Excepciones OutOfMemoryError para Apache Spark en Azure HDInsight
En este artículo se describen los pasos de solución de problemas y las posibles soluciones para los problemas que se producen al usar componentes de Apache Spark en clústeres de Azure HDInsight.
Escenario: excepción OutOfMemoryError para Apache Spark
Problema
Error de la aplicación Apache Spark con una excepción OutOfMemoryError no controlada. Es posible que reciba un mensaje de error similar al siguiente:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Causa
La causa más probable de esta excepción es que no se asigna suficiente memoria del montón a las máquinas virtuales Java (JVM). Estas JVM se inician como ejecutores o controladores como parte de la aplicación Apache Spark.
Solución
Determine el tamaño máximo de los datos que la aplicación Spark controla. Realice una estimación del tamaño en función del tamaño máximo de los datos de entrada, los datos intermedios que se generan al transformar los datos de entrada y los datos de salida que se generan al transformar aún más los datos intermedios. Si la estimación inicial no es suficiente, aumente ligeramente el tamaño y repita la iteración hasta que dejen de producirse los errores de memoria.
Asegúrese de que el clúster de HDInsight que se va a usar tiene suficientes recursos, en términos de memoria, así como núcleos para acomodar la aplicación Spark. Para determinarlo, hay que ver en la sección Métricas del clúster de la interfaz de usuario de YARN del clúster los valores de Memoria usada frente a Memoria total y VCores Used (Núcleos virtuales usados) frente a VCores Total (Total de VCores).

Establezca las siguientes configuraciones de Spark en los valores apropiados. Equilibre los requisitos de la aplicación con los recursos disponibles en el clúster. Estos valores no deben superar el 90 % de la memoria y los núcleos disponibles tal y como se ven mediante YARN, y también deben cumplir los requisitos mínimos de memoria de la aplicación Spark:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Memoria total usada por todos los ejecutores =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Memoria total usada por el controlador =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Escenario: error de espacio en el montón Java al intentar abrir el servidor del historial de Apache Spark
Problema
Recibe el siguiente error al abrir eventos en el servidor de historial de Spark:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Causa
Este problema suele deberse a una falta de recursos al abrir archivos grandes de eventos de Spark. El tamaño del montón de Spark se establece en 1 GB de forma predeterminada, pero los archivos de eventos de Spark grandes pueden necesitar más.
Si quiere verificar el tamaño de los archivos que intenta cargar, puede ejecutar los siguientes comandos:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Solución
Puede aumentar la memoria del servidor de historial de Spark editando la propiedad SPARK_DAEMON_MEMORY en la configuración de Spark y reiniciando todos los servicios.
Puede hacerlo desde la interfaz de usuario del explorador de Ambari seleccionando la sección Spark2/config/Advanced spark2-env.
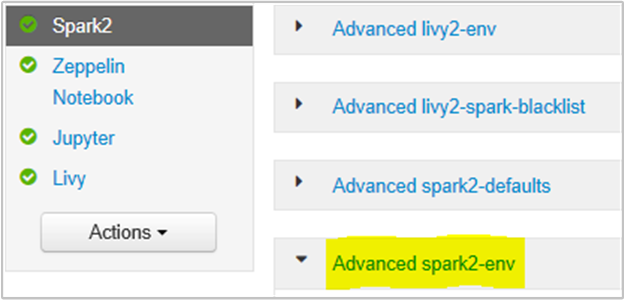
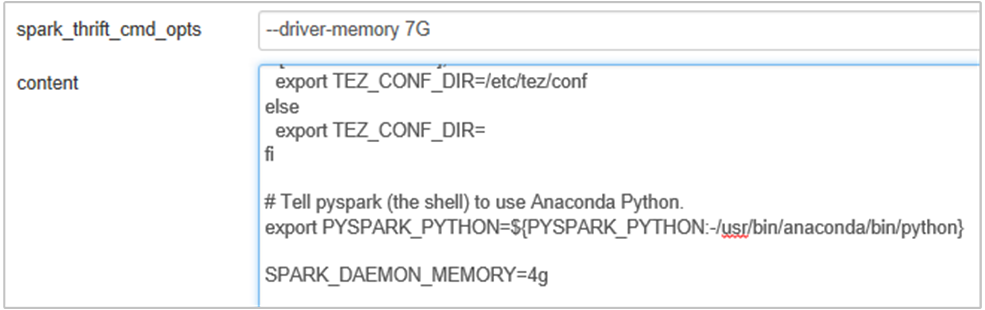
Agregue la siguiente propiedad para cambiar la memoria del servidor de historial de Spark de 1g a 4g: SPARK_DAEMON_MEMORY=4g.
Asegúrese de reiniciar todos los servicios afectados desde Ambari.
Escenario: Livy Server no se inicia en un clúster de Apache Spark
Problema
No se puede iniciar Livy Server en un clúster de Apache Spark [(Spark 2.1 en Linux (HDI 3.6)]. Al intentar reiniciarlo, se produce la siguiente pila de errores en los registros de Livy:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Causa
java.lang.OutOfMemoryError: unable to create new native thread resalta que el sistema operativo no puede asignar más subprocesos nativos a las máquinas virtuales Java. Se ha confirmado que esta excepción se debe a una infracción del límite de recuento de subprocesos por proceso.
Cuando Livy Server finaliza de forma inesperada, también se terminan todas las conexiones a los clústeres de Spark, lo que significa que se pierden todos los trabajos y los datos relacionados. En el mecanismo de recuperación de sesión de HDP 2.6 que se introdujo, Livy almacena los detalles de la sesión en Zookeeper para recuperarlos después de que se reinicia Livy Server.
Cuando se envía un gran número de trabajos a través de Livy, como parte de la alta disponibilidad de Livy Server, se almacenan estos estados de sesión en ZK (en clústeres de HDInsight) y se recuperan esas sesiones cuando se reinicia el servicio Livy. Al reiniciarse después de una terminación inesperada, Livy crea un subproceso por sesión, lo que acumula algunas sesiones por recuperar que hace que se creen demasiados subprocesos.
Resolución
Elimine todas las entradas mediante los pasos siguientes.
Obtenga la dirección IP de los nodos de Zookeeper.
grep -R zk /etc/hadoop/confEn el comando anterior se enumeran todos los nodos de Zookeeper de un clúster
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Obtenga la dirección IP de los nodos de Zookeeper mediante ping, o la conexión a un nodo de Zookeeper desde el nodo principal mediante el nombre ZK
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Una vez conectado a un nodo de Zookeeper, ejecute el siguiente comando para mostrar todas las sesiones que se intentan reiniciar.
En la mayoría de los casos podría ser una lista de más de 8000 sesiones.
ls /livy/v1/batchEl siguiente comando es para quitar todas las sesiones que se van a recuperar. #####
rmr /livy/v1/batch
Espere a que finalice el comando anterior y el cursor devuelva el símbolo del sistema y, luego, reinicie el servicio Livy desde Ambari. Esta operación debería realizarse sin problemas.
Nota
Use el comando DELETE para eliminar la sesión de Livy una vez finalizada su ejecución. Las sesiones por lotes de Livy no se eliminarán automáticamente en cuanto finalice la aplicación de Spark. Esto es así por naturaleza. Una sesión de Livy es una entidad creada por una solicitud POST en el servidor REST de Livy. Se necesita una llamada DELETE para eliminar esa entidad. O, habría que esperar a que se iniciara la recolección de elementos no utilizados.
Pasos siguientes
Si su problema no aparece o es incapaz de resolverlo, visite uno de nuestros canales para obtener ayuda adicional:
Información general de la administración de memoria en Spark.
Obtenga respuestas de expertos de Azure mediante el soporte técnico de la comunidad de Azure.
Póngase en contacto con @AzureSupport, la cuenta oficial de Microsoft Azure para mejorar la experiencia del cliente. Esta cuenta pone en contacto a la comunidad de Azure con los recursos adecuados: respuestas, soporte técnico y expertos.
Si necesita más ayuda, puede enviar una solicitud de soporte técnico desde Azure Portal. Seleccione Soporte técnico en la barra de menús o abra la central Ayuda + soporte técnico. Para obtener información más detallada, revise Creación de una solicitud de soporte técnico de Azure. La suscripción a Microsoft Azure incluye acceso al soporte técnico para facturación y administración de suscripciones. El soporte técnico se proporciona a través de uno de los planes de soporte técnico de Azure.