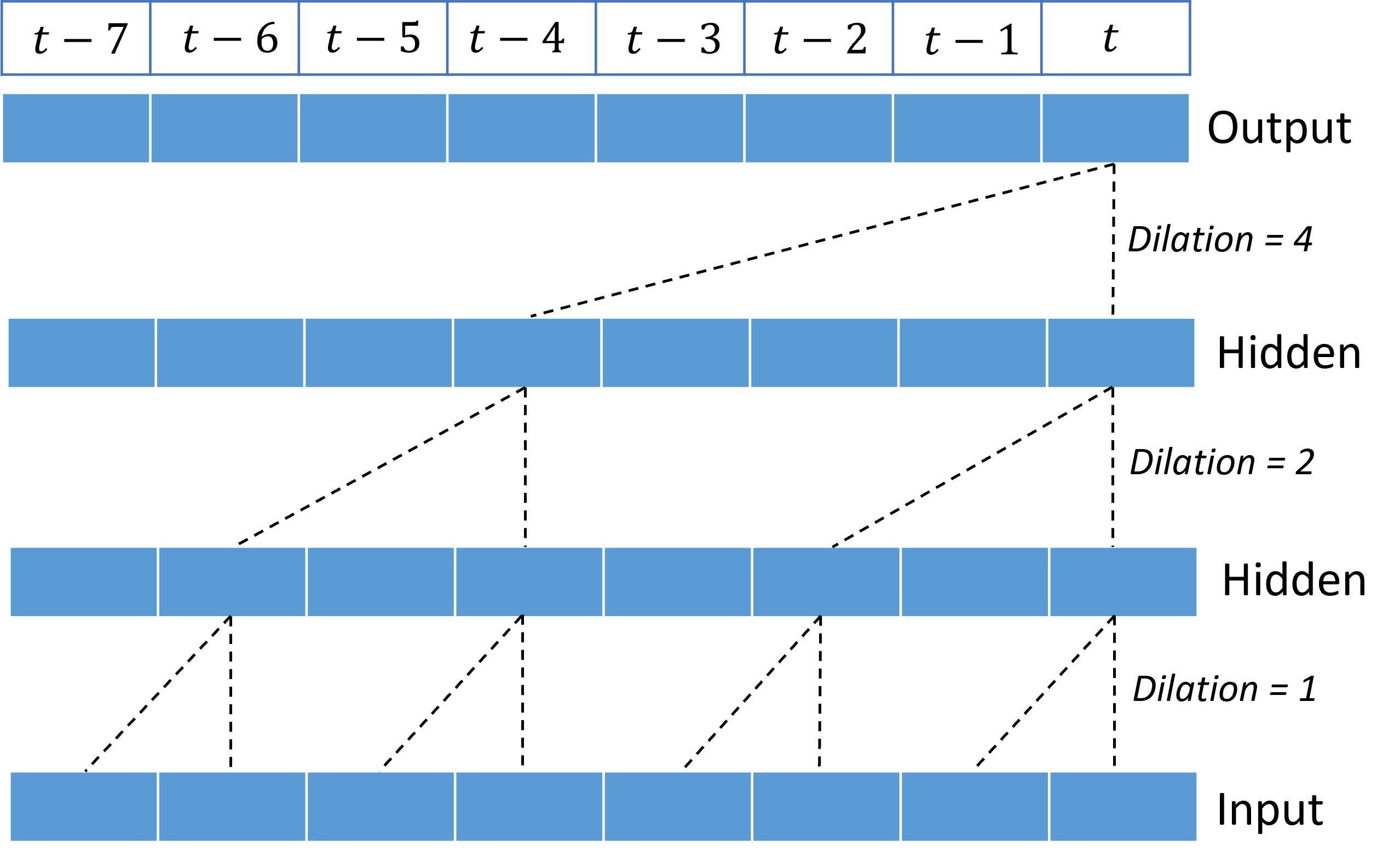
Las líneas discontinuas muestran rutas de acceso a través de la red que terminan en la salida en el tiempo $t$. Estas rutas de acceso cubren los últimos ocho puntos de la entrada, lo que ilustra que cada punto de salida es una función de los ocho puntos más recientes de la entrada. La longitud del historial, o "mirada hacia atrás", que usa una red convolucional para realizar predicciones se llama campo receptivo y está determinada por completo por la arquitectura de la TCN.
Arquitectura de TCNForecaster
El núcleo de la arquitectura de TCNForecaster es la pila de capas convolucionales entre la combinación previa y las unidades principales de la previsión. La pila se divide lógicamente en unidades repetidas llamadas bloques que, a su vez, se componen de celdas residuales. Una celda residual aplica convoluciones causales en una dilatación establecida junto con la normalización y la activación no lineal. De forma importante, cada celda residual agrega su salida a su entrada mediante la llamada conexión residual. Se ha demostrado que estas conexiones benefician el entrenamiento de la DNN, quizás porque facilitan un flujo de información más eficaz a través de la red. En la imagen siguiente, se muestra la arquitectura de las capas convolucionales de una red de ejemplo con dos bloques y tres celdas residuales en cada bloque:
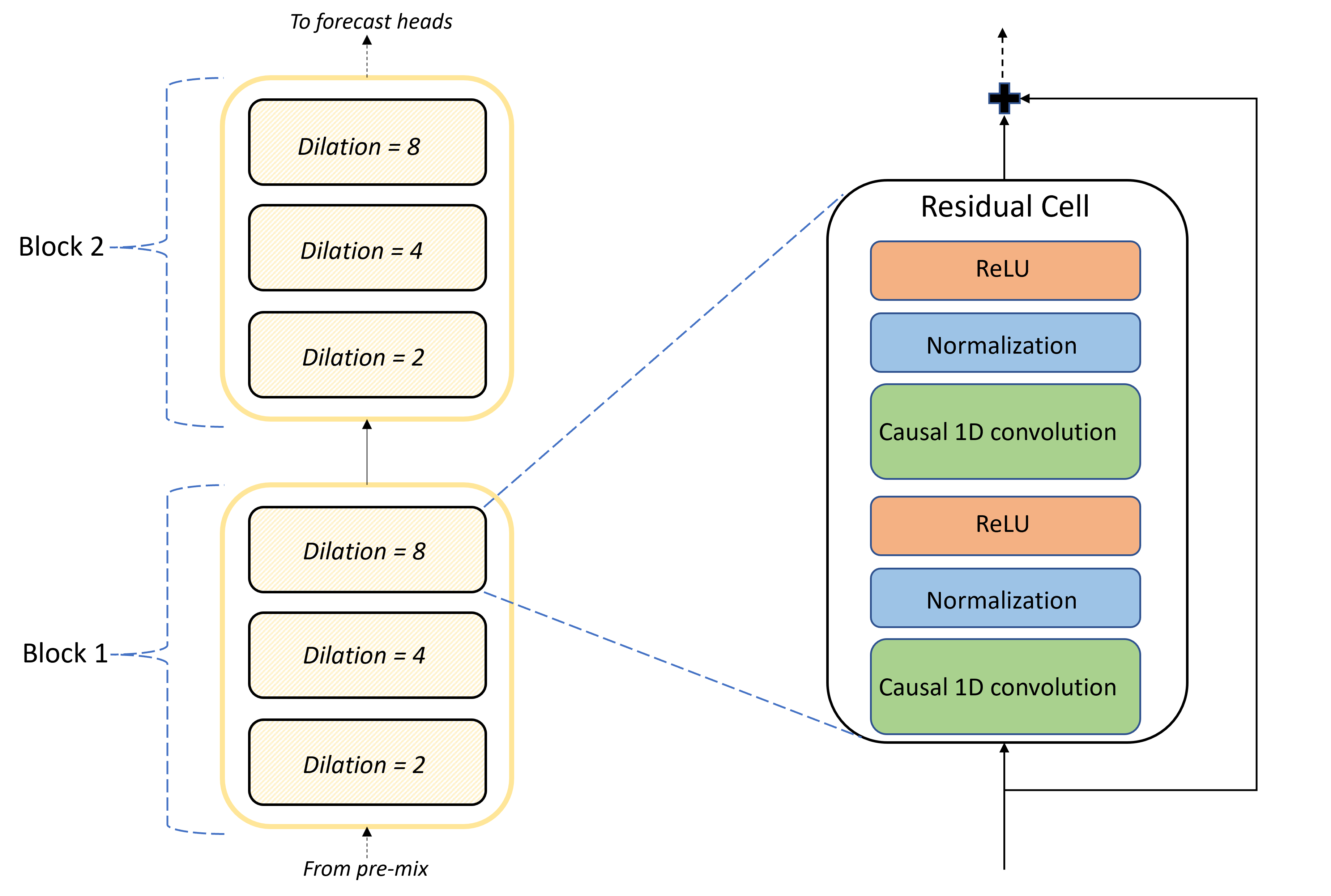
El número de bloques y celdas, junto con el número de canales de señal de cada capa, controlan el tamaño de la red. Los parámetros arquitectónicos de TCNForecaster se resumen en la tabla siguiente:
| Parámetro | Descripción |
|---|---|
| $n_{b}$ | Número de bloques de la red; también se llama profundidad |
| $n_{c}$ | Número de celdas de cada bloque |
| $n_{\text{ch}}$ | Número de canales en las capas ocultas |
El campo receptivo depende de los parámetros de profundidad y viene determinado por la fórmula:
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
Podemos dar una definición más precisa de la arquitectura de TCNForecaster en términos de fórmulas. Supongamos que $X$ es una matriz de entrada donde cada fila contiene valores de características de los datos de entrada. Podemos dividir $X$ en matrices de características numéricas y categóricas, $X_{\text{num}}$ y $X_{\text{cat}}$. por tanto, TCNForecaster viene dado por las fórmulas:
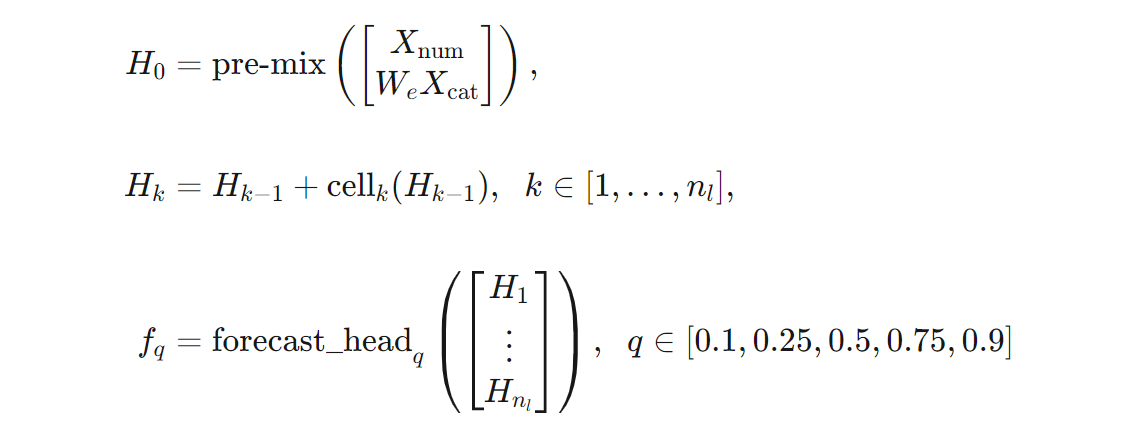
Donde $W_{e}$ es una matriz de inserción para las características de categorías, $n_{l} = n_{b}n_{c}$ es el número total de celdas residuales, $H_{k}$ denota salidas de las capa ocultas y $f_{q}$ son salidas de la previsión para cuantiles dados de la distribución de predicción. Para facilitar la comprensión, las dimensiones de estas variables se encuentran en la tabla siguiente:
| Variable | Descripción | Dimensions |
|---|---|---|
| $X$ | Matriz de entrada | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Salida de la capa oculta para $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Salida de la previsión del cuantil $q$ | $h$ |
En la tabla, $n_{\text{input}} = n_{\text{features}} + 1$, el número de variables de predicción/características más la cantidad objetivo. Las unidades principales de la previsión generan todas las previsiones hasta el horizonte máximo, $h$, en un solo paso, por lo que TCNForecaster es de pronóstico directo.
TCNForecaster en AutoML
TCNForecaster es un modelo opcional de AutoML. Para aprender a usarlo, consulte Habilitación del aprendizaje profundo.
En esta sección, describimos cómo crea AutoML los modelos de TCNForecaster con los datos, incluidas las explicaciones del preprocesamiento de datos, el entrenamiento y la búsqueda de modelos.
Pasos de preprocesamiento de datos
AutoML ejecuta varios pasos de preprocesamiento en los datos para prepararse para el entrenamiento del modelo. En la tabla siguiente, se describen estos pasos en el orden en que se realizan:
| Paso | Descripción |
|---|---|
| Rellenar los datos que faltan | Imputar los valores que faltan y los huecos de observación y, opcionalmente, rellenar o quitar las series temporales cortas |
| Crear características de calendario | Aumente los datos de entrada con características derivadas del calendario, como el día de la semana y, de manera opcional, los días festivos para una región o país específicos. |
| Codificar los datos categóricos | Codificar con etiquetas las cadenas y otros tipos categóricos; esto incluye todas las columnas de identificador de serie temporal. |
| Transformación objetivo | Opcionalmente, aplicar la función logaritmo natural al objetivo en función de los resultados de determinadas pruebas estadísticas. |
| Normalización | Normalizar con puntuación Z todos los datos numéricos; La normalización se realiza por característica y por grupo de series temporales, tal como se define en las columnas de identificador de serie temporal. |
Estos pasos se incluyen en las canalizaciones de transformación de AutoML, por lo que se aplican automáticamente cuando es necesario en el momento de la inferencia. En algunos casos, la operación inversa de un paso se incluye en la canalización de inferencia. Por ejemplo, si AutoML aplicó una transformación $\log$ al objetivo durante el entrenamiento, se calcula el exponencial de las previsiones sin procesar en la canalización de inferencia.
Cursos
TCNForecaster sigue los procedimientos recomendados de entrenamiento de DNN comunes a otras aplicaciones en imágenes e idiomas. AutoML divide los datos de entrenamiento preprocesados en ejemplos que se ordenan aleatoriamente y se combinan en lotes. La red procesa los lotes secuencialmente, utilizando la propagación inversa y el descenso de gradiente estocástico para optimizar las ponderaciones de la red con respecto a una función de pérdida. El entrenamiento puede requerir muchos pasos en los datos de entrenamiento completos; cada paso se denomina época.
En la tabla siguiente, se enumeran y describen los parámetros y la configuración de entrada para el entrenamiento de TCNForecaster:
| Entrada de entrenamiento | Descripción | Valor |
|---|---|---|
| Datos de validación | Una parte de los datos que se mantienen fuera del entrenamiento para guiar la optimización de la red y mitigar el ajuste en exceso. | Proporcionado por el usuario o creado automáticamente a partir de los datos de entrenamiento si no se proporciona. |
| Métrica principal | Métrica calculada a partir de previsiones de valor medio en los datos de validación al final de cada época de entrenamiento; se usa para la detención temprana y la selección del modelo. | Elegida por el usuario; error cuadrático medio normalizado o error absoluto medio normalizado. |
| Épocas de entrenamiento | Número máximo de épocas que se ejecutarán para la optimización de la ponderación de la red. | 100; la lógica de detención temprana automatizada puede finalizar el entrenamiento en un número menor de épocas. |
| Paciencia de la detención temprana | Número de épocas que se deben esperar para la mejora de la métrica principal antes de que se detenga el entrenamiento. | 20 |
| Función de pérdida | Función objetivo para la optimización de la ponderación de la red. | Pérdida de cuantil promediada sobre las previsiones del percentil 10, 25, 50, 75 y 90. |
| Tamaño de lote | Número de ejemplos de un lote. Cada ejemplo tiene $n_{\text{input}} \times t_{\text{rf}}$ dimensiones para la entrada y $h$ para la salida. | Se determina automáticamente a partir del número total de ejemplos de los datos de entrenamiento; valor máximo de 1024. |
| Inserción de dimensiones | Dimensiones de los espacios de inserción para las características de categorías. | Se establece automáticamente en la raíz cuarta del número de valores distintos de cada característica, redondeado al entero más cercano. Los umbrales se aplican en un valor mínimo de 3 y un valor máximo de 100. |
| Arquitectura de la red* | Parámetros que controlan el tamaño y la forma de la red: profundidad, número de celdas y número de canales. | Determinado por la búsqueda de modelos. |
| Ponderaciones de la red | Parámetros que controlan las mezclas de señales, las inserciones de categorías, las ponderaciones del kernel de convolución y las asignaciones para los valores de la previsión. | Inicializado aleatoriamente y luego optimizado con respecto a la función de pérdida. |
| Velocidad de aprendizaje* | Controla cuánto se pueden ajustar las ponderaciones de la red en cada iteración del descenso de gradiente; reducción dinámica de la convergencia cercana. | Determinado por la búsqueda de modelos. |
| Tasa de abandono* | Controla el grado de regularización del abandono aplicada a las ponderaciones de la red. | Determinado por la búsqueda de modelos. |
Las entradas marcadas con un asterisco (*) se determinan mediante una búsqueda de hiperparámetros que se describe en la sección siguiente.
Búsqueda de modelos
AutoML usa métodos de búsqueda de modelos para buscar valores para los siguientes hiperparámetros:
- Profundidad de la red, o número de bloques convolucionales
- Número de celdas por bloque
- Número de canales en cada capa oculta
- Tasa de abandono para la regularización de red
- Velocidad de aprendizaje.
Los valores óptimos para estos parámetros pueden variar significativamente en función del escenario del problema y los datos de entrenamiento, por lo que AutoML entrena varios modelos diferentes dentro del espacio de valores de hiperparámetros y elige el mejor según la puntuación de la métrica principal sobre los datos de validación.
La búsqueda de modelos tiene dos fases:
- AutoML realiza una búsqueda en más de 12 modelos de "punto de referencia". Los modelos de punto de referencia son estáticos y se eligen para abarcar razonablemente el espacio de hiperparámetros.
- AutoML continúa buscando en el espacio de hiperparámetros con una búsqueda aleatoria.
La búsqueda finaliza cuando se cumplen los criterios de detención. Los criterios de detención dependen de la configuración del trabajo de entrenamiento de previsión, pero algunos ejemplos incluyen límites de tiempo, límites en el número de pruebas de búsqueda que se van a realizar y una lógica de detención temprana cuando la métrica de validación no mejora.
Pasos siguientes
- Obtenga información sobre la Configuración de AutoML para entrenar un modelo de previsión de series temporales con Python.
- Obtenga más información en Introducción a los métodos de previsión de ML automatizado.
- Consulte Respuestas a las preguntas más frecuentes sobre la previsión en AutoML.