Componente Ejecución de script de R
En este artículo se explica cómo usar el componente Ejecución de script de R para ejecutar código de R en la canalización del diseñador de Azure Machine Learning.
Con R puede realizar tareas que no son compatibles con los componentes existentes, como:
- Crear transformaciones de datos personalizadas
- Usar sus propias métricas para evaluar las predicciones
- Compilar modelos mediante algoritmos que no se han implementado como componentes independientes en el diseñador
Compatibilidad con la versión de R
El diseñador de Azure Machine Learning usa la distribución CRAN (red de archivo de R completa) de R. La versión que se usa actualmente es CRAN 3.5.1.
Paquetes de R admitidos
El entorno de R está preinstalado con más de 100 paquetes. Para obtener una lista completa, consulte la sección Paquetes preinstalados de R.
También puede agregar el código siguiente a cualquier componente Ejecución de script de R para ver los paquetes instalados.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Nota
Si la canalización contiene varios componentes Ejecución de script de R que necesitan paquetes que no están en la lista preinstalada, instale los paquetes en cada componente.
Instalación de paquetes de R
Para instalar paquetes de R adicionales, use el método install.packages(). Se instalan paquetes para cada componente Ejecución de script de R. No se comparten con otros componentes Ejecución de script de R.
Nota
NO se recomienda instalar el paquete de R desde la agrupación de scripts, sino hacerlo directamente en el editor de scripts.
Especifique el repositorio de CRAN al instalar paquetes, como install.packages("zoo",repos = "https://cloud.r-project.org").
Advertencia
El componente Ejecución de script de R no admite la instalación de paquetes que requieren compilación nativa, como el paquete qdap, que requiere JAVA, y el paquete drc, que requiere C++. Esto se debe a que este componente se ejecuta en un entorno preinstalado con permisos que no son de administrador.
No instale paquetes que estén precompilados en o para Windows, ya que los componentes del diseñador se ejecutan en Ubuntu. Para comprobar si un paquete está precompilado en Windows, puede ir a CRAN y buscar el paquete, descargar un archivo binario correspondiente a su sistema operativo y comprobar la parte Build: del archivo DESCRIPTION. El siguiente es un ejemplo: 
En este ejemplo se muestra cómo instalar Zoo:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Nota
Antes de instalar un paquete, compruebe si ya existe para no repetir una instalación. La repetición de instalaciones pueden hacer que se agote el tiempo de espera de las solicitudes de servicio web.
Acceso al conjunto de datos registrado
Puede consultar el siguiente código de ejemplo para acceder a los conjuntos de datos registrados en el área de trabajo:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Procedimiento para configurar Ejecutar script R
El componente Ejecución de script de R contiene código de ejemplo como punto de partida.
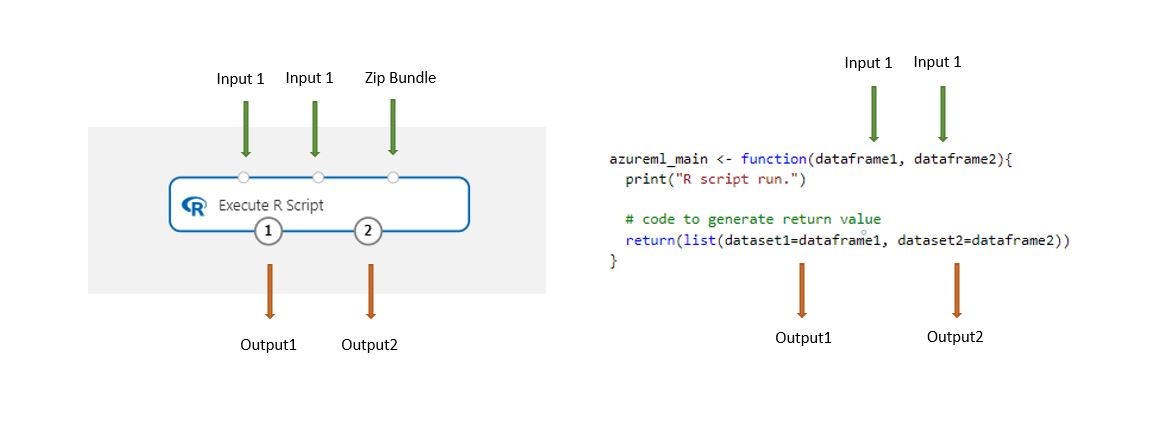
Los conjuntos de datos almacenados en el diseñador se convierten automáticamente en un marco de datos de R cuando se cargan con este componente.
Agregue el componente Ejecución de script de R a la canalización.
Conecte cualquier entrada que necesite el script. Las entradas son opcionales y pueden incluir datos y código de R adicional.
Dataset1: haga referencia a la primera entrada como
dataframe1. El conjunto de datos de entrada tiene que tener el formato de un archivo CSV, TSV o ARFF. O bien, puede conectar un conjunto de datos de Azure Machine Learning.Dataset2: haga referencia a la segunda entrada como
dataframe2. Este conjunto de datos también tiene que tener un formato de archivo CSV, TSV o ARFF, o de conjunto de datos de Azure Machine Learning.Conjunto de scripts: la tercera entrada acepta archivos ZIP. Un archivo ZIP puede contener varios archivos y varios tipos de archivo.
En el cuadro de texto Script de R, escriba o pegue el script de R válido.
Nota
Tenga cuidado al escribir el script. Asegúrese de que no haya errores de sintaxis, como el uso de variables no declaradas o de funciones o componentes no importados. Preste especial atención a la lista de paquetes preinstalados al final de este artículo. Para usar paquetes que no aparecen en la lista, instálelos en el script. Un ejemplo es
install.packages("zoo",repos = "https://cloud.r-project.org").Para ayudarle a empezar, el cuadro de texto Script de R se muestra rellenado previamente con el código de ejemplo, que puede editar o reemplazar.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }La función de punto de entrada tiene que tener los argumentos de entrada (
Param<dataframe1>yParam<dataframe2>), aunque estos argumentos no se usen en la función.Nota
Se hace referencia a los datos pasados al componente Ejecución de script de R como
dataframe1ydataframe2, lo que difiere del diseñador de Azure Machine Learning (el diseñador hace referencia comodataset1,dataset2). Asegúrese de que la referencia de los datos de entrada es correcta en el script.Nota
Puede que el código R existente necesite pequeños cambios para ejecutarse en una canalización de diseñador. Por ejemplo, los datos de entrada que se proporcionan en formato CSV deben convertirse explícitamente en un conjunto de datos para que pueda usarlos en su código. Los tipos de datos y columnas que se usan en el lenguaje R también difieren en algunos aspectos de los tipos de columnas y datos que se usan en el diseñador.
Si el script tiene más de 16 KB, use el puerto Agrupación de scripts para evitar errores parecidos a CommandLine supera el límite de 16 597 caracteres.
- Agrupe el script y otros recursos personalizados en un archivo zip.
- Cargue el archivo zip como un Conjunto de datos de archivo en Studio.
- Arrastre el componente de conjunto de datos de la lista Conjuntos de datos del panel de componentes de la izquierda a la página de creación del diseñador.
- Conecte el componente de conjunto de datos al puerto Agrupación de scripts del componente Ejecución de script de R.
A continuación, se muestra el código de ejemplo para consumir el script en el conjunto de scripts:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }Para Random Seed (Valor de inicialización aleatorio) escriba un valor para usarlo en el entorno de R como valor de inicialización aleatorio. Este parámetro equivale a llamar a
set.seed(value)en el código de R.Envíe la canalización.
Results
Los componentes Ejecución de script de R pueden devolver varias salidas, pero se tienen que proporcionar como marcos de datos de R. El diseñador convierte automáticamente los marcos de datos en conjuntos de datos para la compatibilidad con otros componentes.
Los mensajes y los errores estándar de R se devuelven al registro del componente.
Si necesita imprimir resultados del script de R, puede buscar los resultados impresos en 70_driver_log, en la pestaña Resultados y registros del panel derecho del componente.
Muestras de scripts
Hay muchas formas de ampliar una canalización mediante los scripts de R personalizados. En esta sección se proporciona el código de ejemplo para las tareas comunes.
Incorporación de un script de R como entrada
El componente Ejecución de script de R admite archivos de script de R arbitrarios como entradas. Para usarlos, tiene que cargarlos en el área de trabajo como parte del archivo. zip.
Para cargar un archivo ZIP que contenga código R en el área de trabajo, vaya a la página de recurso Datasets (Conjuntos de datos). Seleccione Create dataset (Crear conjunto de datos) y, después, seleccione From local file (Desde archivo local) y la opción de tipo de conjunto de datos File (Archivo).
Compruebe que el archivo ZIP aparece en Mis conjuntos de datos, en la categoría Conjuntos de datos del árbol de componentes de la izquierda.
Conecte el conjunto de datos al puerto de entrada del conjunto de scripts.
Todos los archivos del archivo ZIP están disponibles durante el tiempo de ejecución de la canalización.
Si el archivo del conjunto de scripts contiene una estructura de directorios, esta se conserva. Sin embargo, tiene que modificar el código para anteponer el directorio ./Script Bundle a la ruta de acceso.
Datos de proceso
En el ejemplo siguiente se muestra cómo escalar y normalizar los datos de entrada:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Lectura de un archivo ZIP como entrada
En este ejemplo se muestra cómo usar un conjunto de datos de un archivo .zip como entrada para el componente Ejecución de script de R.
- Cree el archivo de datos en formato CSV y asígnele el nombre mydatafile.csv.
- Cree un archivo ZIP y agregue el archivo CSV al archivo.
- Cargue el archivo comprimido en su área de trabajo de Azure Machine Learning.
- Conecte el conjunto de datos resultante a la entrada ScriptBundle del componente Ejecución de script de R.
- Use el código siguiente para leer los datos en formato CSV del archivo comprimido.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Replicar filas
En este ejemplo se muestra cómo replicar registros positivos en un conjunto de datos para equilibrar la muestra:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
Paso de objetos de R entre componentes Ejecución de script de R
Puede pasar objetos de R entre instancias del componente Ejecución de script de R mediante el mecanismo de serialización interno. En este ejemplo se da por hecho que quiere mover el objeto de R de nombre A entre dos componentes Ejecución de script de R.
Agregue el primer componente Ejecución de script de R a la canalización. Después, especifique el código siguiente en el cuadro de texto Script de R para crear un objeto serializado
Acomo columna en la tabla de datos de salida del componente:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }La conversión explícita al tipo entero se realiza porque la función de serialización devuelve los datos en el formato de R
Raw, lo que el diseñador no admite.Agregue una segunda instancia del componente Ejecución de script de R y conéctela al puerto de salida del componente anterior.
Escriba el siguiente código en el cuadro de texto Script de R para extraer el objeto
Ade la tabla de datos de entrada.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Paquetes preinstalados de R
Los siguientes paquetes preinstalados de R están disponibles actualmente:
| Paquete | Versión |
|---|---|
| askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| caret | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| class | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| conjuntos de datos | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| fs | 1.3.1 |
| gdata | 2.18.0 |
| generics | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| graphics | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0.8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1.23 |
| labeling | 0,3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| Matriz | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0,7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progreso | 1.2.2 |
| ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0,1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0,13 |
| herramientas | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0.8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
Pasos siguientes
Vea el conjunto de componentes disponibles para Azure Machine Learning.