Solución de problemas de HDFS de Apache Hadoop con Azure HDInsight
Obtenga información sobre los principales problemas y las soluciones al trabajar con el Sistema de archivos distribuido (HDFS) de Hadoop. Para una lista completa de comandos, consulte la guía de comandos de HDFS y la guía de comandos shell del sistema de archivos.
¿Cómo se accede a la instancia de HDFS local desde un clúster?
Problema
Acceda a la HDFS local desde la línea de comandos y el código de aplicación, en lugar de mediante Azure Blob Storage o Azure Data Lake Storage desde dentro del clúster de HDInsight.
Pasos de resolución
En el símbolo del sistema, use
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...literalmente, como en el siguiente comando:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userDesde el código fuente, utilice el identificador URI
hdfs://mycluster/literalmente, como se muestra en la siguiente aplicación de ejemplo:import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }Ejecute el archivo .jar compilado (por ejemplo, un archivo denominado
java-unit-tests-1.0.jar) en el clúster de HDInsight con el siguiente comando:hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Excepción de almacenamiento para escritura en blob
Problema
al usar los comandos hadoop o hdfs dfs para escribir archivos de aproximadamente 12 GB o mayores en un clúster de HBase, puede encontrar el siguiente error:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
Causa
HBase en clústeres de HDInsight toma como valor predeterminado un tamaño de bloque de 256 KB al escribir en Azure Storage. Si bien esto funciona para API de HBase o API de REST, se produce un error al usar las utilidades de línea de comandos hadoop o hdfs dfs.
Solución
use fs.azure.write.request.size para especificar un tamaño de bloque mayor. Puede realizar esta modificación en función de cada uso mediante el parámetro -D. El siguiente comando es un ejemplo de uso de este parámetro con el comando hadoop:
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
También puede aumentar el valor de fs.azure.write.request.size globalmente mediante Apache Ambari. Los siguientes pasos se pueden usar para cambiar el valor en la IU web de Ambari:
En el explorador, vaya a la IU web de Ambari para el clúster. La dirección URL es
https://CLUSTERNAME.azurehdinsight.net, dondeCLUSTERNAMEes el nombre del clúster. Cuando se le solicite, escriba el nombre de usuario y la contraseña de administrador para el clúster.En el lado izquierdo de la pantalla, seleccione HDFS y luego seleccione la pestaña Configs (Configuraciones).
En el campo Filter... (Filtro...), escriba
fs.azure.write.request.size.Cambie el valor de 262144 (256 KB) al nuevo valor. Por ejemplo, 4194304 (4 MB).
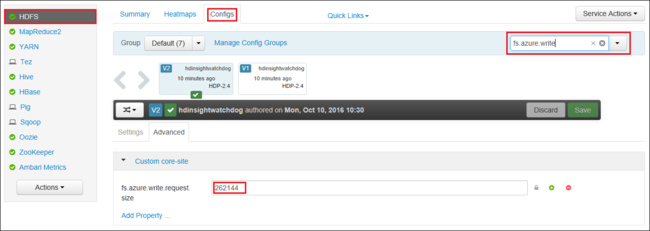
Para más información acerca del uso de Ambari, consulte Administración de clústeres de HDInsight con la interfaz de usuario web de Apache Ambari.
du
El comando -du muestra el tamaño de los archivos y los directorios que contiene el directorio especificado o la longitud de un archivo, si solo fuera uno.
La opción -s genera un resumen agregado de las longitudes de los archivos que se muestran.
La opción -h da formato al tamaño de los archivos.
Ejemplo:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
rm
El comando -rm elimina los archivos especificados como argumentos.
Ejemplo:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
Pasos siguientes
Si su problema no aparece o es incapaz de resolverlo, visite uno de nuestros canales para obtener ayuda adicional:
Obtenga respuestas de expertos de Azure mediante el soporte técnico de la comunidad de Azure.
Póngase en contacto con @AzureSupport, la cuenta oficial de Microsoft Azure para mejorar la experiencia del cliente. Esta cuenta pone en contacto a la comunidad de Azure con los recursos adecuados: respuestas, soporte técnico y expertos.
Si necesita más ayuda, puede enviar una solicitud de soporte técnico desde Azure Portal. Seleccione Soporte técnico en la barra de menús o abra la central Ayuda + soporte técnico. Para obtener información más detallada, revise Creación de una solicitud de soporte técnico de Azure. La suscripción a Microsoft Azure incluye acceso al soporte técnico para facturación y administración de suscripciones. El soporte técnico se proporciona a través de uno de los planes de soporte técnico de Azure.