Solución de problemas de Apache Spark mediante Azure HDInsight
Conozca los principales problemas y sus soluciones al trabajar con cargas útiles de Apache Spark en Apache Ambari.
¿Cómo se configura una aplicación de Apache Spark mediante Apache Ambari en clústeres?
Los valores de configuración de Spark se pueden ajustar para ayudar a evitar una excepción OutofMemoryError de aplicación de Apache Spark. Los pasos siguientes muestran los valores de configuración predeterminados de Spark en Azure HDInsight:
Inicie sesión en Ambari en
https://CLUSTERNAME.azurehdidnsight.netcon las credenciales del clúster. La pantalla inicial muestra un panel de información general. Hay ligeras diferencias cosméticas entre HDInsight 4.0.Vaya a Spark2>Configs (Configuraciones).
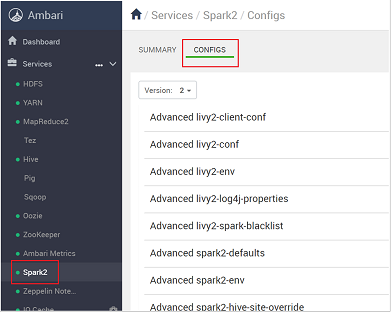
En la lista de configuraciones, seleccione y expanda Custom-spark2-defaults.
Busque el valor de configuración que tiene que ajustar, por ejemplo spark.executor.memory. En este caso, el valor de 9728m es demasiado alto.
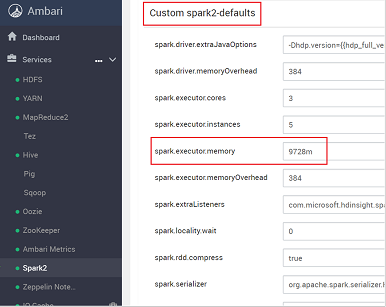
Establezca el valor en la configuración recomendada. Se recomienda el valor de 2048m para esta configuración.
Guarde el valor y, después, guarde la configuración. Seleccione Guardar.
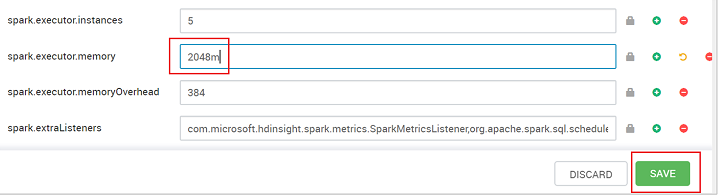
Escriba una nota sobre los cambios de configuración y, después, seleccione Guardar.
Se le notificará si hay configuraciones que necesiten atención. Tenga en cuenta los elementos y, a continuación, seleccione Proceed Anyway (Continuar de todos modos).

Cada vez que se guarda una configuración, se le solicitará que reinicie el servicio. Seleccione Reiniciar.
Confirme el reinicio.
Puede revisar los procesos en ejecución.
Puede agregar configuraciones. En la lista de configuraciones, seleccione Custom-spark2-defaults y, a continuación, seleccione Agregar propiedad.
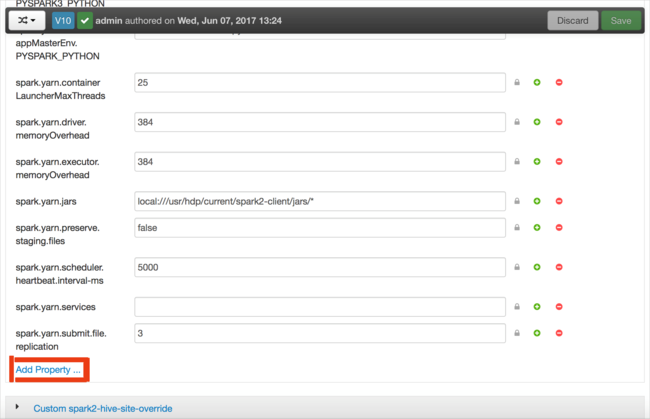
Defina una nueva propiedad. Puede definir una propiedad única mediante un cuadro de diálogo para valores específicos como el tipo de datos. O bien, puede definir varias propiedades mediante una definición por línea.
En este ejemplo, se define la propiedad spark.driver.memory con un valor de 4g.
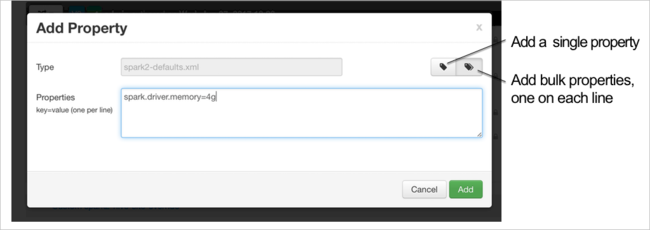
Guarde la configuración y, a continuación, reinicie el servicio, como se describe en los pasos 6 y 7.
Estos cambios son para todo el clúster, pero se pueden invalidar al enviar el trabajo de Spark.
¿Cómo se configura una aplicación de Apache Spark mediante un cuaderno de Jupyter Notebook en clústeres?
En la primera celda del cuaderno de Jupyter Notebook, después de la directiva %%configure, especifique las configuraciones de Spark en formato JSON válido. Cambie los valores reales según sea necesario:

¿Cómo se configura una aplicación de Apache Spark mediante Apache Livy en clústeres?
Envíe la aplicación Spark a Livy mediante un cliente REST como cURL. Use un comando similar al siguiente. Cambie los valores reales según sea necesario:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
¿Cómo se configura una aplicación de Apache Spark mediante spark-submit en clústeres?
Inicie spark-shell mediante un comando similar al siguiente. Cambie el valor real de las configuraciones según sea necesario:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Lectura adicional
Apache Spark job submission on HDInsight clusters (Envío de trabajos de Apache Spark en clústeres de HDInsight)
Pasos siguientes
Si su problema no aparece o es incapaz de resolverlo, visite uno de nuestros canales para obtener ayuda adicional:
Información general de la administración de memoria en Spark.
Obtenga respuestas de expertos de Azure mediante el soporte técnico de la comunidad de Azure.
Póngase en contacto con @AzureSupport, la cuenta oficial de Microsoft Azure para mejorar la experiencia del cliente. Esta cuenta pone en contacto a la comunidad de Azure con los recursos adecuados: respuestas, soporte técnico y expertos.
Si necesita más ayuda, puede enviar una solicitud de soporte técnico desde Azure Portal. Seleccione Soporte técnico en la barra de menús o abra la central Ayuda + soporte técnico. Para obtener información más detallada, revise Creación de una solicitud de soporte técnico de Azure. La suscripción a Microsoft Azure incluye acceso al soporte técnico para facturación y administración de suscripciones. El soporte técnico se proporciona a través de uno de los planes de soporte técnico de Azure.