Solución de problemas de limitación (429 - "Demasiadas solicitudes") en Azure Logic Apps
Se aplica a: Azure Logic Apps (consumo + estándar)
Si el flujo de trabajo de su aplicación lógica experimenta una limitación, lo que sucede cuando la cantidad de solicitudes supera la velocidad a la que el destino puede manejar durante un período de tiempo específico, obtendrás el error "HTTP 429 Demasiadas solicitudes". La limitación puede crear problemas como retraso en el procesamiento de datos o reducción en la velocidad de rendimiento y errores como la superación de la directiva de reintentos especificada.
Por ejemplo, la siguiente acción de SQL Server en un flujo de trabajo de Consumo muestra un error 429, que notifica un problema de limitación:
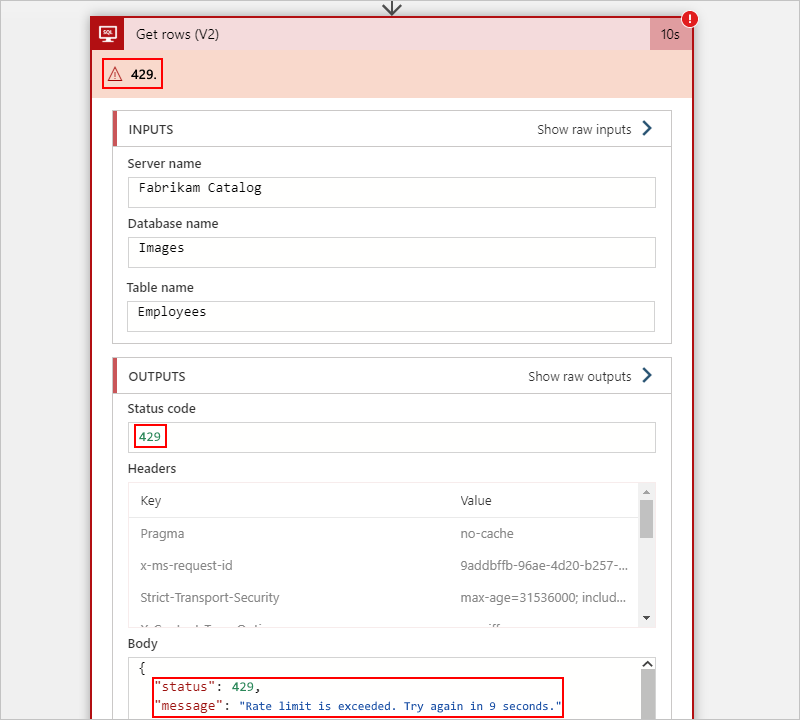
En las secciones siguientes se describen los niveles comunes en los que el flujo de trabajo puede experimentar una limitación:
Limitación de recursos de aplicaciones lógicas
Azure Logic Apps tiene sus propios límites de rendimiento. Si tu recurso de aplicación lógica excede estos límites, el recurso de aplicación lógica se limitará, no solo una instancia o ejecución de flujo de trabajo específica.
Para buscar eventos de limitación en este nivel, sigue estos pasos:
En Azure Portal, abra el recurso de aplicación lógica.
En el menú del recurso de la aplicación lógica, en Supervisión, seleccione Métricas.
En Título del gráfico, selecciona Agregar métrica, que agrega otra barra de métricas al gráfico.
En la primera barra de métricas, en la lista Métrica, selecciona Eventos limitados de acciones. En la lista Agregación, selecciona Recuento.
En la segunda barra de métricas, en la lista Métrica, selecciona Eventos limitados del desencadenador. En la lista Agregación, selecciona Recuento.
El gráfico muestra ahora eventos limitados para las acciones y los desencadenadores en el flujo de trabajo de la aplicación lógica. Para más información, consulte Visualización de métricas para el estado y el rendimiento del flujo de trabajo en Azure Logic Apps.
Para manejar la limitación en este nivel, tienes las siguientes opciones:
Limitar la cantidad de instancias de flujo de trabajo que se pueden ejecutar al mismo tiempo.
De forma predeterminada, si la condición de desencadenante de su flujo de trabajo se cumple más de una vez al mismo tiempo, se activan varias instancias de ese desencadenador y se ejecutan simultáneamente o en paralelo. Cada instancia de desencadenador se activa antes de que la instancia de flujo de trabajo anterior termine de ejecutarse.
Aunque el número predeterminado de instancias de desencadenador que se puede ejecutar simultáneamente es ilimitado, puede limitar este número activando la configuración de simultaneidad del desencadenador y, si es necesario, seleccionar un límite distinto del valor predeterminado.
Habilite el modo de alto rendimiento.
Un flujo de trabajo de Consumo tiene un límite predeterminado para la cantidad de acciones que se pueden ejecutar en un intervalo continuo de 5 minutos. Para aumentar este límite al número máximo de acciones, activa el modo de alto rendimiento en tu recurso de aplicación lógica.
Un flujo de trabajo estándar no tiene ningún límite en el número de acciones que se pueden ejecutar durante cualquier intervalo.
Deshabilita el desglose de matrices o el comportamiento "Dividir en" en los desencadenadores.
Si un desencadenador devuelve una matriz para que las acciones de flujo de trabajo restantes las procesen, el apartadoDividir en de la configuración del desencadenador divide los elementos de la matriz e inicia una instancia de flujo de trabajo para cada elemento de la matriz. Este comportamiento desencadena de forma eficaz varias ejecuciones simultáneas hasta el límite de Dividir en.
Para controlar la limitación, desactiva el comportamiento Dividir en del desencadenador y haz que tu flujo de trabajo procese toda la matriz con una sola llamada, en lugar de manejar un solo elemento por llamada.
Refactorizar acciones en varios flujos de trabajo más pequeños.
Como se mencionó anteriormente, el flujo de trabajo de una aplicación lógica de Consumo está limitado a una cantidad predeterminada de acciones que se pueden ejecutar durante un período de 5 minutos. Aunque puedes aumentar este límite habilitando el modo de alto rendimiento, también puedes considerar si quieres dividir las acciones del flujo de trabajo en flujos más pequeños para que la cantidad de acciones que se ejecutan en cada uno se mantenga por debajo del límite. De esa manera, reduces la carga en un solo flujo de trabajo y distribuyes la carga entre múltiples flujos de trabajo. Esta solución funciona mejor para las acciones que administran grandes conjuntos de datos o establecen tantas acciones en ejecución, iteraciones de bucle o acciones dentro de cada iteración de bucle a la vez que superan el límite de ejecución de la acción.
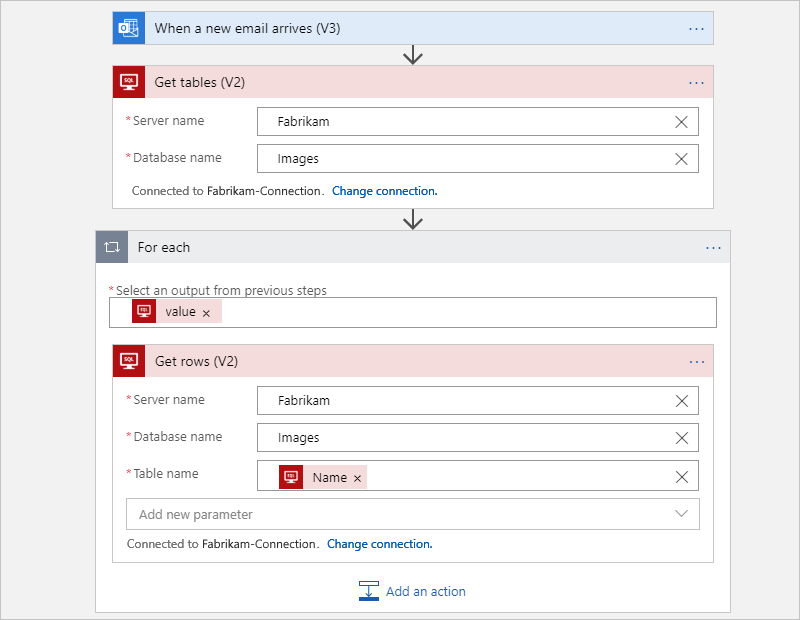
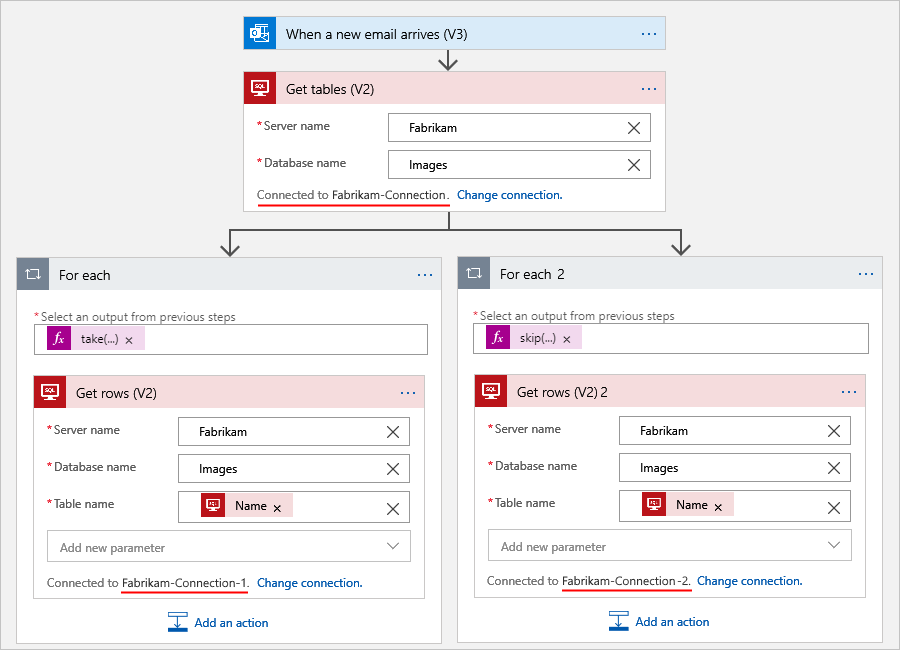
Por ejemplo, el siguiente flujo de trabajo de Consumo hace todo el trabajo para obtener tablas de una base de datos de SQL Server y obtiene las filas de cada tabla. El bucle For Each recorre en iteración simultáneamente cada tabla para que la acción Obtener filas devuelva las filas de cada tabla. En función de las cantidades de datos de esas tablas, estas acciones pueden superar el límite en las ejecuciones de acciones.
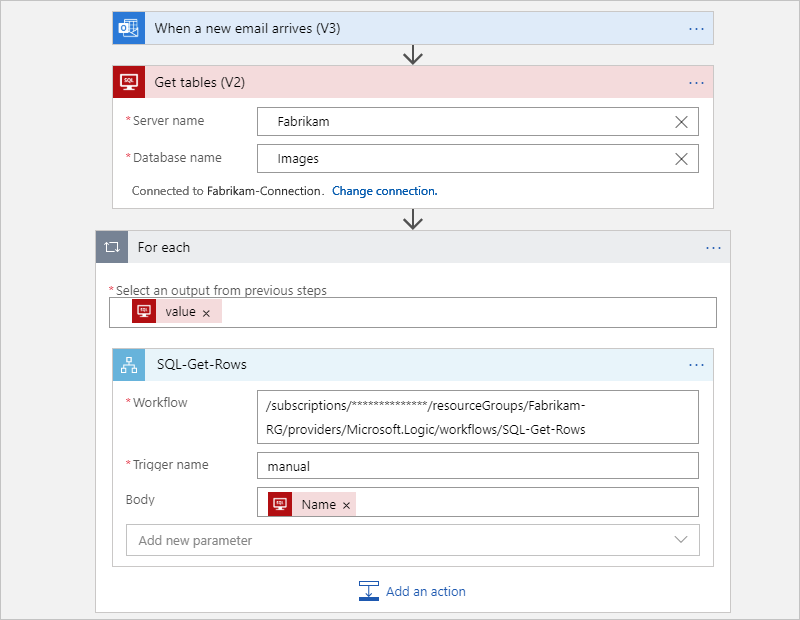
Después de la refactorización, el flujo de trabajo original se divide en uno principal y otro secundario.
El siguiente flujo de trabajo principal obtiene las tablas de SQL Server y luego llama al secundario de cada tabla para obtener las filas:
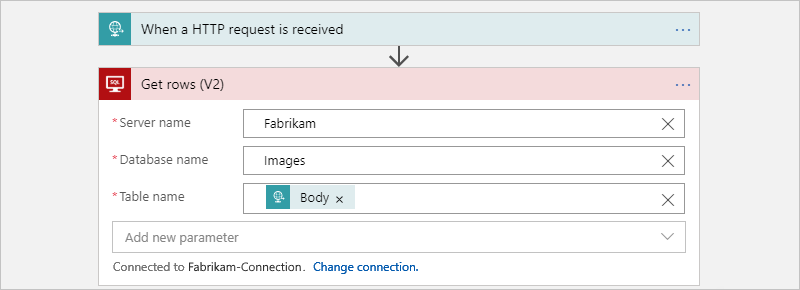
El flujo de trabajo primario llama al siguiente flujo de trabajo secundario para obtener las filas de cada tabla:
Limitación de conectores
Cada conector tiene sus propios límites de regulación, que puedes encontrar en la página de referencia técnica de cada conector. Por ejemplo, el conector de Azure Service Bus tiene un límite para la limitación que permite hasta 6000 llamadas por minuto, mientras que el conector de SQL Server tiene límites para la limitación que varían en función del tipo de operación.
Algunos desencadenadores y acciones, como HTTP, tienen una "directiva de reintentos" que puede personalizar en función de los límites de la directiva de reintentos para implementar el control de excepciones. Esta directiva especifica si un desencadenador o una acción reintenta una solicitud cuando se produce un error en la solicitud original o se agota el tiempo de espera y se genera una respuesta 408, 429 o 5xx, y con qué frecuencia. Por lo tanto, cuando se inicia la limitación y se devuelve un error 429, Logic Apps sigue la directiva de reintentos si se admite.
Para saber si un desencadenador o una acción admite directivas de reintentos, compruebe la configuración de la acción o el desencadenador. Para ver los intentos de reintento de un desencadenador o una acción, ve al historial de ejecuciones de su aplicación lógica, selecciona la ejecución que deseas revisar y expande ese desencadenador o acción para ver detalles sobre entradas, salidas y reintentos.
En el siguiente ejemplo de flujo de trabajo de Consumo se muestra dónde puede encontrar esta información para una acción HTTP:
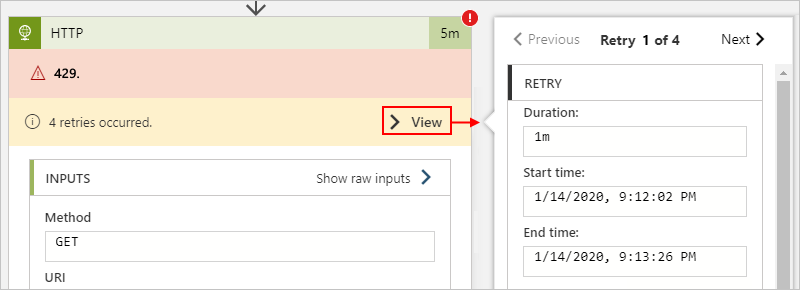
Aunque el historial de reintentos proporciona información de errores, puede que tenga problemas para diferenciar entre la limitación del conector y la limitación del destino. En este caso, es posible que tenga que revisar los detalles de la respuesta o realizar algunos cálculos de intervalo de limitación para identificar el origen.
Para los flujos de trabajo de aplicaciones lógicas de Consumo en Azure Logic Apps multiinquilino, la limitación se produce en el nivel de conexión.
Para manejar la limitación en este nivel, tienes las siguientes opciones:
Configura múltiples conexiones para una sola acción para que el flujo de trabajo pueda dividir los datos para su procesamiento.
Considera si puedes distribuir la carga de trabajo dividiendo las solicitudes de una acción entre varias conexiones en el mismo destino con las mismas credenciales.
Por ejemplo, supongamos que tu flujo de trabajo obtiene tablas de una base de datos de SQL Server y luego obtiene las filas de cada tabla. En función del número de filas que se deban procesar, puede usar varias conexiones y varios bucles For Each para dividir el número total de filas en conjuntos más pequeños para su procesamiento. En este escenario se utilizan dos bucles For Each para dividir el número total de filas en la mitad. El primer bucle For Each usa una expresión que obtiene la primera mitad. El otro bucle For Each utiliza una expresión diferente que obtiene la segunda mitad, por ejemplo:
Expresión 1: La función
take()obtiene la parte delantera de una colección. Para obtener más información, vea Funcióntake().@take(collection-or-array-name, div(length(collection-or-array-name), 2))Expresión 2: La función
skip()quita la parte delantera de una colección y devuelve todos los demás elementos. Para obtener más información, vea Funciónskip().@skip(collection-or-array-name, div(length(collection-or-array-name), 2))En el siguiente ejemplo de flujo de trabajo de Consumo se muestra cómo puedes usar estas expresiones:
Configure una conexión diferente para cada acción.
Considere si puedes distribuir la carga de trabajo mediante la propagación de las solicitudes de cada acción a través de su propia conexión, incluso cuando las acciones se conectan al mismo servicio o sistema y usan las mismas credenciales.
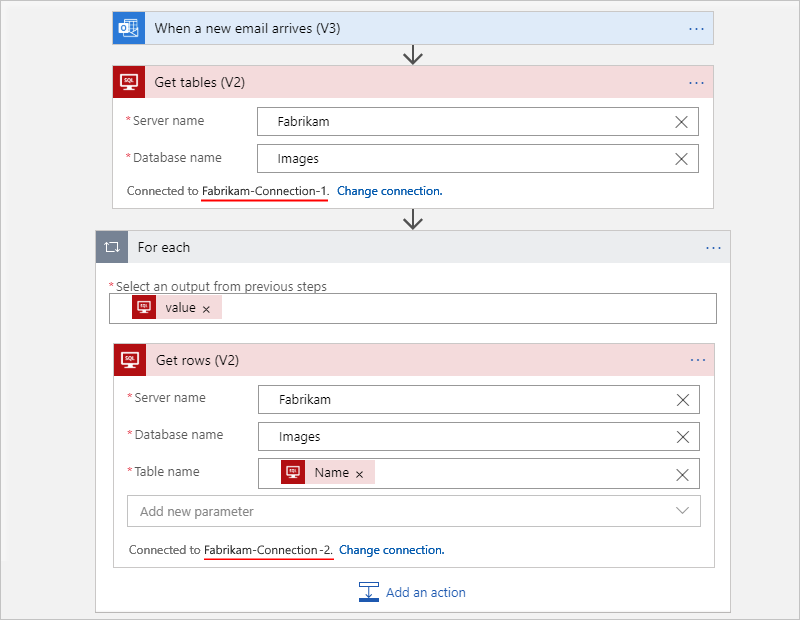
Por ejemplo, supongamos que tu flujo de trabajo obtiene las tablas de una base de datos de SQL Server y obtiene cada fila de cada tabla. Puede usar conexiones independientes de manera que la obtención de las tablas use una conexión y la obtención de cada fila use otra conexión.
El siguiente ejemplo muestra un flujo de trabajo de Consumo que crea y usa una conexión diferente para cada acción:
Cambie la simultaneidad o el paralelismo en un bucle "For Each".
De forma predeterminada, las iteraciones de bucles "For Each" se ejecutan al mismo tiempo hasta el límite de simultaneidad. Si tienes una conexión que se está acelerando dentro de un bucle "Para cada uno", puedes reducir la cantidad de iteraciones de bucle que se ejecutan en paralelo. Para más información, consulte la siguiente documentación:
Bucles "For Each": cambiar simultaneidad o ejecutar secuencialmente
Esquema del lenguaje de definición de flujo de trabajo: bucles For Each
Esquema de lenguaje de definición de flujo de trabajo: cambiar la simultaneidad de bucles "For Each"
Esquema del lenguaje de definición de flujo de trabajo: ejecutar bucles "For Each" secuencialmente
Limitación del sistema o del servicio de destino
Si bien un conector tiene sus propios límites para la limitación, el servicio o sistema de destino al que llama el conector también podría tener límites para la limitación. Por ejemplo, algunas API de Microsoft Exchange Server tienen límites para la limitación más estrictos que el conector de Outlook de Office 365.
De forma predeterminada, las instancias de flujo de trabajo de una aplicación lógica y cualquier bucle o bifurcación dentro de esas instancias se ejecutan en paralelo. Este comportamiento significa que varias instancias pueden llamar al mismo punto de conexión al mismo tiempo. Cada instancia no conoce la existencia de la otra, por lo que los intentos de realizar de nuevo acciones con error pueden crear condiciones de carrera en las que varias llamadas intentan ejecutarse al mismo tiempo, pero para que se completen correctamente, dichas llamadas deben llegar al servicio o sistema de destino antes de que se inicie la limitación.
Por ejemplo, supongamos que tiene una matriz con 100 elementos. Usa un bucle "Para cada uno" para recorrer en iteración la matriz y activar el control de simultaneidad del bucle para que puedas restringir el número de iteraciones paralelas a 20 o el límite predeterminado actual. Dentro de ese bucle, una acción inserta un elemento de la matriz en una base de datos de SQL Server, que solo permite 15 llamadas por segundo. Este escenario genera un problema de limitación porque se acumulan los reintentos y nunca se ejecutan.
La siguiente tabla describe la línea de tiempo de lo que sucede en el bucle cuando el intervalo de reintento de la acción es de 1 segundo:
| A un momento dado | Número de acciones que se ejecutan | Número de acciones con errores | Número de reintentos en espera |
|---|---|---|---|
| T + 0 segundos | 20 inserciones | 5 errores debido a un límite de SQL | 5 reintentos |
| T + 0,5 segundos | 15 inserciones, porque había 5 reintentos anteriores en espera | Las 15 dan error, porque el límite anterior de SQL sigue vigente durante otros 0,5 segundos | 20 reintentos (5 anteriores + 15 nuevos) |
| T + 1 segundo | 20 inserciones | 5 errores más los 20 reintentos anteriores, debido al límite de SQL | 25 reintentos (20 anteriores + 5 nuevos) |
Para manejar la limitación en este nivel, tienes las siguientes opciones:
Crear flujos de trabajo individuales para que cada uno maneje una sola operación.
Al continuar con el escenario de ejemplo de SQL Server en esta sección, puedes crear un flujo de trabajo que coloque los elementos de la matriz en una cola, como una cola de Azure Service Bus. Luego crea otro flujo de trabajo que realice solo la operación de inserción para cada elemento en esa cola. De esa forma, solo se ejecuta una instancia de flujo de trabajo en un momento específico, que completa la operación de inserción y pasa al siguiente elemento de la cola, o la instancia obtiene 429 errores pero no realiza reintentos improductivos.
Crear un flujo de trabajo principal que llame a uno secundario o anidado para cada acción. Si el principal necesita llamar a diferentes flujos de trabajo secundarios en función del resultado del principal, puedes usar una acción de condición o una acción de cambio que determine a qué flujo de trabajo secundario llamar. Este patrón puede ayudarle a reducir el número de llamadas u operaciones.
Por ejemplo, supongamos que tienes dos flujos de trabajo, cada uno con un desencadenador de sondeo que verifica tu cuenta de correo electrónico cada minuto en busca de un asunto específico, como "Correcto" o "Con errores". Esta configuración da como resultado 120 llamadas por hora. En cambio, si creas un flujo de trabajo principal único que sondea cada minuto pero llama a un flujo de trabajo secundario que se ejecuta en función de si el tema es "Correcto" o "Con errores", reduce la cantidad de comprobaciones de sondeo a la mitad o, en este caso, 60.
Configure el procesamiento por lotes. (Solo flujos de trabajo de consumo)
Si el servicio de destino admite operaciones por lotes, puede solucionar el límite mediante el procesamiento de elementos en grupos o lotes, en lugar de hacerlo individualmente. Para implementar la solución de procesamiento por lotes, crea un flujo de trabajo de aplicación lógica de "receptor de lotes" y un flujo de trabajo de aplicación lógica de "remitente de lotes". La remitente del lote recopila mensajes o elementos hasta que se cumplan los criterios especificados y, a continuación, envía esos mensajes o elementos en un único grupo. La receptora del lote acepta ese grupo y procesa esos mensajes o elementos. Para obtener más información, consulte Procesamiento por lotes de mensajes en Azure Logic Apps.
Use las versiones de webhook para los desencadenadores y las acciones, en lugar de las versiones de sondeo.
¿Por qué? Un desencadenador de sondeo continúa comprobando el servicio o sistema de destino a intervalos específicos. Un intervalo muy frecuente, como una vez cada segundo, puede crear problemas de limitación. Sin embargo, un desencadenador o una acción de webhook, como webhook de HTTP, solo crea una llamada al servicio o sistema de destino, que se produce en el momento de la suscripción y solicita que el destino notifique el desencadenador o la acción solo cuando se produce un evento. De este modo, el desencadenador o la acción no tienen que comprobar continuamente el destino.
Por lo tanto, si el servicio o el sistema de destino admite webhooks o proporciona un conector con una versión de webhook, esta opción es mejor que el uso de la versión de sondeo. Para identificar las acciones y los desencadenadores de webhook, confirme que tienen el tipo de
ApiConnectionWebhooko que no requieren que especifique una periodicidad. Para obtener más información, consulte Desencadenador de APIConnectionWebhook y Acción de APIConnectionWebhook.