Configuración de las opciones de agente para la alta disponibilidad, el escalado y el uso de memoria
El recurso Broker es el recurso principal que define la configuración general del agente MQTT. También determina el número y el tipo de pods que ejecutan la configuración de Agente, como los front-end y los back-end. También puede usar el recurso Agente para configurar su perfil de memoria. Los mecanismos de recuperación automática están integrados en el agente y suelen recuperarse automáticamente de los errores de los componentes. Por ejemplo, se produce un error en un nodo en un clúster de Kubernetes configurado para alta disponibilidad.
Puede escalar horizontalmente el agente MQTT agregando más réplicas de front-end y particiones de back-end. Las réplicas de front-end son responsables de aceptar conexiones MQTT de clientes y reenviarlas a las particiones de back-end. Las particiones de back-end son responsables de almacenar y entregar mensajes a los clientes. Los pods de front-end distribuyen el tráfico de mensajes entre los pods de back-end y el factor de redundancia de back-end determina el número de copias de datos para proporcionar resistencia frente a errores de nodo en el clúster.
Para obtener una lista de la configuración disponible, consulte la referencia de la API de Broker.
Configuración de las opciones de escalado
Importante
Esta configuración requiere modificar el recurso de Broker y solo se puede configurar en el momento de la implementación inicial mediante la CLI de Azure o Azure Portal. Se requiere una nueva implementación si se necesitan cambios de configuración de agente. Para más información, consulte Personalización del agente predeterminado.
Para configurar las opciones de escalado del agente MQTT, especifique los campos de cardinalidad en la especificación del recurso Broker durante la implementación de Operaciones de IoT de Azure.
Cardinalidad de implementación automática
Para determinar automáticamente la cardinalidad inicial durante la implementación, omita el campo de cardinalidad en el recurso Broker.
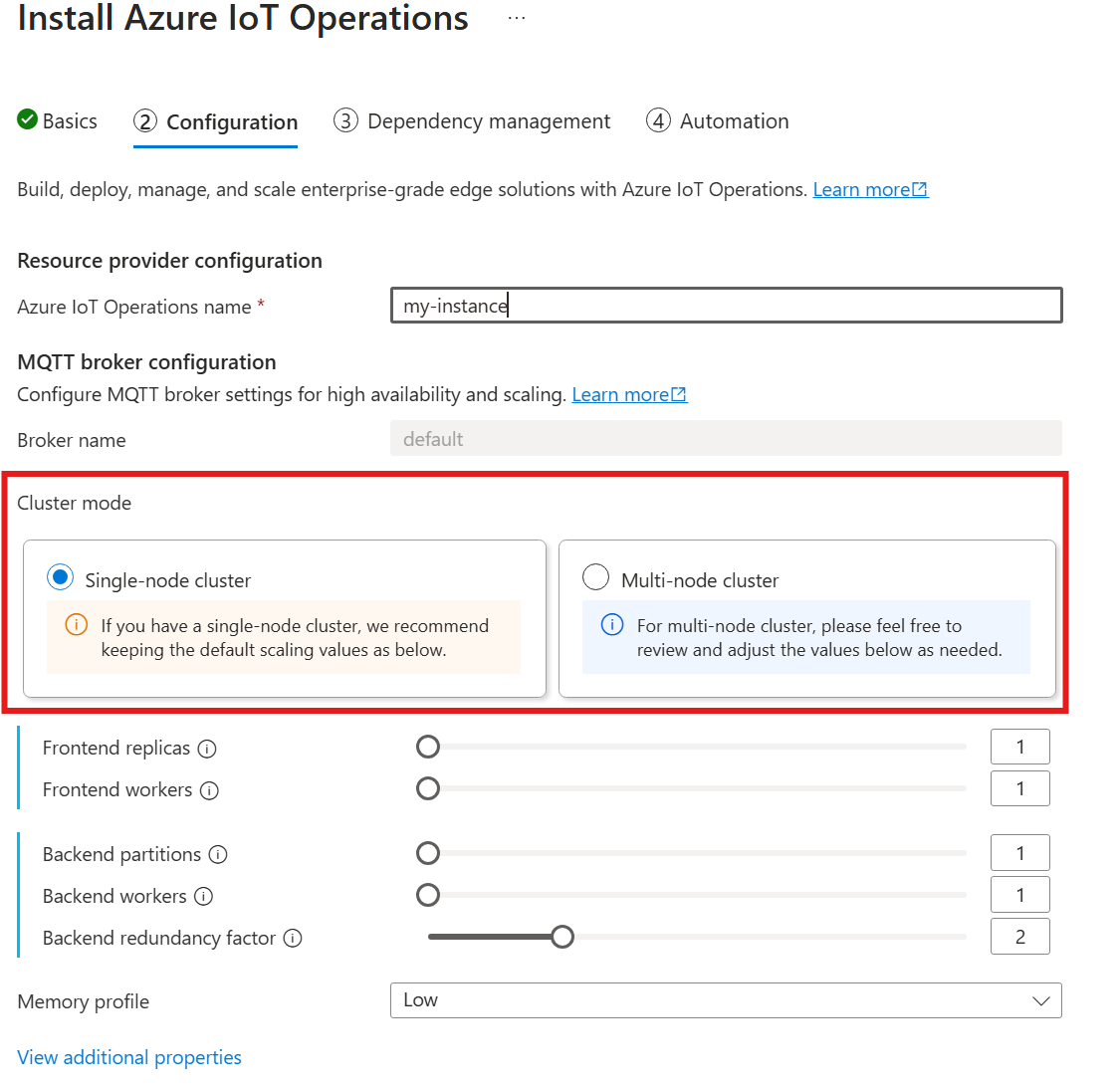
Todavía no se admite la cardinalidad automática al implementar las Operaciones de IoT de Azure a través de Azure Portal. Sin embargo, puede especificar manualmente el modo de implementación del clúster como Nodo único o Multinodo. Para obtener más información, consulte Implementar operaciones de Azure IoT.
El operador de agente MQTT implementa automáticamente el número adecuado de pods en función del número de nodos disponibles en el momento de la implementación. Esto resulta útil para escenarios que no son de producción en los que no se necesita alta disponibilidad ni escala.
Sin embargo, esto no es el escalado automático. El operador no escala automáticamente el número de pods en función de la carga. El operador solo determina el número inicial de pods que se van a implementar en función del hardware del clúster. Como se indicó anteriormente, la cardinalidad solo se puede establecer en el momento de la implementación inicial y se requiere una nueva implementación si es necesario cambiar la configuración de cardinalidad.
Configurar la cardinalidad directamente
Para configurar los valores de cardinalidad directamente, especifique cada uno de los campos de cardinalidad.
Cuando siga la guía para implementar Operaciones de IoT de Azure, en la sección Configuración, busque en Configuración del corredor MQTT. Aquí puede especificar el número de réplicas de front-end, las particiones de back-end y los trabajos de back-end.
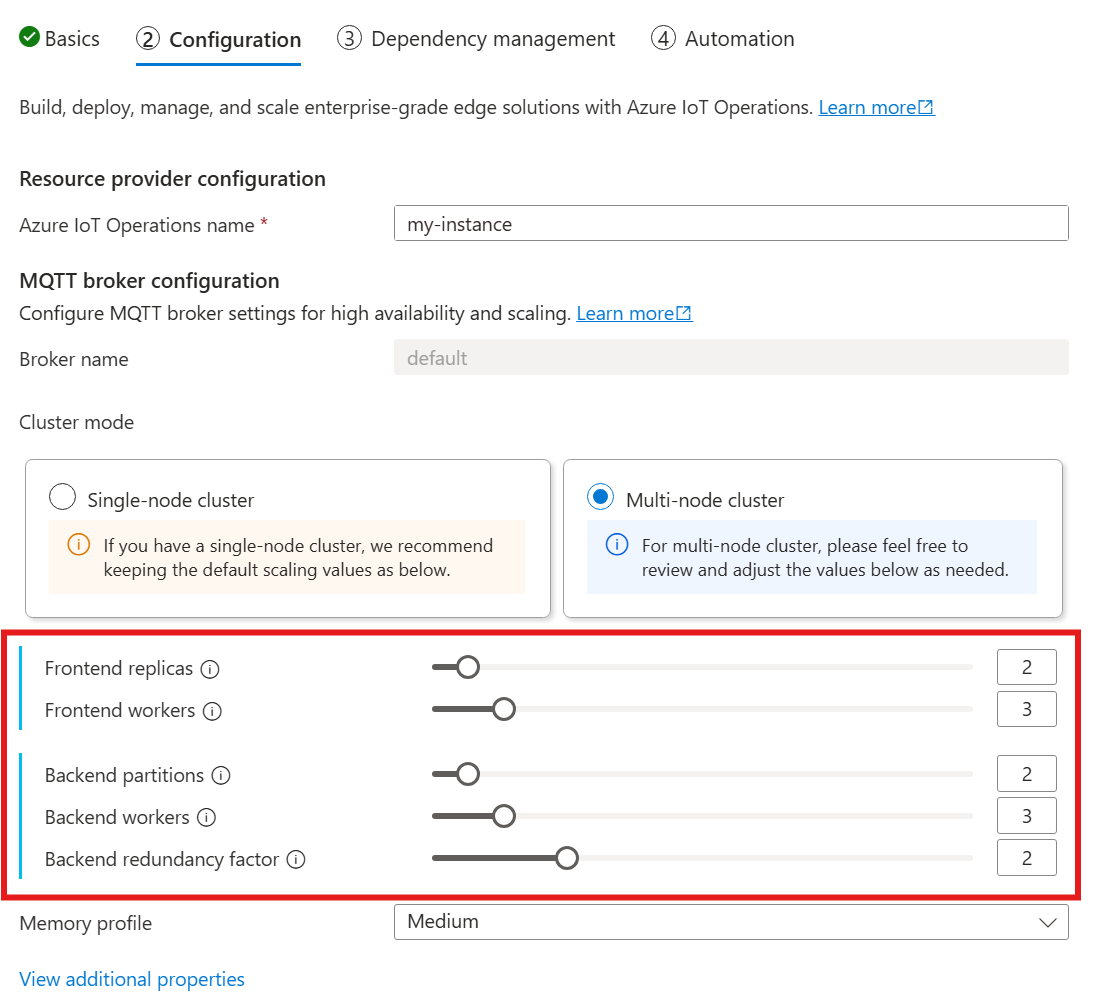
Descripción de la cardinalidad
La cardinalidad significa el número de instancias de una entidad determinada en un conjunto. En el contexto del agente MQTT, la cardinalidad hace referencia al número de réplicas de front-end, particiones de back-end y trabajos de back-end que se van a implementar. La configuración de cardinalidad se usa para escalar horizontalmente el agente y mejorar la alta disponibilidad si hay errores de pod o nodo.
El campo de cardinalidad es un campo anidado, con subcampos para front-end y backendChain. Cada uno de estos subcampos tiene su propia configuración.
Front-end
El subcampo front-end define la configuración de los pods de front-end. Los dos valores principales son:
Réplicas: número de réplicas de front-end (pods) que se van a implementar. Aumentar el número de réplicas de front-end proporciona alta disponibilidad en caso de que se produzca un error en uno de los pods de front-end.
Trabajador: el número de trabajadores de front-end lógicos por réplica. Cada trabajador puede consumir hasta un núcleo de CPU como máximo.
Cadena de back-end
El subcampo de la cadena de back-end define la configuración de las particiones de back-end. Las tres configuraciones principales son:
Particiones: el número de particiones que se van a implementar. A través de un proceso denominado particionamiento, cada partición es responsable de una parte de los mensajes, divididos por identificador de tema e identificador de sesión. Los pods de front-end distribuyen el tráfico de mensajes entre las particiones. Aumentar el número de particiones aumenta el número de mensajes que el agente puede controlar.
Factor de redundancia: el número de réplicas de back-end (pods) que se van a implementar por partición. Aumentar el factor de redundancia aumenta el número de copias de datos para proporcionar resistencia frente a errores de nodo en el clúster.
Trabajadores: el número de trabajos que se van a implementar por réplica de back-end. Aumentar el número de trabajos por réplica de back-end podría aumentar el número de mensajes que puede controlar el pod de back-end. Cada trabajo puede consumir hasta dos núcleos de CPU como máximo, por lo que debe tener cuidado al aumentar el número de trabajos por réplica para no superar el número de núcleos de CPU en el clúster.
Consideraciones
Al aumentar los valores de cardinalidad, la capacidad del agente para controlar más conexiones y mensajes generalmente mejora y mejora la alta disponibilidad si hay errores de pod o nodo. Sin embargo, esto también conduce a un mayor consumo de recursos. Por lo tanto, al ajustar los valores de cardinalidad, tenga en cuenta la configuración del perfil de memoria y las solicitudes de recursos de CPU del agente. Aumentar el número de trabajos por réplica de front-end puede ayudar a aumentar el uso del núcleo de CPU si detecta que el uso de la CPU de front-end es un cuello de botella. Aumentar el número de trabajos de back-end puede ayudar con el rendimiento del mensaje si la CPU de back-end es un cuello de botella.
Por ejemplo, si el clúster tiene tres nodos, cada uno con ocho núcleos de CPU, establezca el número de réplicas de front-end para que coincidan con el número de nodos (3) y establezca el número de trabajadores en 1. Establezca el número de particiones de back-end para que coincidan con el número de nodos (3) y los trabajos de back-end en 1. Establezca el factor de redundancia como desee (2 o 3). Aumente el número de trabajos de front-end si detecta que la CPU de front-end es un cuello de botella. Recuerde que los trabajos de back-end y front-end pueden competir por los recursos de CPU entre sí y otros pods.
Configuración del perfil de memoria
Importante
Esta configuración requiere modificar el recurso de Broker y solo se puede configurar en el momento de la implementación inicial mediante la CLI de Azure o Azure Portal. Se requiere una nueva implementación si se necesitan cambios de configuración de agente. Para más información, consulte Personalización del agente predeterminado.
Para configurar la configuración del perfil de memoria el corredor MQTT, especifique los campos de perfil de memoria en la especificación del recurso Broker durante la implementación de Operaciones de IoT de Azure.
Cuando siga la guía para implementar Operaciones de IoT de Azure, en la sección Configuración, busque en Configuración del corredor MQTT y busque la configuración del Perfil de memoria. Aquí puede seleccionar los perfiles de memoria disponibles en una lista desplegable.
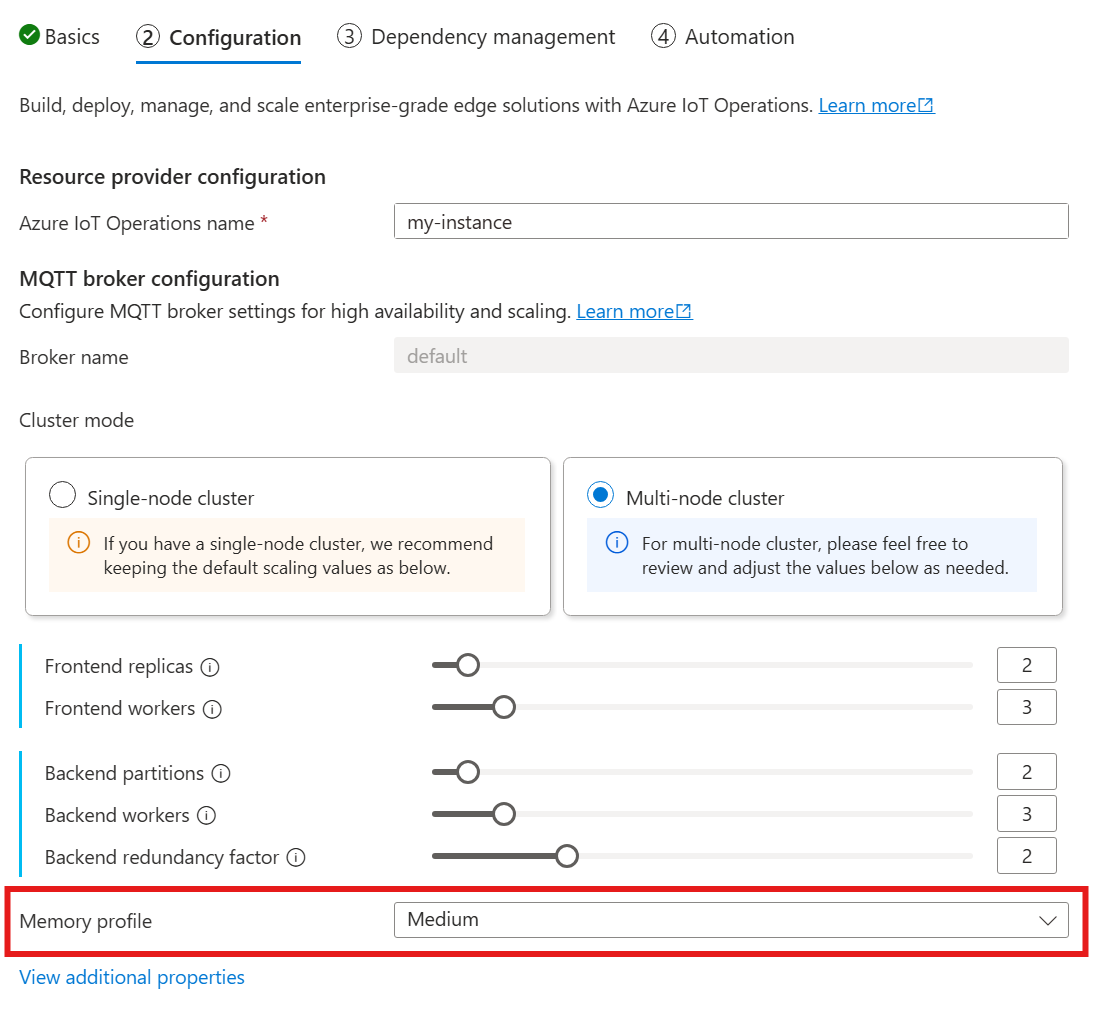
Hay algunos perfiles de memoria entre los que elegir, cada uno con características de uso de memoria diferentes.
Pequeño
Al usar este perfil:
- El uso máximo de memoria de cada réplica de front-end es aproximadamente 99 MiB, pero el uso de memoria máximo real podría ser mayor.
- El uso máximo de memoria de cada réplica de back-end es aproximadamente 102 MiB multiplicado por el número de trabajos de back-end, pero el uso máximo real de memoria podría ser mayor.
Recomendaciones al usar este perfil:
- Solo se debe usar un front-end.
- Los clientes no deben enviar paquetes grandes. Solo debe enviar paquetes menores de 4 MiB.
Bajo
Al usar este perfil:
- El uso máximo de memoria de cada réplica de front-end es aproximadamente 387 MiB, pero el uso máximo real de memoria podría ser mayor.
- El uso máximo de memoria de cada réplica de back-end es aproximadamente 390 MiB multiplicado por el número de trabajos de back-end, pero el uso máximo real de memoria podría ser mayor.
Recomendaciones al usar este perfil:
- Solo se deben usar uno o dos front-end.
- Los clientes no deben enviar paquetes grandes. Solo debe enviar paquetes menores de 10 MiB.
Media
El medio es el perfil predeterminado.
- El uso máximo de memoria de cada réplica de front-end es de aproximadamente 1,9 GiB, pero el uso máximo real de memoria podría ser mayor.
- El uso máximo de memoria de cada réplica de back-end es aproximadamente de 1,5 GiB multiplicado por el número de trabajos back-end, pero el uso de memoria máximo real podría ser mayor.
Alto
- El uso máximo de memoria de cada réplica de front-end es de aproximadamente 4,9 GiB, pero el uso de memoria máximo real podría ser mayor.
- El uso máximo de memoria de cada réplica de back-end es de aproximadamente 5,8 GiB multiplicado por el número de trabajos back-end, pero el uso máximo real de memoria podría ser mayor.
Límites de recursos de Cardinalidad y Kubernetes
Para evitar el colapso de recursos en el clúster, el agente se configura de forma predeterminada para solicitar límites de recursos de CPU de Kubernetes. El escalado del número de réplicas o trabajos aumenta proporcionalmente los recursos de CPU necesarios. Se genera un error de implementación si no hay suficientes recursos de CPU disponibles en el clúster. Esto ayuda a evitar situaciones en las que la cardinalidad del agente solicitada carece de suficientes recursos para ejecutarse de forma óptima. También ayuda a evitar posibles contenciones de CPU y expulsión de pods.
El corredor MQTT actualmente solicita una unidad de CPU (1.0) por trabajo de front-end y dos (2.0) unidades de CPU por trabajo de back-end. Consulte Unidades de recursos de CPU de Kubernetes para más información.
Por ejemplo, la cardinalidad siguiente solicitaría los siguientes recursos de CPU:
- Para front-end: 2 unidades de CPU por pod de front-end, lo que suma 6 unidades de CPU.
- Para back-end: 4 unidades de CPU por pod de back-end (para dos trabajos de back-end), por 2 (factor de redundancia), por 3 (número de particiones), lo que suma 24 unidades de CPU.
{
"cardinality": {
"frontend": {
"replicas": 3,
"workers": 2
},
"backendChain": {
"partitions": 3,
"redundancyFactor": 2,
"workers": 2
}
}
}
Para deshabilitar esta configuración, establezca el campo generateResourceLimits.cpu en Disabled en el recurso Broker.
No se admite el cambio del campo generateResourceLimits en Azure Portal. Para deshabilitar esta configuración, use la CLI de Azure.
Implementación de varios nodos
Para garantizar una alta disponibilidad y resistencia con implementaciones de varios nodos, el corredor MQTT de Operaciones de IoT de Azure establece automáticamente reglas de antiafinidad para pods de back-end.
Estas reglas están predefinidas y no se pueden modificar.
Propósito de las reglas de antiafinidad
Las reglas de antiafinidad garantizan que los pods de back-end de la misma partición no se ejecuten en el mismo nodo. Esto ayuda a distribuir la carga y proporciona resistencia frente a errores de nodo. En concreto, los pods de back-end de la misma partición tienen afinidad entre sí.
Comprobación de la configuración de antiafinidad
Para comprobar la configuración de antiafinidad de un pod de back-end, use el siguiente comando:
kubectl get pod aio-broker-backend-1-0 -n azure-iot-operations -o yaml | grep affinity -A 15
La salida mostrará la configuración antiafinidad, similar a la siguiente:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: chain-number
operator: In
values:
- "1"
topologyKey: kubernetes.io/hostname
weight: 100
Estas son las únicas reglas antiafinidad establecidas para el agente.