Componente Entrenar modelo
En este artículo se describe un componente del diseñador de Azure Machine Learning.
Utilice este componente para entrenar un modelo de clasificación o regresión. El entrenamiento tiene lugar después de definir un modelo y establecer sus parámetros y requiere datos etiquetados. También puede usar Entrenar modelo para volver a entrenar un modelo existente con datos nuevos.
Funcionamiento del proceso de entrenamiento
En Azure Machine Learning, crear y usar un modelo suele ser un proceso de tres pasos.
Un modelo se configura eligiendo un determinado tipo de algoritmo y definiendo sus parámetros o hiperparámetros. Elija cualquiera de los siguientes tipos de modelo:
- Los modelos de clasificación, que se basan en redes neuronales, árboles de decisión y bosques de decisión, así como otros algoritmos.
- Los modelos de regresión, que pueden incluir la regresión lineal estándar o que usan otros algoritmos, incluidas las redes neuronales y la regresión bayesiana.
Proporcione un conjunto de datos que esté etiquetado y tenga datos compatibles con el algoritmo. Conecte los datos y el modelo a Entrenar modelo.
El entrenamiento produce un formato binario concreto, iLearner, que encapsula los patrones estadísticos aprendidos a partir de los datos. No se puede modificar o leer directamente este formato; sin embargo, otros componentes pueden usar el modelo entrenado.
También puede ver las propiedades del modelo. Para más información, consulte la sección Resultados.
Una vez que finalice el entrenamiento, use el modelo entrenado con uno de los componentes de puntuación para realizar predicciones sobre datos nuevos.
Procedimiento para usar Entrenar modelo
Agregue el componente Entrenar modelo a la canalización. Puede encontrar este componente en la categoría Machine Learning. Expanda Entrenar y luego arrastre el componente Entrenar modelo a la canalización.
En la entrada izquierda, adjunte el modo no entrenado. Adjunte el conjunto de datos de entrenamiento a la entrada de la derecha de Entrenar modelo.
El conjunto de datos de entrenamiento debe contener una columna de etiqueta. Se omiten todas las filas sin etiquetas.
En Columna de etiqueta, haga clic en Editar columna en el panel derecho del componente y elija una columna que contenga resultados que el modelo pueda usar para el entrenamiento.
Para problemas de clasificación, la columna de etiqueta debe contener valores categoriales o valores discretos. Algunos ejemplos podrían ser una calificación de sí o no, un código o nombre de clasificación de enfermedades o un grupo de ingresos. Si elige una columna no categórica, el componente devolverá un error durante el entrenamiento.
Para problemas de regresión, la columna de etiqueta debe contener datos numéricos que representen la variable de respuesta. Lo ideal es que los datos numéricos representen una escala continua.
Podrían ser ejemplos una puntuación de riesgo de crédito, el tiempo proyectado para el error de una unidad de disco duro o el número previsto de llamadas a un centro de llamadas en un día u hora determinadas. Si no elige una columna numérica, puede obtener un error.
- Si no especifica qué columna de etiqueta debe utilizar, Azure Machine Learning intentará inferir cuál es la columna de etiqueta adecuada usando los metadatos del conjunto de datos. Si elige la columna errónea, utilice el selector de columnas para corregirlo.
Sugerencia
Si tiene problemas para usar el selector de columnas, consulte el artículo Select Columns in Dataset (Seleccionar columnas en conjunto de datos) para obtener sugerencias. En él, se describen algunos escenarios y sugerencias comunes para usar las opciones WITH RULES (CON REGLAS) y BY NAME (POR NOMBRE).
Envíe la canalización. Si tiene muchos datos, la operación puede tardar.
Importante
Si tiene una columna de identificador que sea el identificador de cada fila o una columna de texto que contenga demasiados valores únicos, Train Model (Entrenar modelo) puede producir un error como "Number of unique values in colum: '{column_name}' is greater than allowed" (El número de valores únicos en la columna '{nombre_de_la_columna}' es mayor que lo permitido).
Esto se debe a que la columna de identificador alcanza el umbral de valores únicos y puede agotar la memoria. Puede utilizar Editar metadatos para marcar esa columna como Borrar característica y no se utilizará en el entrenamiento, o puede emplear el componente Extracción de características de n-gramas del texto para preprocesar la columna de texto. Consulte Códigos de error para el diseñador para más detalles sobre este error.
Interpretabilidad del modelo
La interpretabilidad del modelo ofrece la posibilidad de comprender el modelo de aprendizaje automático y de presentar la base subyacente para la toma de decisiones de una manera comprensible para los seres humanos.
Actualmente, el componente Entrenar modelo admite el uso del paquete de interpretabilidad para explicar los modelos de ML. Se admiten los siguientes algoritmos integrados:
- Regresión lineal
- Regresión de red neuronal
- Regresión ampliada del árbol de decisión
- Regresión de bosque de decisión
- Regresión de Poisson
- Regresión logística de dos clases
- Máquina de vectores de soporte de dos clases
- Árbol de decisión ampliado de dos clases
- Bosque de decisión de dos clases
- Bosque de decisión de varias clases
- Regresión logística de varias clases
- Red neuronal de varias clases
Para generar explicaciones del modelo, puede seleccionar Verdadero en la lista desplegable Explicación del modelo del componente Entrenar modelo. De manera predeterminada, se establece en Falso en el componente Entrenar modelo. Tenga en cuenta que la generación de una explicación requiere costos de proceso adicionales.
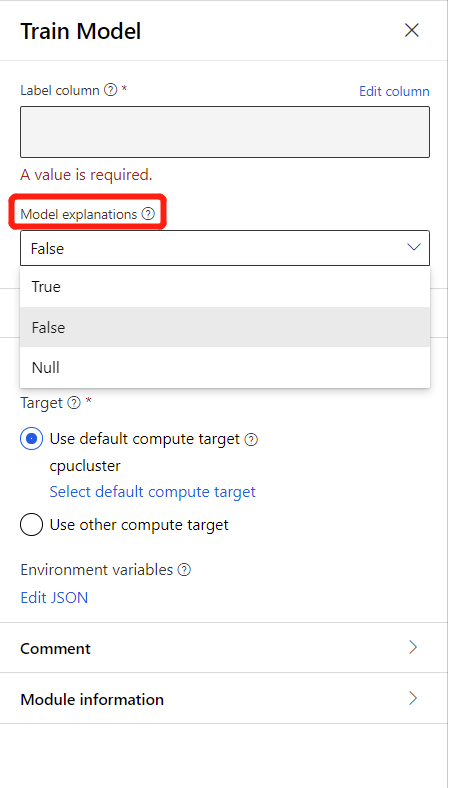
Una vez completada la ejecución de la canalización, puede visitar la pestaña Explicaciones en el panel derecho del componente Entrenar modelo y explorar el rendimiento del modelo, el conjunto de datos y la importancia de las características.
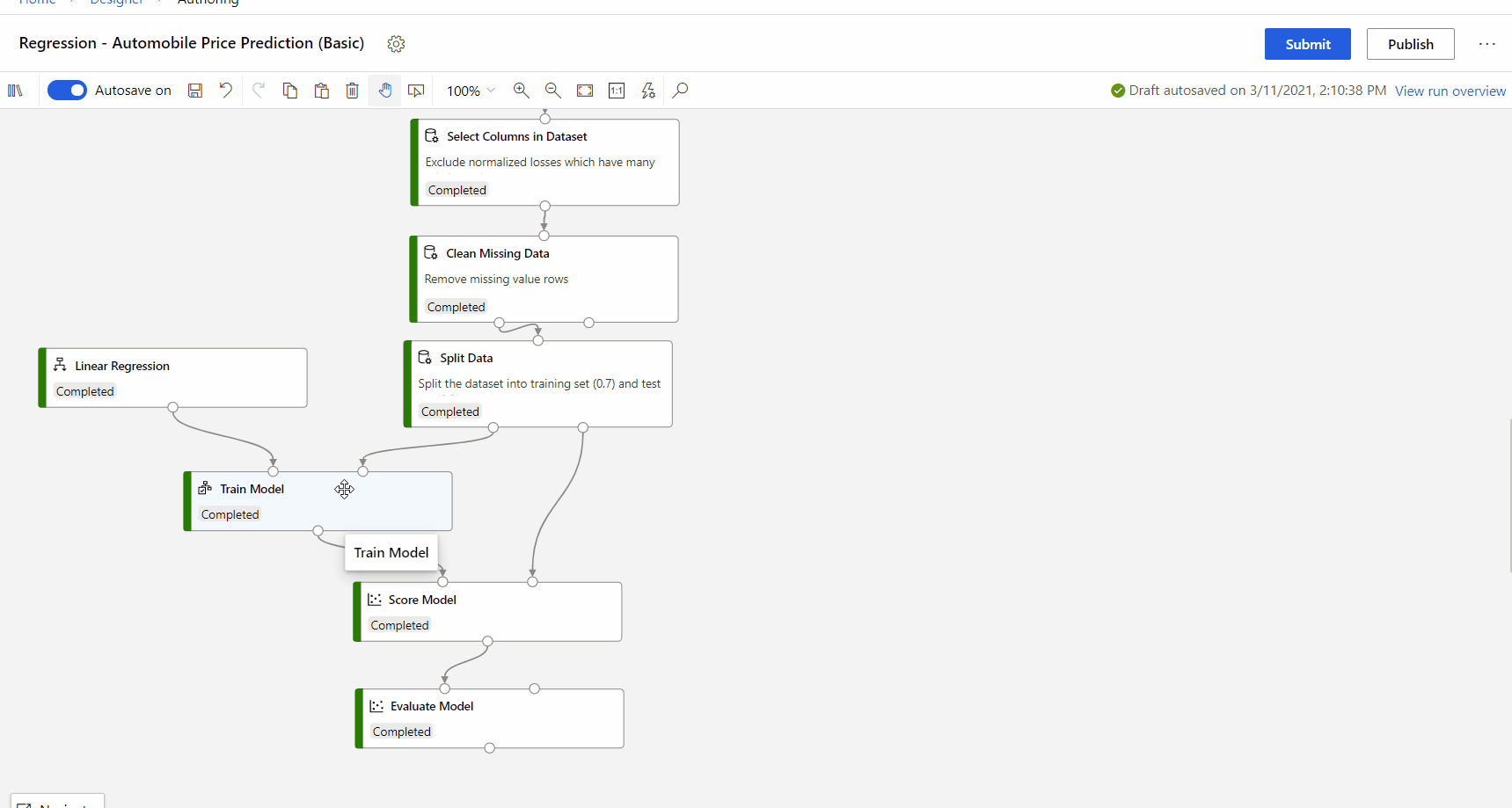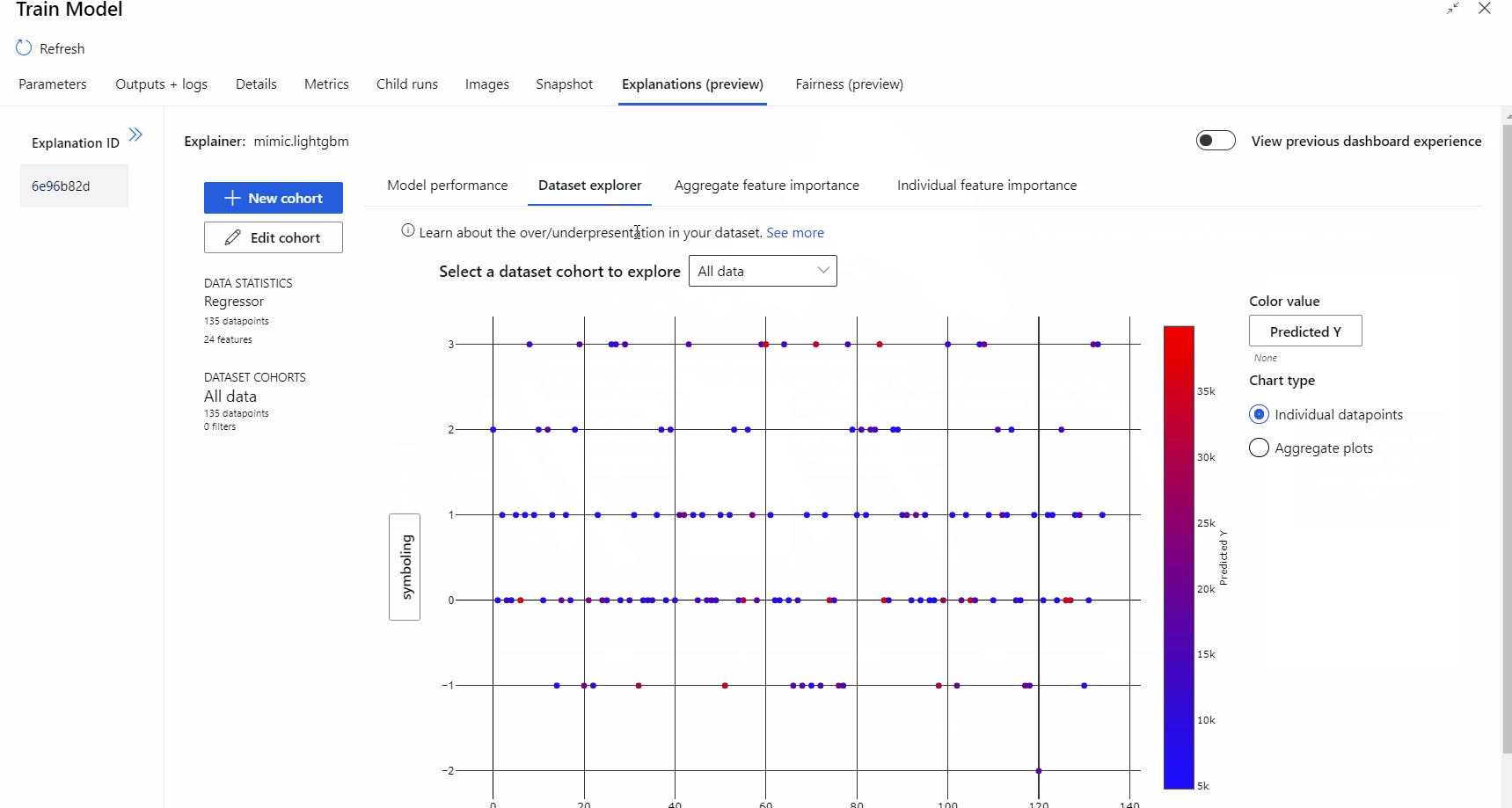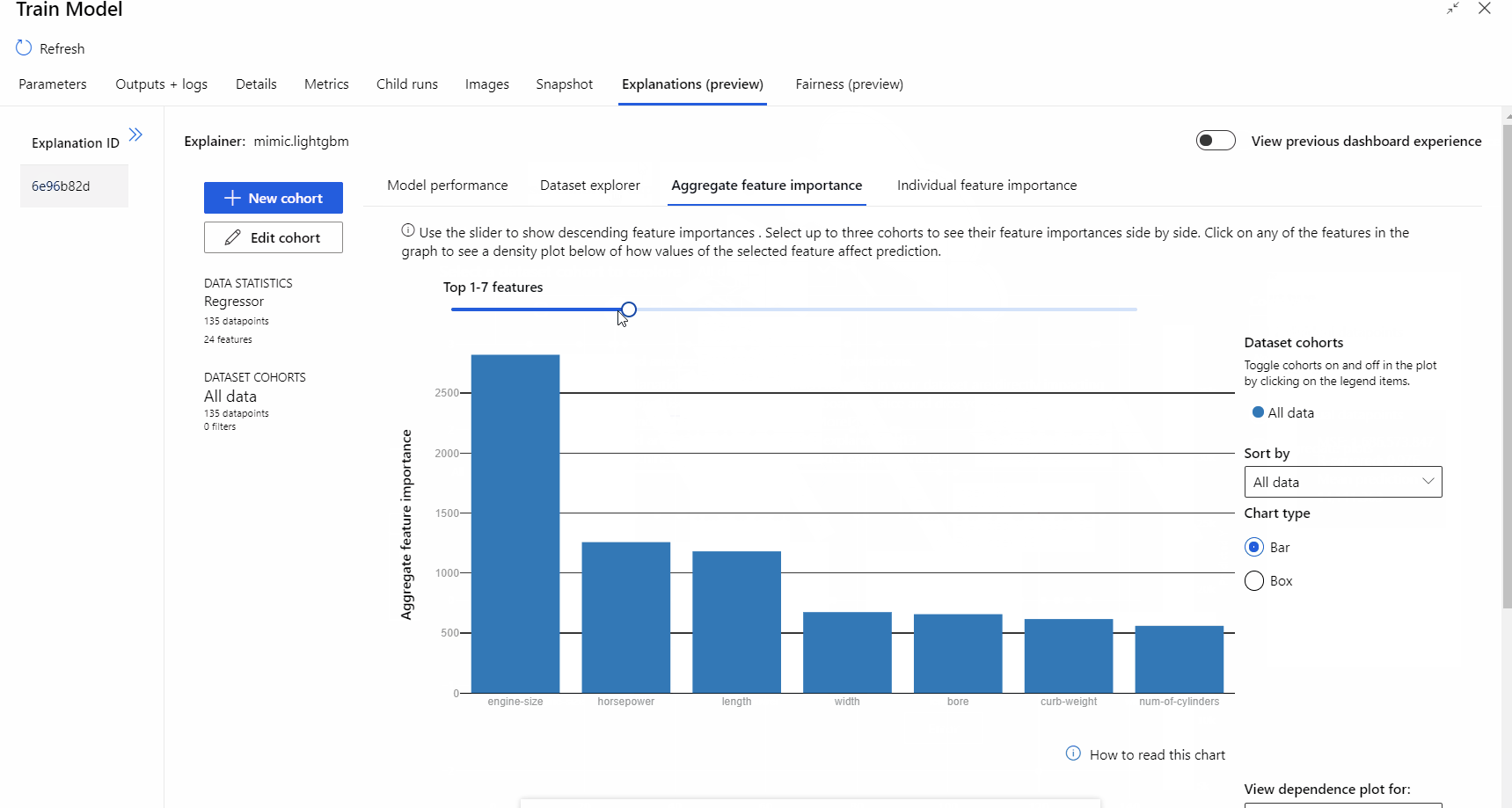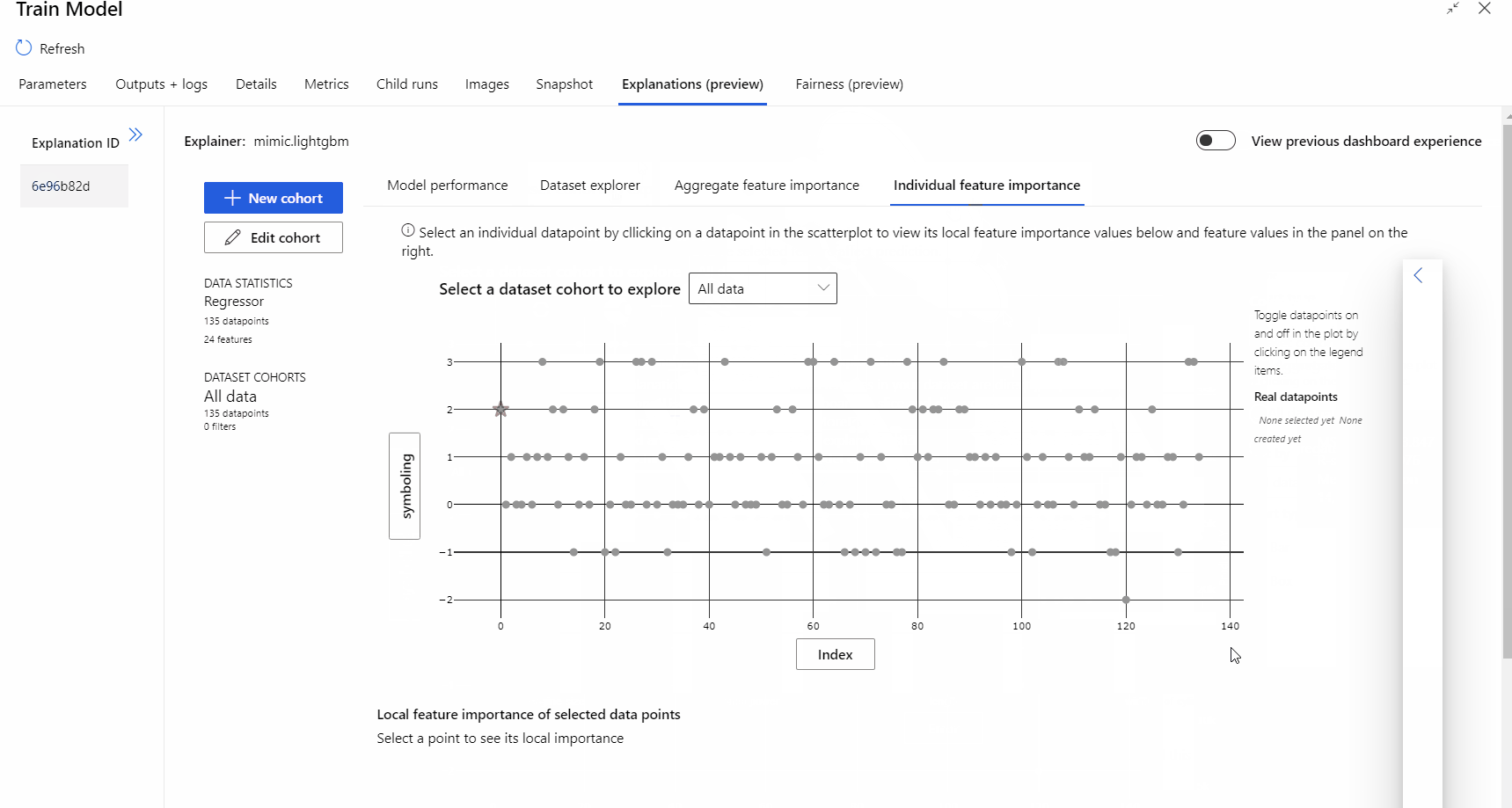
Para más información sobre el uso de las explicaciones del modelo en Azure Machine Learning, consulte el artículo de procedimientos sobre cómo interpretar los modelos de aprendizaje automático.
Results
Cuando el modelo está entrenado:
Para usar el modelo en otras canalizaciones, seleccione el componente y, después, seleccione el icono Registrar conjunto de datos en la pestaña Salidas del panel derecho. Puede acceder a los modelos guardados en la paleta de componentes en Conjuntos de datos.
Para usar el modelo para predecir nuevos valores, conéctelo al componente Puntuar modelo, junto con nuevos datos de entrada.
Pasos siguientes
Vea el conjunto de componentes disponibles para Azure Machine Learning.