Traslado de datos a Azure Blob Storage
Si el flujo de trabajo incluye el movimiento de datos a Azure Blob Storage, asegúrese de que usa una estrategia eficaz. Debe crear la memoria caché, agregar el contenedor de blobs como destino de almacenamiento y, después, copiar los datos mediante Azure HPC Cache.
En este artículo se explican las mejores formas de mover los datos a Blob Storage para usarlos con Azure HPC Cache.
Sugerencia
Este artículo no se aplica al almacenamiento de blobs montado en NFS (destinos de almacenamiento ADLS-NFS). Puede usar cualquier método basado en NFS para rellenar un contenedor de blobs ADLS-NFS antes o después de agregarlo a HPC Cache. Lea Precarga de datos con el protocolo NFS para más información.
Tenga en cuenta estos factores:
Azure HPC Cache usa un formato de almacenamiento especializado para organizar los datos en Blob Storage. Este es el motivo de que un destino de Blob Storage deba ser un contenedor nuevo vacío o un contenedor de blobs que se usara anteriormente con los datos de Azure HPC Cache.
La copia de datos mediante Azure HPC Cache a un destino de almacenamiento de back-end es más eficaz cuando se usan varios clientes y operaciones en paralelo. Un comando de copia sencillo desde un cliente moverá los datos lentamente.
Las estrategias descritas en este artículo funcionan para rellenar un contenedor de blobs vacío o para agregar archivos a un destino de almacenamiento utilizado anteriormente.
Copia de datos mediante Azure HPC Cache
Azure HPC Cache está diseñado para atender a varios clientes a la vez, así que para copiar datos mediante la caché, debe usar escrituras en paralelo desde varios clientes.
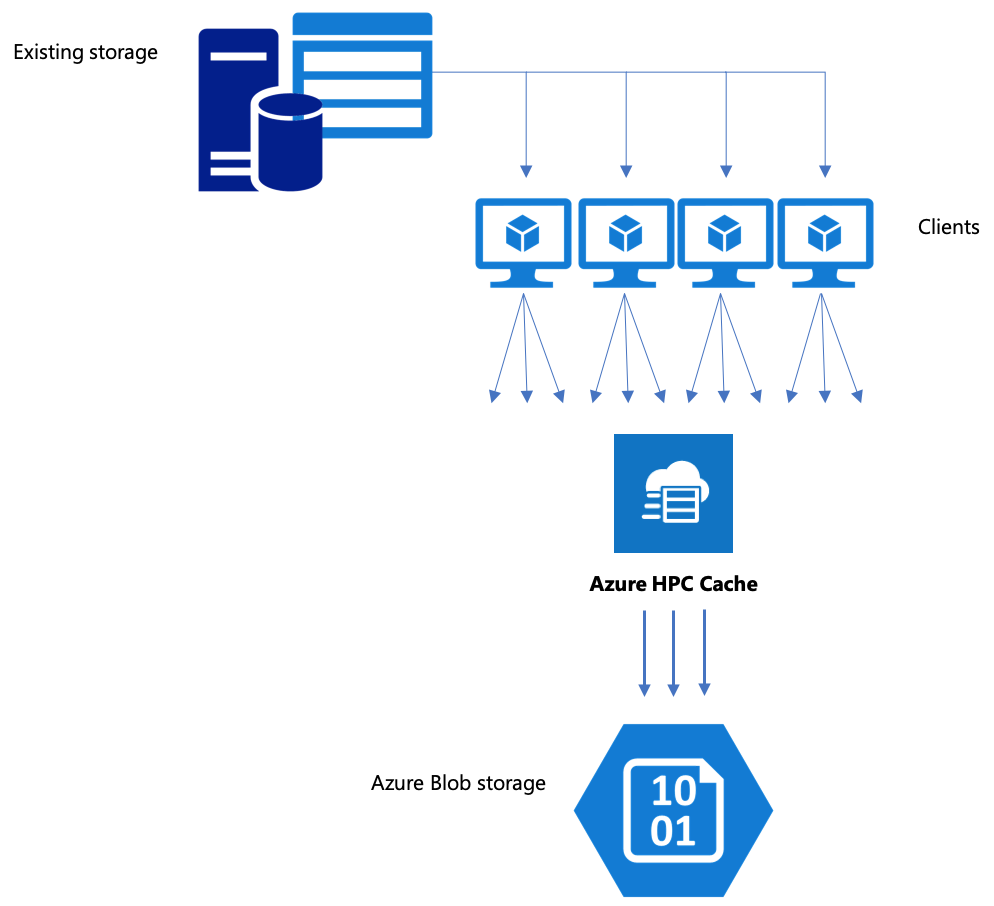
Los comandos cp o copy que se usan habitualmente para transferir datos de un sistema de almacenamiento a otro son comandos de subproceso único que copian solo un archivo a la vez. Esto significa que el servidor de archivos solo puede ingerir un archivo a la vez, lo que es un desperdicio de los recursos de la caché.
En esta sección se explican las estrategias para crear un sistema de copia de archivos de varios subprocesos y varios clientes para mover datos a Blob Storage con Azure HPC Cache. Asimismo, se explican los conceptos de transferencia de archivos y los puntos de decisión que se pueden usar para copiar datos de manera eficiente mediante varios clientes y comandos de copia simples.
Por supuesto, también se explican algunas utilidades que pueden serle de ayuda. La utilidad msrsync se puede usar para automatizar parcialmente el proceso de dividir un conjunto de datos en cubos y usar los comandos rsync. El script parallelcp es otra utilidad que lee el directorio de origen y emite comandos de copia automáticamente.
Plan estratégico
Al crear una estrategia para copiar datos en paralelo, debe comprender las ventajas y desventajas que acarrea el tamaño del archivo, el recuento de archivos y la profundidad del directorio.
- Cuando los archivos son pequeños, la métrica de interés se basa en los archivos por segundo.
- Cuando los archivos son grandes (de 10 MiBi o más), la métrica de interés se mide en función de los bytes por segundo.
Cada proceso de copia tiene una tasa de rendimiento y una tasa de transferencia de archivos que puede medirse en función de la longitud del comando de copia y factorizando el tamaño y número de archivos. La explicación referente a cómo medir estas tasas no se encuentra en este documento, pero es imperativo que sepa si usará archivos pequeños o grandes.
Las estrategias para la ingesta de datos en paralelo con Azure HPC Cache son las siguientes:
Copia manual: puede crear manualmente una copia de varios subprocesos en un cliente mediante la ejecución de más de un comando de copia a la vez en segundo plano con los conjuntos predefinidos de archivos o rutas. Para más información, lea Ingesta de datos de Azure HPC Cache: método de copia manual.
Copia automatizada parcial con
msrsync: -msrsynces una utilidad de contenedor que ejecuta varios procesosrsyncen paralelo. Para más información, lea Ingesta de datos de Azure HPC Cache: método msrsync.Copia de scripts con
parallelcp: aprenda a crear y ejecutar un script de copia en paralelo en Ingesta de datos de Azure HPC Cache: método de script de copia parcial.
Pasos siguientes
Después de configurar el almacenamiento, conozca cómo los clientes pueden montar la caché.