Uso de Apache Oozie con Apache Hadoop para definir y ejecutar un flujo de trabajo en Azure HDInsight basado en Linux
Aprenda a usar Apache Oozie con Apache Hadoop en Azure HDInsight. Oozie es un sistema de coordinación y flujos de trabajo que administra trabajos de Hadoop. Oozie se integra con la pila de Hadoop y admite los siguientes trabajos:
- MapReduce de Apache Hadoop
- Apache Pig
- Apache Hive
- Apache Sqoop
Oozie también puede usarse para programar trabajos específicos de un sistema, como scripts de shell o programas Java.
Nota
Otra opción para definir los flujos de trabajo con HDInsight es utilizar Azure Data Factory. Para más información acerca de Data Factory, consulte Uso de Apache Pig y Apache Hive con Data Factory. Para usar Oozie en clústeres con Enterprise Security Package, vea Ejecución de Apache Oozie en clústeres HDInsight Hadoop con Enterprise Security Package.
Requisitos previos
Un clúster de Hadoop en HDInsight. Consulte Introducción a HDInsight en Linux.
Un cliente SSH. Consulte Conexión a HDInsight (Apache Hadoop) mediante SSH
Una instancia de Azure SQL Database. Consulte Creación de una base de datos en Azure SQL Database en Azure Portal. En este artículo se usa una base de datos denominada oozietest.
El esquema de URI para el almacenamiento principal de clústeres.
wasb://para Azure Storage,abfs://para Azure Data Lake Storage Gen2 oadl://para Azure Data Lake Storage Gen1. Si se habilita la transferencia segura para Azure Storage, el identificador URI seríawasbs://. Consulte también el artículo acerca de la transferencia segura.
Flujo de trabajo de ejemplo
El flujo de trabajo usado en este documento contiene dos acciones. Las acciones son definiciones de tareas, como la ejecución de Hive, Sqoop, MapReduce o cualquier otro proceso:
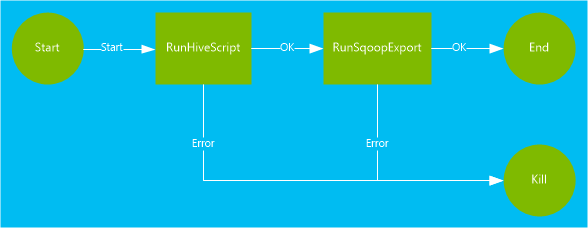
Una acción de Hive ejecuta un script de HiveQL para extraer los registros de
hivesampletableque se incluye con HDInsight. Cada fila de datos describe una visita de un dispositivo móvil específico. El formato de registro es similar al texto siguiente:8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1El script de Hive utilizado en este documento cuenta el número total de visitas a cada plataforma (por ejemplo, Android o iPhone) y almacena los recuentos en una nueva tabla de Hive.
Para más información acerca de Hive, consulte el artículo sobre el [uso de Apache Hive con HDInsight][hdinsight-use-hive].
Una acción de Sqoop exporta el contenido de la nueva tabla de Hive a una tabla creada en Azure SQL Database. Para más información acerca de Sqoop, consulte Uso de Apache Sqoop con HDInsight.
Nota
Para las versiones de Oozie admitidas en los clústeres de HDInsight, consulte Novedades en las versiones de clústeres de Hadoop proporcionadas por HDInsight.
Creación del directorio de trabajo
Oozie espera que almacene todos los recursos necesarios para un trabajo en el mismo directorio. En este ejemplo se usa wasbs:///tutorials/useoozie. Para crear el directorio, siga estos pasos:
Edite el código siguiente para reemplazar
sshusercon el nombre de usuario SSH del clúster, y reemplaceCLUSTERNAMEcon el nombre del clúster. A continuación, escriba el código para conectarse al clúster de HDInsight con SSH.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netPara crear el directorio, use el comando siguiente:
hdfs dfs -mkdir -p /tutorials/useoozie/dataNota
El parámetro
-phace que todos los directorios de la ruta de acceso se creen. El directoriodatase usará para almacenar los datos que usa el scriptuseooziewf.hql.Edite el código siguiente para reemplazar
sshusercon el nombre de usuario SSH. Para asegurarse de que Oozie pueda suplantar su cuenta de usuario, use el comando siguiente:sudo adduser sshuser usersNota
Puede omitir los errores que indican que el usuario ya es miembro del grupo
users.
Adición de un controlador de base de datos
Este flujo de trabajo usa Sqoop para exportar datos a SQL Database. Por lo tanto, debe proporcionar una copia del controlador JDBC que se usa para interactuar con SQL Database. Para copiar el controlador JDBC en el directorio de trabajo, use el siguiente comando desde la sesión SSH:
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Importante
Compruebe el controlador JDBC real que existe en /usr/share/java/.
Si para el flujo de trabajo se han usado otros recursos, como un archivo jar que contiene una aplicación MapReduce, también tendrá que agregar estos recursos.
Definición de la consulta de Hive
Siga estos pasos para crear un script de lenguaje de consulta de Hive (HiveQL) que defina una consulta. Usará la consulta en un flujo de trabajo de Oozie más adelante en este documento.
Desde la conexión SSH, use el comando siguiente para crear un archivo denominado
useooziewf.hql:nano useooziewf.hqlCuando se abra el editor nano de GNU, use la siguiente consulta como contenido del archivo:
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;Estas son las dos variables que se usan en el script:
${hiveTableName}: contiene el nombre de la tabla que se va a crear.${hiveDataFolder}: contiene la ubicación para almacenar los archivos de datos de la tabla.El archivo de definición de flujo de trabajo (workflow.xml en este artículo) pasa estos valores a este script de HiveQL en tiempo de ejecución.
Para guardar el archivo, seleccione Ctrl+X, escriba Y y luego seleccione Entrar.
Use los comandos siguientes para copiar
useooziewf.hqlenwasbs:///tutorials/useoozie/useooziewf.hql:hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlEste comando almacena el archivo
useooziewf.hqlen el almacenamiento compatible con HDFS para el clúster.
Definición del flujo de trabajo
Las definiciones de flujo de trabajo de Oozie se escriben en lenguaje de definición de proceso de Hadoop (hPDL), que es un lenguaje de definición de proceso XML. Use los pasos siguientes para definir el flujo de trabajo:
Use la instrucción siguiente para crear y editar un archivo nuevo:
nano workflow.xmlCuando se abra el editor nano, escriba el siguiente XML como contenido del archivo:
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>Existen dos acciones definidas en el flujo de trabajo:
RunHiveScript: esta acción es la acción de inicio y ejecuta el script de Hiveuseooziewf.hql.RunSqoopExport: esta acción exporta los datos creados a partir del script de Hive a SQL Database mediante Sqoop. Esta acción solo se ejecutará si la acciónRunHiveScriptes correcta.El flujo de trabajo tiene varias entradas, como
${jobTracker}. Estas entradas se reemplazarán por los valores que usa en la definición del trabajo. La definición del trabajo se creará posteriormente en este documento.Tenga en cuenta también la entrada
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>de la sección de Sqoop. Esta entrada indica a Oozie que haga que este archivo esté disponible para Sqoop cuando se ejecuta esta acción.
Para guardar el archivo, seleccione Ctrl+X, escriba Y y luego seleccione Entrar.
Use el comando siguiente para copiar el archivo
workflow.xmlen/tutorials/useoozie/workflow.xml:hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
Creación de una tabla
Nota
Hay muchas maneras de conectarse a SQL Database para crear una tabla. En los siguientes pasos se utiliza FreeTDS desde el clúster de HDInsight.
Use el siguiente comando para instalar FreeTDS en el clúster de HDInsight:
sudo apt-get --assume-yes install freetds-dev freetds-binEdite el código siguiente para reemplazar
<serverName>con el nombre del servidor SQL lógico y<sqlLogin>con el inicio de sesión del servidor. Escriba el comando para conectarse a la base de datos SQL de requisito previo. Escriba la contraseña en el símbolo del sistema.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestRecibirá una salida como el texto siguiente:
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>En el símbolo del sistema
1>, introduzca las líneas siguientes:CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GOCuando se haya especificado la instrucción
GO, se evaluarán las instrucciones anteriores. Estas instrucciones crean una tabla llamadamobiledataque usa el flujo de trabajo.Para comprobar que se ha creado la tabla, utilice los comandos siguientes:
SELECT * FROM information_schema.tables GOEl resultado debe ser parecido al texto siguiente:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLEPara salir de la utilidad tsql, escriba
exiten el símbolo1>.
Creación de una definición de trabajo
La definición del trabajo describe dónde encontrar workflow.xml. También se describe dónde encontrar otros archivos utilizados por el flujo de trabajo, como useooziewf.hql. Además, define los valores de las propiedades usadas en el flujo de trabajo y los archivos asociados.
Use el comando siguiente para obtener la dirección completa del almacenamiento predeterminado. Esta dirección se usa en el archivo de configuración que cree en el paso siguiente.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlEste comando devuelve información similar al siguiente XML:
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Nota
Si el clúster de HDInsight usa Azure Storage como almacenamiento predeterminado, el contenido del elemento
<value>comenzará porwasbs://. Si se usa Azure Data Lake Storage Gen1, comenzará poradl://. Si se usa Azure Data Lake Storage Gen2, comenzará porabfs://.Guarde el contenido del elemento
<value>, ya que se utiliza en los pasos siguientes.Edite el XML siguiente tal como se indica:
Valor del marcador de posición Valor reemplazado wasbs://mycontainer@mystorageaccount.blob.core.windows.net Valor recibido del paso 1. admin Su nombre de inicio de sesión para el clúster HDInsight si no es un administrador. serverName Nombre del servidor de Azure SQL Database. sqlLogin Inicio de sesión del servidor de Azure SQL Database. sqlPassword Contraseña de inicio de sesión del servidor de Azure SQL Database. <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>La mayor parte de la información de este archivo se usa para rellenar los valores utilizados en los archivos workflow.xml o ooziewf.hql, como
${nameNode}. Si la ruta de acceso es una rutawasbs, deberá usar la ruta de acceso completa. No la acorte simplemente awasbs:///. La entradaoozie.wf.application.pathdefine dónde se encuentra el archivo workflow.xml. Este archivo contiene el flujo de trabajo que se ha ejecutado este trabajo.Utilice el comando siguiente para crear la configuración de definición de trabajo de Oozie:
nano job.xmlCuando se abra el editor nano, pegue el XML editado como contenido del archivo.
Para guardar el archivo, seleccione Ctrl+X, escriba Y y luego seleccione Entrar.
Envío y administración del trabajo
Los pasos siguientes usan el comando Oozie para enviar y administrar flujos de trabajo de Oozie en el clúster. El comando de Oozie es una interfaz sencilla sobre la API de REST de Oozie.
Importante
Cuando se utiliza el comando Oozie, debe utilizar el nombre de dominio completo para el nodo principal de HDInsight. Este nombre de dominio completo solo es accesible desde el clúster, o si el clúster está en una instancia de Azure Virtual Network, desde otros equipos en la misma red.
Use el comando siguiente para obtener la dirección URL del servicio de Oozie:
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlEsto devuelve información similar al siguiente XML:
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>La parte
http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/ooziees la dirección URL que se usa con el comando de Oozie.Edite el código para reemplazar la dirección URL con la que recibió anteriormente. Use lo siguiente para crear una variable de entorno para la dirección URL, de manera que no tenga que escribirla para cada comando:
export OOZIE_URL=http://HOSTNAMEt:11000/ooziePara enviar el trabajo, use el código siguiente:
oozie job -config job.xml -submitEste comando carga la información del trabajo de
job.xmly la envía a Oozie, pero no la ejecuta.Una vez completado el comando, debe devolver el identificador del trabajo; por ejemplo,
0000005-150622124850154-oozie-oozi-W. Este identificador se utiliza para administrar el trabajo.Edite el código a continuación para reemplazar
<JOBID>con el id. devuelto en el paso anterior. Para ver el estado del trabajo, use el siguiente comando:oozie job -info <JOBID>Esto devuelve información similar al siguiente texto:
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------Este trabajo tiene un estado de
PREP. Este estado indica que el trabajo se creó, pero no se inició.Edite el código a continuación para reemplazar
<JOBID>con el id. devuelto anteriormente. Para iniciar el trabajo, utilice el comando siguiente:oozie job -start <JOBID>Si comprueba el estado después de este comando, estará en estado de ejecución y se devolverá información para las acciones realizadas dentro del trabajo. Esta operación tardará algunos minutos en completarse.
Edite el código siguiente para reemplazar
<serverName>con el nombre del servidor y<sqlLogin>con el inicio de sesión del servidor. Cuando la tarea se complete correctamente, puede comprobar que los datos se han generado y exportado a la tabla de base de datos SQL mediante el siguiente comando. Escriba la contraseña en el símbolo del sistema.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestEn el símbolo del sistema
1>, escriba la siguiente consulta:SELECT * FROM mobiledata GOLa información devuelta es similar al texto siguiente:
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Para más información acerca del comando Oozie, consulte Herramienta de línea de comandos de Apache Oozie.
API de REST de Oozie
La API de REST de Oozie le permite crear sus propias herramientas que funcionan con Oozie. Lo siguiente es información específica de HDInsight sobre el uso de la API de REST de Oozie:
URI: se puede acceder a la API REST desde fuera del clúster en
https://CLUSTERNAME.azurehdinsight.net/oozie.Autenticación: para realizar la autenticación, use la API con la cuenta HTTP del clúster (admin) y la contraseña. Por ejemplo:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Para más información acerca del uso de la API REST de Oozie, consulte Oozie Web Services API (API de servicios web de Oozie).
Interfaz de usuario web de Oozie
La interfaz de usuario web de Oozie ofrece una vista basada en web en el estado de los trabajos de Oozie en el clúster. Con la interfaz de usuario web, puede ver la información siguiente:
- Estado del trabajo
- Definición del trabajo
- Configuración
- Un gráfico de las acciones en el trabajo
- Registros para el trabajo
También puede ver detalles de las acciones dentro de un trabajo.
Para acceder a la interfaz de usuario web de Oozie, siga estos pasos:
Cree un túnel SSH para el clúster de HDInsight. Para más información, consulte el documento Uso de un túnel SSH con HDInsight.
Después de crear un túnel, abra la interfaz de usuario web de Ambari en el explorador web mediante el URI
http://headnodehost:8080.En el lado izquierdo de la página, seleccione Oozie>Vínculos rápidos>Oozie Web UI (IU web de Oozie).
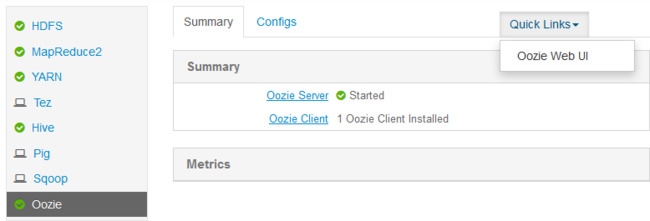
La interfaz de usuario web de Oozie muestra de forma predeterminada los trabajos del flujo de trabajo en ejecución. Para ver todos los trabajos del flujo de trabajo, seleccione All Jobs (Todos los trabajos).
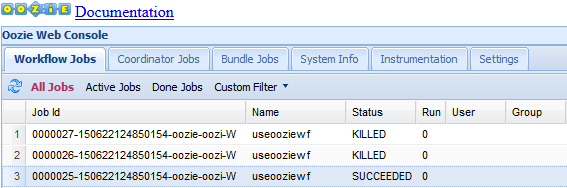
Seleccione un trabajo para obtener más información sobre él.
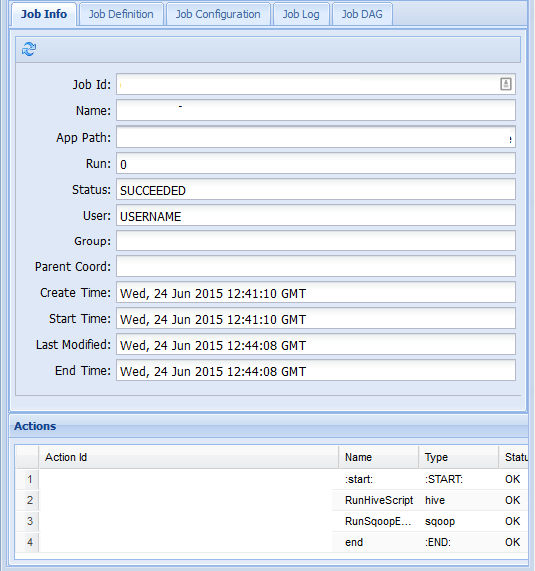
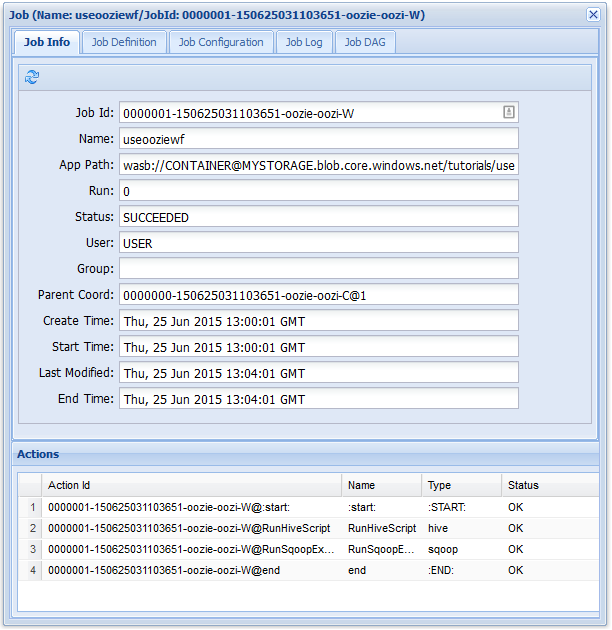
En la pestaña Job Info (Información de trabajo), puede ver información básica de trabajo y las acciones individuales dentro del trabajo. En las pestañas en la parte superior puede ver la Job Definition (Definición del trabajo), Job Configuration (Configuración del trabajo), Job Log (Registro del trabajo) o un grafo acíclico dirigido (DAG) del trabajo en Job DAG (DAG del trabajo).
Job Log (Registro del trabajo): seleccione el botón Get Logs (Obtener registros) para obtener todos los registros del trabajo o use el campo
Enter Search Filterpara filtrar los registros.
DAG del trabajo: el DAG es una información general gráfica de las rutas de acceso de datos usadas en el flujo de trabajo.
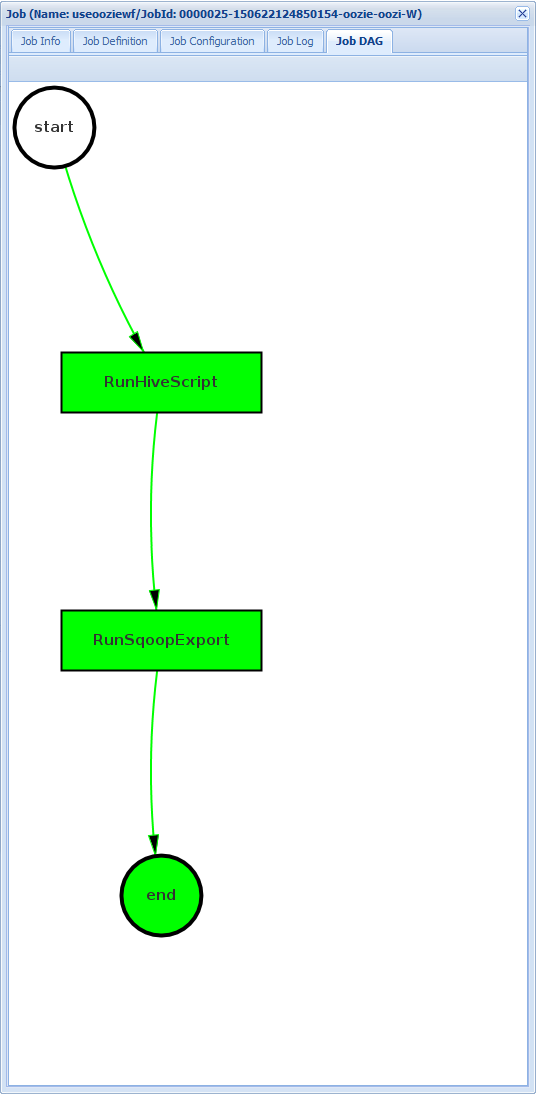
Si selecciona una de las acciones en la pestaña Job Info (Información del trabajo), aparecerá información de la acción. Por ejemplo, seleccione la acción RunSqoopExport.
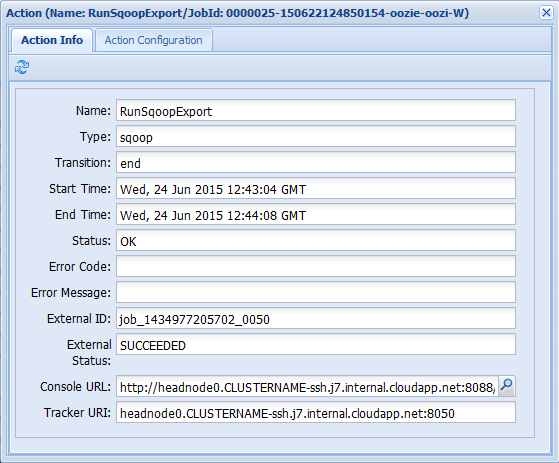
Puede ver detalles de la acción, incluido un vínculo a la dirección URL de la consola. Este vínculo se puede usar para ver la información de seguimiento del trabajo.
Programación de trabajos
Puede utilizar el coordinador para especificar un inicio, un fin y la frecuencia de repetición para los trabajos. Para definir una programación para el flujo de trabajo, siga estos pasos:
Use el comando siguiente para crear un nuevo archivo denominado coordinator.xml:
nano coordinator.xmlUse el siguiente XML como contenido del archivo:
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>Nota
Las variables
${...}se reemplazarán por los valores de la definición del trabajo en tiempo de ejecución. Las variables son las siguientes:${coordFrequency}: el tiempo entre las instancias en ejecución del trabajo.${coordStart}: la hora de inicio del trabajo.${coordEnd}: la hora de finalización del trabajo.${coordTimezone}: los trabajos del coordinador se encuentran en una zona horaria fija sin horario de verano (representado normalmente mediante UTC). Esta zona horaria se conoce como la zona de horaria de procesamiento de Oozie.${wfPath}: la ruta de acceso a workflow.xml.
Para guardar el archivo, seleccione Ctrl+X, escriba Y y luego seleccione Entrar.
Use el siguiente comando para copiar el archivo en el directorio de trabajo para este trabajo:
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xmlPara modificar el archivo
job.xmlque creó antes, use el comando siguiente:nano job.xmlSe han realizado los siguientes cambios:
Para indicar a Oozie que ejecute el archivo de coordinador en lugar del flujo de trabajo, cambie
<name>oozie.wf.application.path</name>por<name>oozie.coord.application.path</name>.Para establecer la variable
workflowPathutilizada por el coordinador, agregue el siguiente código XML:<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>Reemplace el texto
wasbs://mycontainer@mystorageaccount.blob.core.windowspor el valor utilizado en las demás entradas del archivo job.xml.Para definir el inicio, el fin y la frecuencia del coordinador, agregue el siguiente código XML:
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>Estos valores establecen la hora de inicio en las 12:00 del 10 de mayo de 2018 y la fecha de finalización el 12 de mayo de 2018. El intervalo para ejecutar este trabajo se configura diariamente. La frecuencia está en minutos, por lo que 24 horas x 60 minutos = 1440 minutos. Por último, la zona horaria se establece en UTC.
Para guardar el archivo, seleccione Ctrl+X, escriba Y y luego seleccione Entrar.
Para enviar e iniciar el trabajo, use el comando siguiente:
oozie job -config job.xml -runSi visita la interfaz de usuario web de Oozie y selecciona la pestaña Coordinator Jobs (Trabajos de coordinador), verá información similar a la siguiente imagen:

La entrada Next Materialization (Siguiente materialización) contiene la siguiente hora a la que se ejecuta el trabajo.
De igual forma que la tarea de flujo de trabajo anterior, si se selecciona la entrada de trabajo en la interfaz de usuario web, se mostrará información sobre el trabajo:
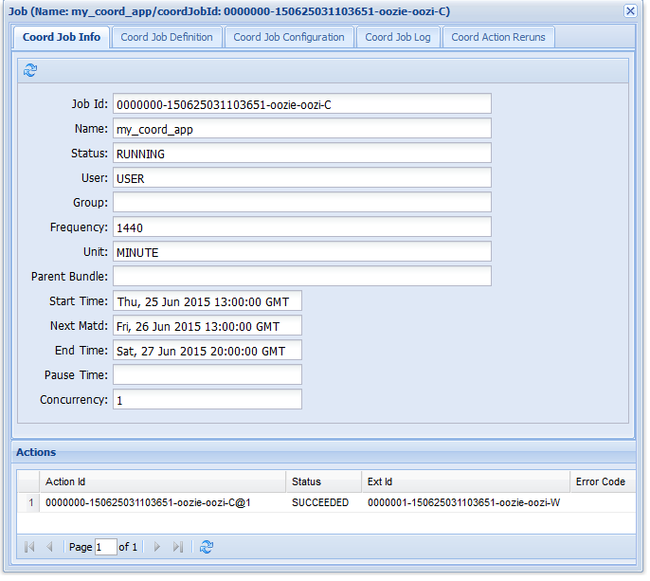
Nota:
Esta imagen solo muestra ejecuciones correctas del trabajo, no acciones individuales dentro del flujo de trabajo programado. Para ver las acciones individuales, seleccione una de las entradas Action (Acción).
Pasos siguientes
En este artículo ha aprendido cómo definir un flujo de trabajo de Oozie y cómo ejecutar un trabajo de Oozie. Para obtener más información sobre el trabajo con HDInsight, consulte los siguientes artículos: