Introducción al uso de datos DICOM en cargas de trabajo de análisis
En este artículo se describe cómo empezar a usar datos DICOM® en cargas de trabajo de análisis con Azure Data Factory y Microsoft Fabric.
Requisitos previos
Antes de empezar, complete estos pasos:
- Cree una cuenta de almacenamiento con funcionalidades de Azure Data Lake Storage Gen2 habilitando un espacio de nombres jerárquico:
- Cree un contenedor para almacenar metadatos DICOM llamado, por ejemplo,
dicom.
- Cree un contenedor para almacenar metadatos DICOM llamado, por ejemplo,
- Implemente una instancia del servicio DICOM.
- (Opcional) Implemente el servicio DICOM con Data Lake Storage para habilitar el acceso directo a archivos DICOM.
- Cree una instancia de Data Factory:
- Habilite una identidad administrada asignada por el sistema.
- Cree un almacén de lago en Fabric.
- Agregue asignaciones de roles a la identidad administrada asignada por el sistema de Data Factory para el servicio DICOM y la cuenta de almacenamiento de Data Lake Storage Gen2:
- Agregue el rol Lector de datos DICOM para conceder permiso al servicio DICOM.
- Agregue el rol Colaborador de datos de Blob Storage para conceder permiso a la cuenta de Data Lake Storage Gen2.
Configuración de una canalización de Data Factory para el servicio DICOM
En este ejemplo, se usa una canalización de Data Factory para escribir atributos DICOM para instancias, series y estudios en una cuenta de almacenamiento en formato de tabla Delta.
En Azure Portal, abra la instancia de Data Factory y seleccione Iniciar Studio para comenzar.

Crear servicios vinculados
Las canalizaciones de Data Factory leen de orígenes de datos y escriben en receptores de datos, que suelen ser otros servicios de Azure. Estas conexiones a otros servicios se administran como servicios vinculados.
La canalización de este ejemplo lee los datos de un servicio DICOM y escribe su salida en una cuenta de almacenamiento, por lo que se debe crear un servicio vinculado para ambos.
Creación de un servicio vinculado para el servicio DICOM
En Azure Data Factory Studio, seleccione Administrar en el menú de la izquierda. En Conexiones, seleccione Servicios vinculados y, a continuación, seleccione Nuevo.
En el panel Nuevo servicio vinculado, busque REST. Seleccione el icono REST y, a continuación, seleccione Continuar.
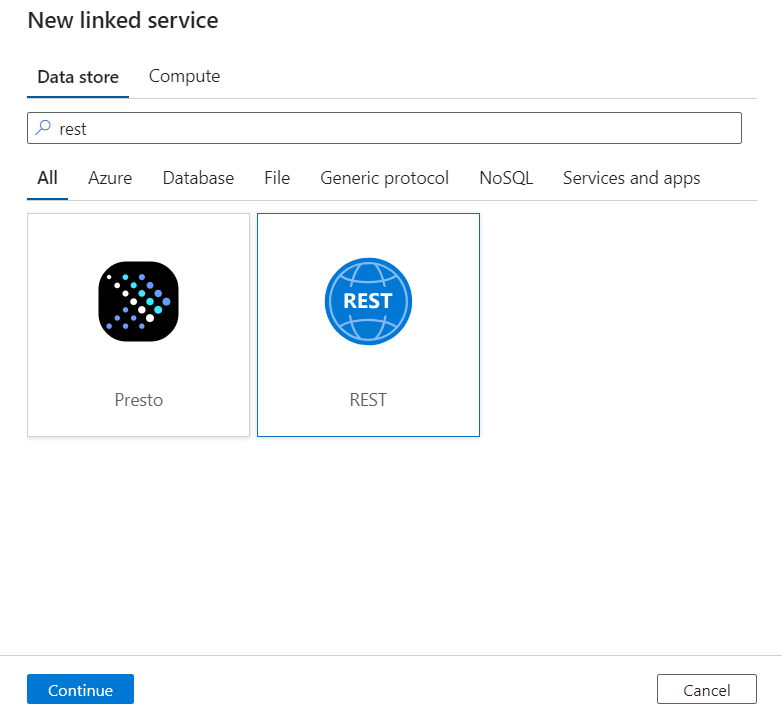
Escriba un Nombre y una Descripción para el servicio vinculado.
En el campo Dirección URL base, escriba la dirección URL del servicio DICOM. Por ejemplo, un servicio DICOM llamado
contosoclinicen el área de trabajo decontosohealthtiene la dirección URL de serviciohttps://contosohealth-contosoclinic.dicom.azurehealthcareapis.com.En Tipo de autenticación, seleccione Identidad administrada asignada por el sistema.
En Recurso de AAD, escriba
https://dicom.healthcareapis.azure.com. Esta dirección URL es la misma para todas las instancias del servicio DICOM.Después de rellenar los campos obligatorios, seleccione Probar conexión para asegurarse de que los roles de la identidad están configurados correctamente.
Después de validar que la conexión se realiza correctamente, seleccione Crear.



Creación de un servicio vinculado para Azure Data Lake Storage Gen2
En Data Factory Studio, seleccione Administrar en el menú de la izquierda. En Conexiones, seleccione Servicios vinculados y, a continuación, seleccione Nuevo.
En el panel Nuevo servicio vinculado, escriba Azure Data Lake Storage Gen2. Seleccione el icono de Azure Data Lake Storage Gen2 y, después, seleccione Continuar.
Escriba un Nombre y una Descripción para el servicio vinculado.

En Tipo de autenticación, seleccione Identidad administrada asignada por el sistema.
Escriba los detalles de la cuenta de almacenamiento escribiendo la dirección URL de la cuenta de almacenamiento manualmente. También puede seleccionar la suscripción de Azure y la cuenta de almacenamiento en las listas desplegables.
Después de rellenar los campos obligatorios, seleccione Probar conexión para asegurarse de que los roles de la identidad están configurados correctamente.
Después de validar que la conexión se realiza correctamente, seleccione Crear.


Creación de una canalización para datos DICOM
Las canalizaciones de Data Factory son una colección de actividades que realizan una tarea, como copiar metadatos DICOM en tablas Delta. En esta sección, se detalla la creación de una canalización que sincroniza periódicamente los datos DICOM con las tablas Delta a medida que se agregan, actualizan y eliminan datos de un servicio DICOM.
Seleccione Crear en el menú de la izquierda. En el panel Recursos de Factory, seleccione el icono de signo más (+) para añadir un nuevo recurso. Seleccione Canalización y, a continuación, seleccione Galería de plantillas en el menú.

En Galería de plantillas, busque DICOM. Seleccione el icono Copiar cambios de metadatos DICOM en ADLS Gen2 en formato Delta y, a continuación, seleccione Continuar.
En la sección Entradas, seleccione los servicios vinculados creados anteriormente para el servicio DICOM y la cuenta de Data Lake Storage Gen2.
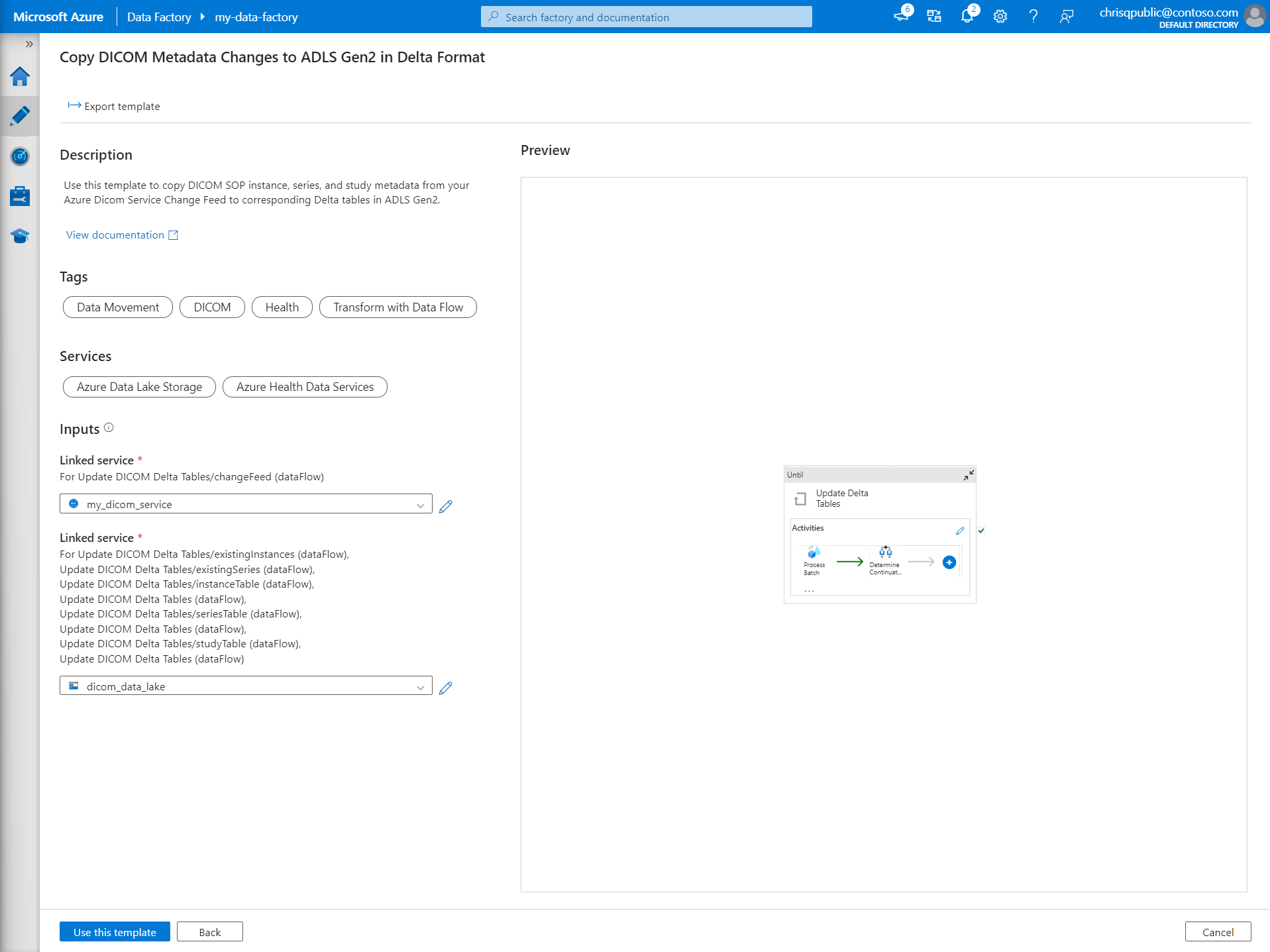
Seleccione Usar esta plantilla para crear la nueva canalización.



Creación de una canalización para datos DICOM
Si ha creado el servicio DICOM con Azure Data Lake Storage, en lugar de usar la plantilla de la galería de plantillas, debe usar una plantilla personalizada para incluir un nuevo parámetro fileName en la canalización de metadatos. Para configurar la canalización, siga estos pasos.
Descargue la plantilla desde GitHub. El archivo de plantilla es una carpeta comprimida. No es necesario extraer los archivos porque ya están cargados en formato comprimido.
En Azure Data Factory, seleccione Crear en el menú de la izquierda. En el panel Recursos de Factory, seleccione el icono de signo más (+) para añadir un nuevo recurso. Seleccione Canalización y, a continuación, seleccione Importar desde la plantilla de canalización.
En la ventana Abrir, seleccione la plantilla que descargó. Seleccione Open (Abrir).
En la sección Entradas, seleccione los servicios vinculados creados para el servicio DICOM y la cuenta de Azure Data Lake Storage Gen2.
Seleccione Usar esta plantilla para crear la nueva canalización.
Programación de una canalización
Las canalizaciones se programan mediante desencadenadores. Hay diferentes tipos de desencadenadores. Los desencadenadores de programación permiten que las canalizaciones se desencadenen en horas específicas del día, como cada hora o cada día a medianoche. Los desencadenadores manuales desencadenan canalizaciones a petición, lo que significa que se ejecutan siempre que quiera que lo hagan.
En este ejemplo, se usa un desencadenador periódico para ejecutar periódicamente la canalización según un punto de inicio y un intervalo de tiempo regular. Para obtener más información sobre los desencadenadores, consulte Ejecución y desencadenadores de canalización en Azure Data Factory o Azure Synapse Analytics.
Creación de un nuevo desencadenador periódico
Seleccione Crear en el menú de la izquierda. Seleccione la canalización para el servicio DICOM y seleccione Agregar desencadenador y Nuevo/Editar en la barra de menús.

En el panel Agregar desencadenadores, seleccione el menú desplegable Elegir desencadenador y, después, seleccione Nuevo.
Escriba un Nombre y una Descripción para el desencadenador.
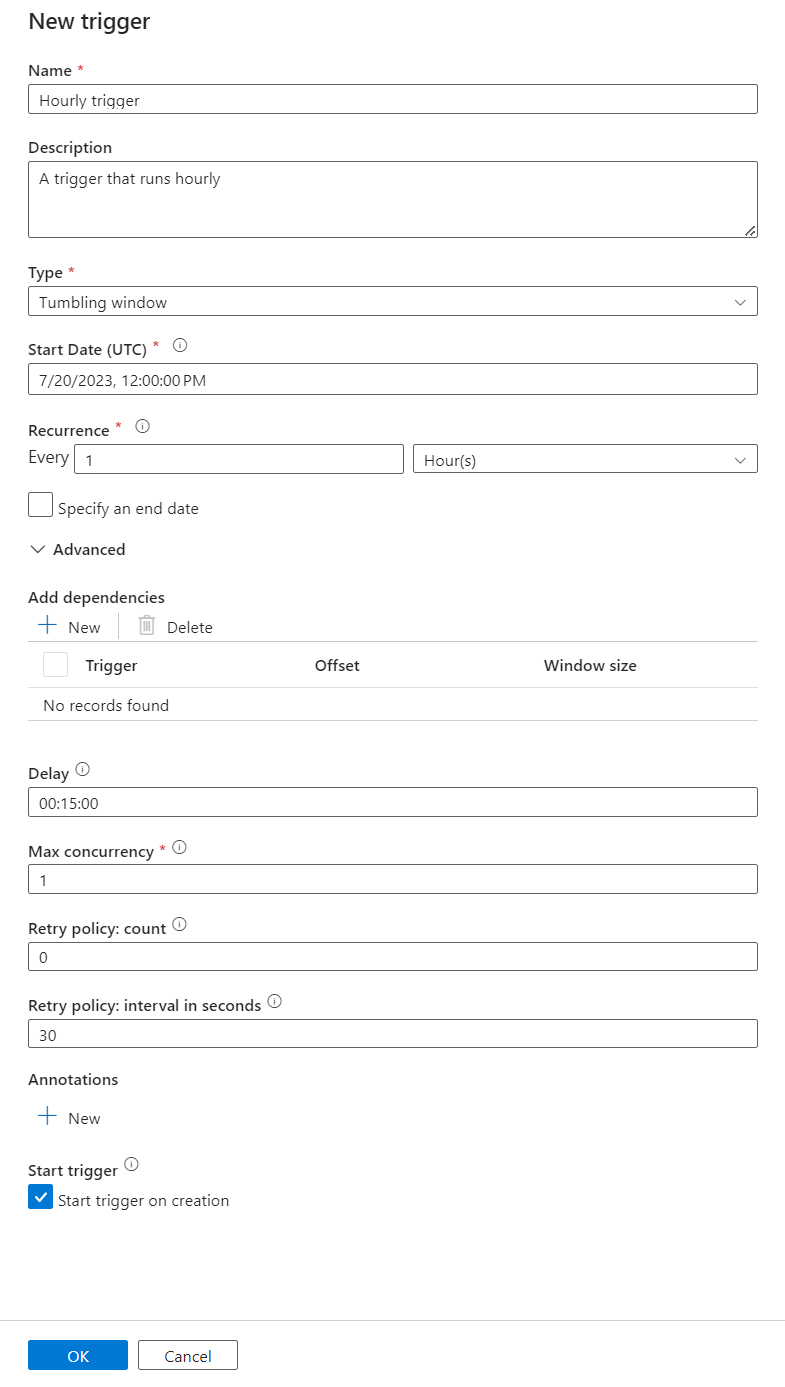
Seleccione Ventana de saltos de tamaño constante como Tipo.
Para configurar una canalización que se ejecute cada hora, establezca Periodicidad en 1 hora.
Expanda la sección Avanzado y escriba un valor para Retraso de 15 minutos. Esta configuración permite que las operaciones pendientes al final de una hora se completen antes del procesamiento.
Establezca Simultaneidad máxima en 1 para garantizar la coherencia entre tablas.
Seleccione Aceptar para continuar configurando los parámetros de ejecución del desencadenador.


Configuración de los parámetros de ejecución del desencadenador
Los desencadenadores definen cuándo se ejecuta una canalización. También incluyen parámetros que se pasan a la ejecución de la canalización. La plantilla Copiar cambios de metadatos DICOM en Delta define algunos parámetros que se describen en la tabla siguiente. Si no se proporciona ningún valor durante la configuración, se usa el valor predeterminado enumerado para cada parámetro.
| Nombre de parámetro | Descripción | Valor predeterminado |
|---|---|---|
| BatchSize | Número máximo de cambios que se van a recuperar a la vez desde la fuente de cambios (máximo 200) | 200 |
| ApiVersion | Versión de la API para el servicio Azure DICOM (mínimo 2) | 2 |
| StartTime | Hora de inicio (incluida) para los cambios de DICOM | 0001-01-01T00:00:00Z |
| EndTime | Hora de finalización (excluida) para los cambios de DICOM | 9999-12-31T23:59:59Z |
| ContainerName | Nombre del contenedor para las tablas Delta resultantes | dicom |
| InstanceTablePath | Ruta de acceso que contiene la tabla Delta para las instancias de SOP de DICOM dentro del contenedor | instance |
| SeriesTablePath | Ruta de acceso que contiene la tabla Delta para la serie de DICOM dentro del contenedor | series |
| StudyTablePath | Ruta de acceso que contiene la tabla Delta para los estudios de DICOM dentro del contenedor | study |
| RetentionHours | Retención máxima expresada en horas para los datos de las tablas Delta | 720 |
En el panel Parámetros de ejecución de desencadenador, escriba el valor de ContainerName que coincide con el nombre del contenedor de almacenamiento creado en los requisitos previos.
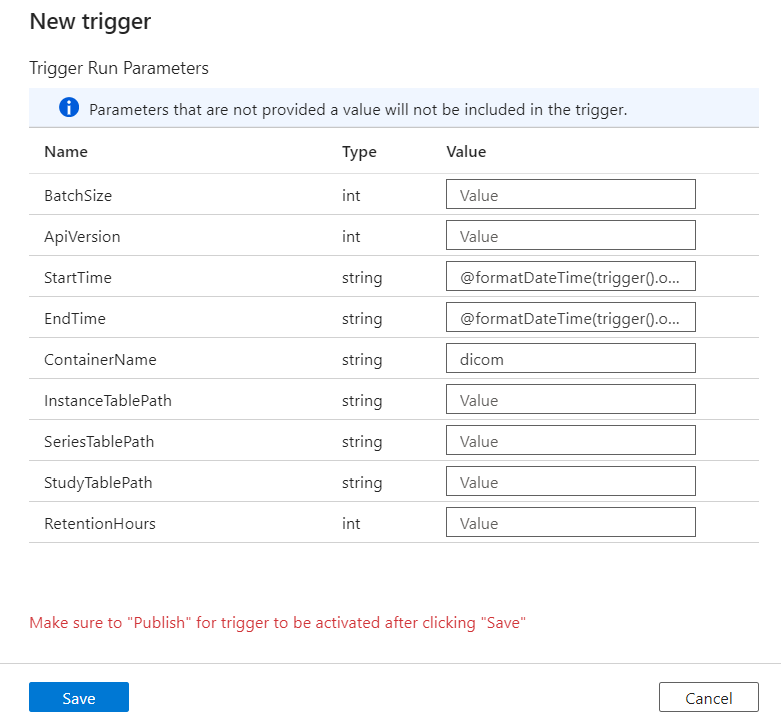
Para StartTime, use la variable del sistema
@formatDateTime(trigger().outputs.windowStartTime).Para EndTime, use la variable del sistema
@formatDateTime(trigger().outputs.windowEndTime).Nota:
Solo los desencadenadores periódicos admiten las variables del sistema:
@trigger().outputs.windowStartTimey@trigger().outputs.windowEndTime.
Los desencadenadores de programación usan otras variables del sistema:
@trigger().scheduledTimey@trigger().startTime.
Obtenga más información sobre los tipos de desencadenadores.
Seleccione Guardar para crear el nuevo desencadenador. Seleccione Publicar para comenzar la ejecución del desencadenador según la programación definida.



Una vez publicado el desencadenador, se puede desencadenar manualmente mediante la opción Desencadenar ahora. Si la hora de inicio se estableció para un valor en el pasado, la canalización se inicia inmediatamente.
Supervisión de las ejecuciones de canalización
Puede supervisar las ejecuciones desencadenadas y sus ejecuciones de canalización asociadas en la pestaña Monitor. Aquí, puede examinar cuándo se ejecutó cada canalización y cuánto tiempo tardó en ejecutarse. También puede depurar cualquier problema que surja.

Microsoft Fabric
Fabric es una solución de análisis todo en uno que se basa en Microsoft OneLake. Con el uso de una instancia de almacén de lago de Fabric, puede administrar, estructurar y analizar datos en OneLake en una sola ubicación. Cualquier dato fuera de OneLake, escrito en Data Lake Storage Gen2, se puede conectar a OneLake mediante accesos directos para aprovechar el conjunto de herramientas de Fabric.
Creación de accesos directos a tablas de metadatos
Vaya al almacén de lago creado en los requisitos previos. En la vista Explorador, seleccione el menú de puntos suspensivos (...) situado junto a la carpeta Tablas.
Seleccione Nuevo acceso directo para crear un nuevo acceso directo a la cuenta de almacenamiento que contiene los datos de análisis de DICOM.

Seleccione Azure Data Lake Storage Gen2 como origen del acceso directo.

En Configuración de conexión, escriba la dirección URL que usó en la sección Servicios vinculados.
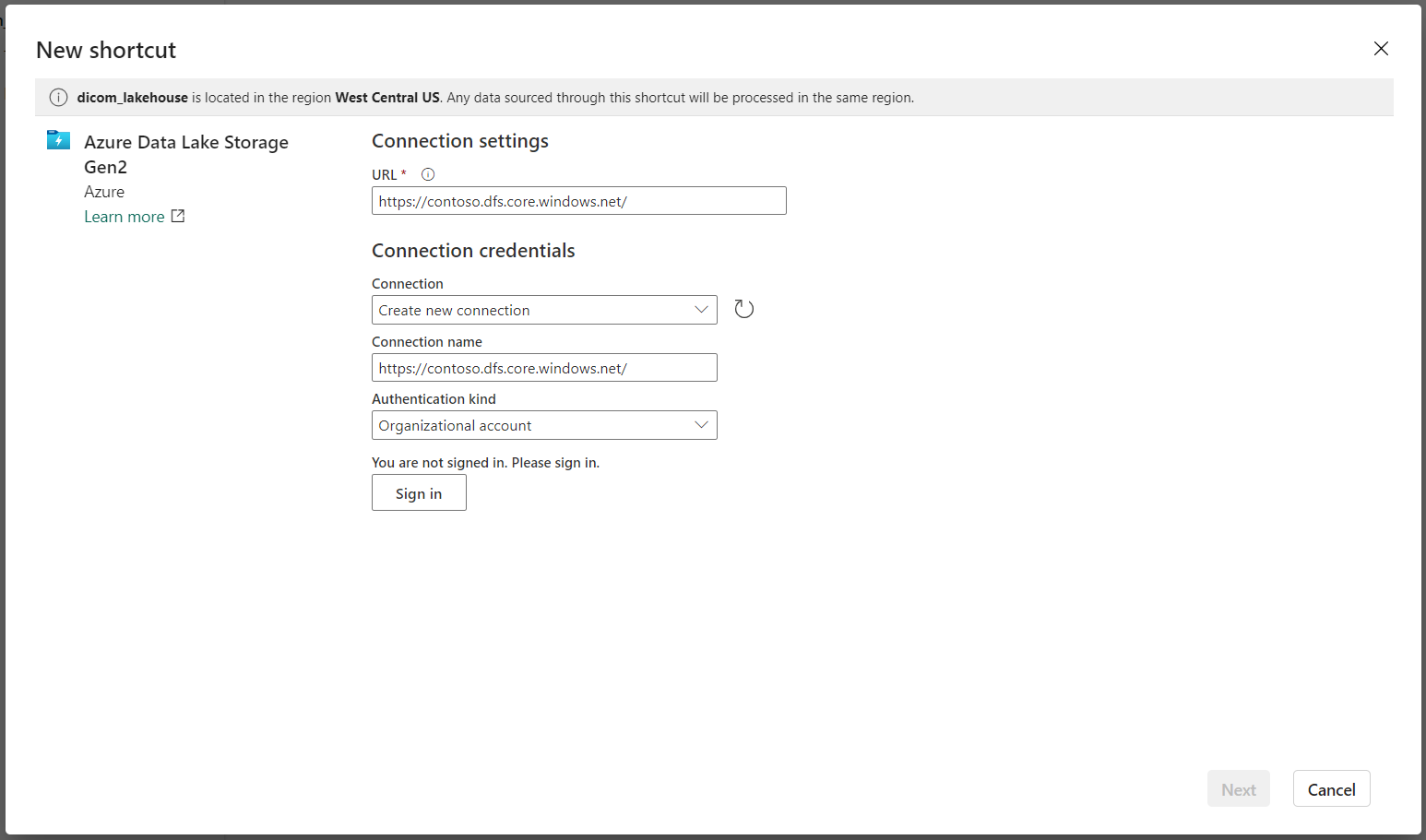
Seleccione una conexión existente o cree una nueva. Para ello, seleccione el Tipo de autenticación que desea usar.
Nota:
Hay algunas opciones para la autenticación entre Data Lake Storage Gen2 y Fabric. Puede usar una cuenta de la organización o una entidad de servicio. No se recomienda usar claves de cuenta ni tokens de firma de acceso compartido.
Seleccione Siguiente.
Escriba un Nombre del acceso directo que represente los datos creados por la canalización de Data Factory. Por ejemplo, para la tabla Delta
instance, es probable que el nombre del acceso directo sea instancia.Escriba la Ruta de acceso secundaria que coincida con el parámetro
ContainerNamede la configuración de parámetros de ejecución y el nombre de la tabla para el acceso directo. Por ejemplo, use/dicom/instancepara la tabla Delta que tiene la ruta de accesoinstanceen el contenedordicom.Seleccione Crear para crear el acceso directo.
Repita los pasos del 2 al 9 para agregar los accesos directos restantes a las demás tablas Delta de la cuenta de almacenamiento (por ejemplo,
seriesystudy).



Después de crear los accesos directos, expanda una tabla para mostrar los nombres y los tipos de las columnas.

Creación de accesos directos a archivos
Si usa un servicio DICOM con Data Lake Storage, también puede crear un acceso directo a los datos del archivo DICOM almacenados en el lago de datos.
Vaya al almacén de lago creado en los requisitos previos. En la vista Explorador, seleccione el menú de puntos suspensivos (...) situado junto a la carpeta Archivos.
Seleccione Nuevo acceso directo para crear un nuevo acceso directo a la cuenta de almacenamiento que contiene los datos de DICOM.
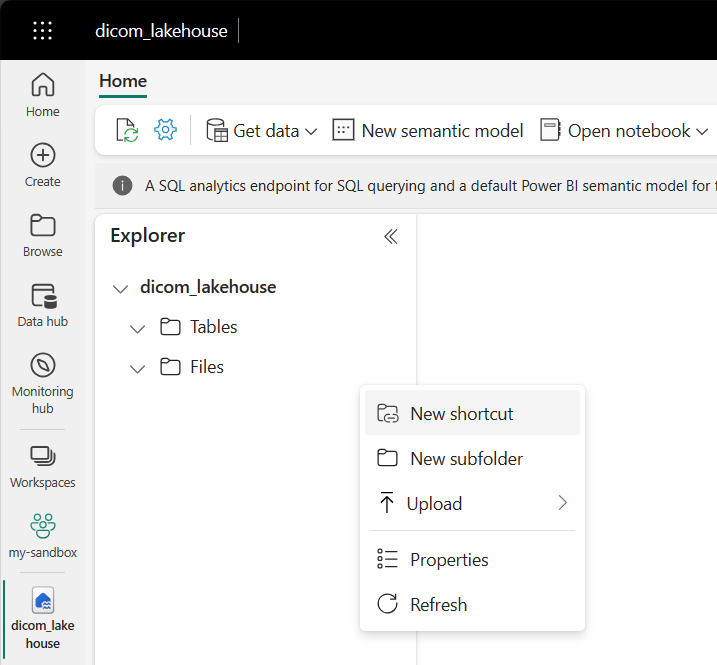
Seleccione Azure Data Lake Storage Gen2 como origen del acceso directo.
En Configuración de conexión, escriba la dirección URL que usó en la sección Servicios vinculados.
Seleccione una conexión existente o cree una nueva. Para ello, seleccione el Tipo de autenticación que desea usar.
Seleccione Siguiente.
Escriba un Nombre de acceso directo que describa los datos DICOM. Por ejemplo, contoso-dicom-files.
Escriba la Ruta de acceso secundaria que coincida con el nombre del contenedor de almacenamiento y la carpeta que usa el servicio DICOM. Por ejemplo, si desea vincular a la carpeta raíz, la ruta de acceso secundaria sería /dicom/AHDS. La carpeta raíz siempre es
AHDS, pero opcionalmente puede vincular a una carpeta secundaria para un área de trabajo específica o una instancia de servicio DICOM.Seleccione Crear para crear el acceso directo.


Ejecución de cuadernos
Una vez creadas las tablas en el almacén de lago, puede consultarlas desde cuadernos de Fabric. Puede crear cuadernos directamente desde el almacén de lago; para ello, seleccione Abrir cuaderno en la barra de menús.
En la página del cuaderno, el contenido de almacén de lago se puede ver en el lado izquierdo, incluidas las tablas recién agregadas. En la parte superior de la página, seleccione el lenguaje del cuaderno. El lenguaje también se puede configurar para celdas individuales. En el ejemplo siguiente, se usa Spark SQL.
Consulta de tablas mediante Spark SQL
En el editor de celdas, escriba una consulta de Spark SQL, como una instrucción SELECT.
SELECT * from instance
Esta consulta selecciona todo el contenido de la tabla instance. Cuando esté listo, seleccione Ejecutar celda para ejecutar la consulta.

Después de unos segundos, los resultados de la consulta aparecen en una tabla debajo de la celda, como se muestra en el ejemplo siguiente. El tiempo puede ser mayor si esta consulta de Spark es la primera de la sesión porque es necesario inicializar el contexto de Spark.

Acceso a los datos del archivo DICOM en cuadernos
Si usó una plantilla para crear la canalización y creó un acceso directo a los datos del archivo DICOM, puede usar la columna filePath de la tabla de instance para correlacionar los metadatos de instancia con los datos del archivo.
SELECT sopInstanceUid, filePath from instance

Resumen
En este artículo, ha aprendido cómo:
- Utilice plantillas de Data Factory para crear una canalización desde el servicio DICOM a una cuenta de Data Lake Storage Gen2.
- Configure un desencadenador para extraer metadatos DICOM según una programación por hora.
- Use accesos directos para conectar datos DICOM de una cuenta de almacenamiento a un almacén de lago de Fabric.
- Use cuadernos para consultar datos DICOM en el almacén de lago.
Pasos siguientes
Nota:
DICOM® es la marca registrada de la Asociación Nacional de Fabricantes Eléctricos para sus publicaciones de normas relacionadas con las comunicaciones digitales de información médica.