Solución de problemas de un trabajo lento o con errores en un clúster de HDInsight
Si una aplicación que procesa datos en un clúster de HDInsight se está ejecuta con lentitud o genera un error con un código, tiene varias opciones para solucionar los problemas. Si los trabajos tardan en ejecutarse más de lo esperado o si ve tiempos de respuesta lentos en general, puede haber errores en niveles superiores al clúster, como los servicios en los que se ejecuta el clúster. Sin embargo, la causa más común de estas ralentizaciones es un escalado insuficiente. Al crear un nuevo clúster de HDInsight, seleccione los tamaños de máquina virtual adecuados.
Para diagnosticar un clúster lento o con errores, recopile información sobre todos los aspectos del entorno, como los servicios asociados de Azure, la configuración del clúster y la información sobre la ejecución del trabajo. Un diagnóstico útil consiste en intentar reproducir el estado de error en otro clúster.
- Paso 1: Recopilar datos sobre el problema.
- Paso 2: Validar el entorno del clúster de HDInsight.
- Paso 3: Ver el estado del clúster.
- Paso 4: Revisar las versiones y la pila del entorno.
- Paso 5: Examinar los archivos de registro del clúster.
- Paso 6: Comprobar las opciones de configuración.
- Paso 7: Reproducir el error en un clúster diferente.
Paso 1: Recopilar datos sobre el problema
HDInsight proporciona muchas herramientas que puede usar para identificar y solucionar problemas con clústeres. Los pasos siguientes le guían por estas herramientas y proporcionan sugerencias para identificar el problema.
Identificación del problema
Para ayudar a identificar el problema, tenga en cuenta las siguientes preguntas:
- ¿Qué esperaba que ocurriera? ¿Qué pasó en su lugar?
- ¿Cuánto tiempo tardó en ejecutarse el proceso? ¿En cuánto tiempo debería haberse ejecutado?
- ¿Mis tareas siempre se han ejecutado lentamente en este clúster? ¿Se ejecutaron más rápidamente en otro clúster?
- ¿Cuándo se produjo este problema por primera vez? ¿Con qué frecuencia se ha producido desde entonces?
- ¿Ha cambiado algo en mi configuración del clúster?
Detalles del clúster
A continuación, se indica la información importante del clúster:
- Nombre del clúster.
- Región del clúster: compruebe las interrupciones de la región.
- Tipo y versión del clúster de HDInsight.
- Tipo y número de instancias de HDInsight especificadas para los nodos principal y de trabajo.
Azure Portal puede proporcionar esta información:

También puede usar la CLI de Azure:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Otra opción es usar PowerShell. Para más información, consulte Administración de clústeres de Apache Hadoop en HDInsight con Azure PowerShell.
Paso 2: Validar el entorno del clúster de HDInsight
Cada clúster de HDInsight se basa en varios servicios de Azure y en software de código abierto, como Apache HBase y Apache Spark. Los clústeres de HDInsight también pueden llamar a otros servicios de Azure, como Azure Virtual Network. Un error de clúster puede deberse a cualquiera de los servicios en ejecución en el clúster o a un servicio externo. Un cambio de configuración del servicio del clúster también puede provocar que el clúster genere un error.
Detalles del servicio
- Compruebe las versiones de lanzamiento de la biblioteca de código abierto.
- Busque interrupciones del servicio de Azure.
- Busque límites de uso del servicio de Azure.
- Compruebe la configuración de subred de Azure Virtual Network.
Ver las opciones de configuración del clúster con la UI de Ambari
Apache Ambari proporciona administración y supervisión de un clúster de HDInsight con una interfaz de usuario web y una API de REST. Ambari se incluye en los clústeres de HDInsight basados en Linux. Seleccione el Panel de clúster en la página de Azure Portal HDInsight. Seleccione el panel de clúster de HDInsight para abrir la interfaz de usuario de Ambari y escriba las credenciales de inicio de sesión del clúster.

Para abrir una lista de vistas de servicio, seleccione Vistas de Ambari en la página de Azure Portal. Esta lista depende de las bibliotecas instaladas. Por ejemplo, puede ver YARN Queue Manager, Hive View y Tez View. Seleccione un vínculo de servicio para ver información sobre la configuración y el servicio.
Buscar interrupciones de servicio de Azure
HDInsight se basa en varios servicios de Azure. Ejecuta servidores virtuales en Azure HDInsight, almacena datos y scripts en Azure Blob Storage o Azure Data Lake Storage e indexa los archivos de registro en el almacenamiento de tablas de Azure. Las interrupciones en estos servicios, aunque sean poco frecuentes, pueden causar problemas en HDInsight. Si se produce una ralentización inesperada o errores en el clúster, compruebe el panel de estado de Azure. El estado de cada servicio se muestra por región. Compruebe la región de su clúster, así como las de todos los servicios relacionados.
Comprobar los límites de uso del servicio de Azure
Si inicia un clúster grande o ha iniciado muchos clústeres al mismo tiempo, uno de ellos puede generar un error si ha superado un límite de servicio de Azure. Los límites de servicio varían en función de su suscripción a Azure. Para más información, consulte Límites, cuotas y restricciones de suscripción y servicios de Microsoft Azure. Puede solicitar que Microsoft aumente el número de recursos de HDInsight disponibles (por ejemplo, núcleos e instancias de VM) con una solicitud de aumento de cuota de núcleos de Resource Manager.
Comprobar la versión de lanzamiento
Compare la versión del clúster con la versión más reciente de HDInsight. Todas las versiones de HDInsight incluyen mejoras, como nuevas aplicaciones, características, revisiones y correcciones de errores. Puede que el problema que está afectando a su clúster se haya solucionado en la versión más reciente. Si es posible, vuelva a ejecutar el clúster con la versión más reciente de HDInsight y las bibliotecas asociadas, como Apache HBase, Apache Spark y otras.
Reiniciar los servicios de clúster
Si experimenta ralentizaciones en el clúster, considere la posibilidad de reiniciar los servicios mediante la UI de Ambari o la CLI de Azure clásica. Es posible que el clúster esté experimentando errores transitorios y el reinicio es la forma más rápida de estabilizar su entorno y, posiblemente, de mejorar el rendimiento.
Paso 3: Ver el estado del clúster
Los clústeres de HDInsight se componen de diferentes tipos de nodos que se ejecutan en instancias de máquina virtual. Se puede supervisar cada nodo en busca de colapsos de recursos, problemas de conectividad de red y otros problemas que pueden ralentizar el clúster. Cada clúster contiene dos nodos principales y la mayoría de los tipos de clúster contiene una combinación de nodos perimetrales y de trabajo.
Para ver una descripción de los diversos nodos que usa cada tipo de clúster, consulte Configuración de clústeres en HDInsight con Apache Hadoop, Apache Spark, Apache Kafka, etc.
En las secciones siguientes se describe cómo comprobar el estado de cada nodo y del clúster general.
Obtener una instantánea del estado del clúster con el panel de UI de Ambari
El panel de UI de Ambari (https://<clustername>.azurehdinsight.net) proporciona una visión general del estado del clúster, como el tiempo de actividad, la memoria, el uso de red y CPU, el uso del disco de HDFS, etc. Utilice la sección de hosts de Ambari para ver los recursos en un nivel de host. También puede detener y reiniciar los servicios.
Comprobar el servicio de WebHCat
Un escenario común en el que se producen errores en Apache Hive, Apache Pig o Apache Sqoop consiste en un error con el servicio WebHCat (o Templeton). WebHCat es una interfaz REST para la ejecución del trabajo remoto, como Hive, Pig, Scoop y MapReduce. WebHCat traduce las solicitudes de envío de trabajo en aplicaciones de YARN de Apache Hadoop y devuelve un estado que se deriva del estado de la aplicación de YARN. En las siguientes secciones se describen los códigos de estado HTTP de WebHCat comunes.
BadGateway (código de estado 502)
Este código es un mensaje genérico de los nodos de la puerta de enlace y es el código de estado de error más común. Una posible causa es la caída del servicio de WebHCat en el nodo principal activo. Para comprobar esta posibilidad, use el siguiente comando de CURL:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari muestra una alerta que indica los hosts en los que se ha interrumpido el servicio WebHCat. Puede intentar acceder a la copia de seguridad del servicio de WebHCat mediante el reinicio del servicio en su host.
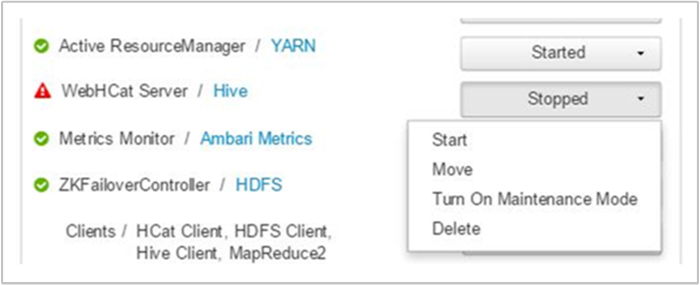
Si algún servidor WebHCat sigue sin aparecer, consulte el registro de operaciones para ver los mensajes de error. Para obtener información más detallada, consulte los archivos stderr y stdout a los que se hace referencia en el nodo.
Tiempo de espera de WebHCat agotado
Una puerta de enlace de HDInsight agota el tiempo de espera de las respuestas que tardan más de dos minutos y devuelve 502 BadGateway. WebHCat consulta los servicios de YARN para los estados de trabajo y, si YARN tarda más de dos minutos en responder, puede agotarse el tiempo de espera de la solicitud.
En este caso, revise los registros siguientes en el directorio /var/log/webhcat:
- webhcat.log es el registro de Log4j en el que el servidor escribe los registros
- webhcat-console.log es el stdout del servidor cuando se inicia
- webhcat-console-error.log es el stderr del proceso del servidor
Nota
Cada webhcat.log se sustituye diariamente, lo que genera archivos denominados webhcat.log.YYYY-MM-DD. Seleccione el archivo apropiado para el intervalo de tiempo que está investigando.
En las siguientes secciones se describen algunas posibles causas de los tiempos de espera de WebHCat.
Tiempo de espera de WebHCat
Cuando WebHCat está bajo carga, con más de 10 sockets abiertos, se tarda más tiempo en establecer nuevas conexiones de socket, lo que puede provocar que se agote el tiempo de espera. Para enumerar las conexiones de red que llegan y salen de WebHCat, use netstat en el nodo principal activo actual:
netstat | grep 30111
30111 es el puerto que escucha WebHCat. El número de sockets abiertos debe ser menor que 10.
Si no hay ningún socket abierto, el comando anterior no genera resultados. Para comprobar si Templeton está activo y escuchando en el puerto 30111, use:
netstat -l | grep 30111
Tiempo de espera de YARN
Templeton llama a YARN para ejecutar trabajos y la comunicación entre ambos puede provocar que se agote el tiempo de espera.
En el nivel de YARN, hay dos tipos de tiempos de expiración:
El envío de un trabajo de YARN puede tardar tiempo suficiente para que se agote el tiempo de espera.
Si abre el archivo de registro
/var/log/webhcat/webhcat.logy busca "trabajo en cola", es posible que vea varias entradas en las que el tiempo de ejecución sea excesivamente largo (más de 2000 ms), cuyas entradas muestran un aumento en los tiempos de espera.El tiempo de los trabajos en cola sigue aumentando porque la velocidad a la que se han enviado los trabajos nuevos es superior a la velocidad con que se completan los anteriores. Cuando el uso de la memoria de YARN está al 100%, la
joblauncher queueya no puede tomar prestada capacidad de la cola predeterminada. Por lo tanto, no se pueden aceptar más trabajos nuevos en la cola del iniciador de trabajos. Este comportamiento puede aumentar el tiempo de espera y provocar un error de tiempo de expiración, al que suelen seguir muchos más.En la siguiente imagen se muestra la cola del iniciador de trabajos con un uso excesivo del 714,4 %. Esto es aceptable siempre y cuando aún haya capacidad libre en la cola predeterminada que se pueda tomar prestada. Sin embargo, cuando el clúster se utiliza totalmente y la memoria YARN está al 100 % de su capacidad, los trabajos nuevos deben esperar, lo que finalmente provoca tiempos de espera.

Existen dos maneras de resolver este problema: reducir la velocidad de los trabajos nuevos que se envían o incrementar la velocidad de consumo de trabajos antiguos mediante el escalamiento vertical del clúster.
El procesamiento de YARN puede tardar mucho tiempo, lo que puede provocar que se agote el tiempo de expiración.
Enumeración de todos los trabajos: se trata de una llamada que tarda mucho. Esta llamada enumera las aplicaciones de YARN Resource Manager y, para cada aplicación completa, obtiene el estado de JobHistoryServer de YARN. Con un número mayor de trabajos, esta llamada puede agotar el tiempo de expiración.
Enumeración de trabajos con más de siete días: JobHistoryServer de YARN de HDInsight está configurado para conservar información de trabajos completados durante siete días (valor de
mapreduce.jobhistory.max-age-ms). Al intentar enumerar los resultados de trabajos purgados, se agota el tiempo de expiración.
Para diagnosticar estos problemas:
- Determine el intervalo de tiempo UTC para solucionar problemas
- Seleccione los archivos adecuados de
webhcat.log - Busque mensajes de ERROR y ADVERTENCIA durante ese tiempo
Otros errores de WebHCat
Código de estado HTTP 500
En la mayoría de los casos en los que WebHCat devuelve 500, el mensaje de error contiene detalles sobre este. En caso contrario, revise
webhcat.logpara ver los mensajes de ERROR y ADVERTENCIA.Errores de trabajo
Puede haber casos en los que las interacciones con WebHCat sean correctas, pero se produzcan errores en los trabajos.
Templeton recopila la salida de la consola de trabajo como
stderrenstatusdir, lo que a menudo resulta útil para solucionar problemas.stderrcontiene el identificador de aplicación de YARN de la consulta real.
Paso 4: Revisar las versiones y la pila del entorno
La página de pila y versión de la UI de Ambari proporciona información sobre la configuración de los servicios de clúster y el historial de versiones del servicio. Las versiones incorrectas de la biblioteca de servicio de Hadoop pueden ser una causa del error del clúster. En la interfaz de usuario de Ambari, seleccione el menú Admin y, después, Stacks and Versions (Pilas y versiones). Seleccione la pestaña Versiones en la página para ver la información de la versión del servicio:
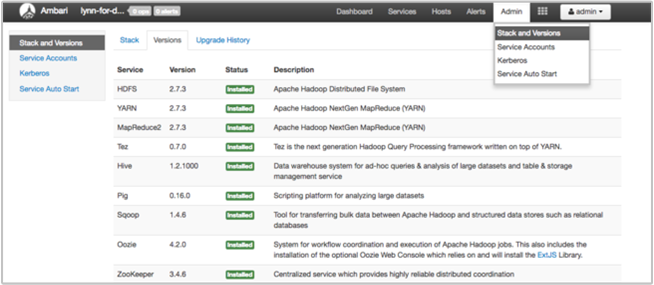
Paso 5: Examinar los archivos de registro
Hay muchos tipos de registros que se generan a partir de los diversos servicios y componentes que conforman un clúster de HDInsight. Los archivos de registro de WebHCat se han descrito anteriormente. Hay otros archivos de registro útiles que puede investigar para reducir los problemas relacionados con el clúster, tal como se describe en las secciones siguientes.
Los clústeres de HDInsight constan de varios nodos, a la mayoría de los cuales se les ha asignado la tarea de ejecutar trabajos enviados. Los trabajos se ejecutan simultáneamente, pero los archivos de registro solo pueden mostrar resultados de forma lineal. HDInsight ejecuta tareas nuevas y finaliza otras que no se han podido completar primero. Toda esta actividad se registra en los archivos
stderrysyslog.Los archivos de registro de acciones de script muestran errores o cambios de configuración inesperados durante el proceso de creación del clúster.
Los registros de paso de Hadoop identifican los trabajos de Hadoop iniciados como parte de un paso que contienen errores.
Comprobar los registros de acciones de script
Las acciones de script de HDInsight ejecutan scripts en un clúster manualmente o cuando se especifique. Por ejemplo, las acciones de script pueden utilizarse para instalar software adicional en el clúster o para modificar las opciones de configuración de los valores predeterminados. La comprobación de los registros de acciones de script puede proporcionar información sobre los errores que se produjeron durante la instalación y configuración del clúster. Puede ver el estado de una acción de script mediante la selección del botón Operaciones en la UI de Ambari o mediante el acceso a los registros de la cuenta de almacenamiento predeterminada.
Los registros de acciones de script residen en el directorio de \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE.
Ver registros de HDInsight con los vínculos rápidos de Ambari
La UI de HDInsight Ambari incluye una serie de secciones de vínculos rápidos. Para obtener acceso a los vínculos de registro de un servicio determinado en el clúster de HDInsight, abra la UI de Ambari del clúster, y, a continuación, seleccione el vínculo del servicio en la lista situada a la izquierda. Seleccione el menú desplegable Vínculos rápidos, luego el nodo de HDInsight que le interese y, después, el vínculo de su registro asociado.
Por ejemplo, para los registros HDFS:
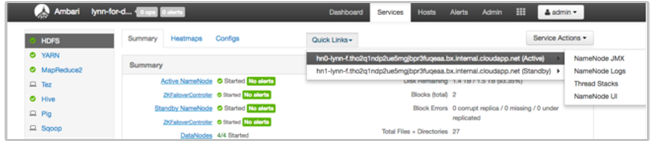
Ver los archivos de registro generados por Hadoop
Un clúster de HDInsight genera registros que se escriben en tablas de Azure y Azure Blob Storage. YARN crea sus propios registros de ejecución. Para más información, consulte Administrar los registros de clústeres de HDInsight.
Revisión de los volcados de montón
Los volcados del montón contienen una instantánea de la memoria de la aplicación, incluidos los valores de las variables en ese momento, que son útiles para diagnosticar los problemas que se producen durante el tiempo de ejecución. Para más información, consulte Habilitar los volcados de montón de los servicios de Apache Hadoop en HDInsight basado en Linux.
Paso 6: Comprobar las opciones de configuración
Los clústeres de HDInsight se configuran previamente con la configuración predeterminada para los servicios relacionados, como Hadoop, Hive, HBase, etc. En función del tipo de clúster, la configuración de hardware, el número de nodos, los tipos de trabajos que ejecute y los datos con los que esté trabajando (y cómo se procesen), puede que necesite optimizar su configuración.
Para obtener instrucciones detalladas acerca de cómo optimizar las configuraciones de rendimiento en la mayoría de los escenarios, consulte Optimización de configuraciones de clúster con Apache Ambari. Si usa Spark, consulte Optimización de trabajos de Azure Spark para mejorar el rendimiento.
Paso 7: Reproducir el error en un clúster diferente
Para ayudar a diagnosticar el origen de un error de clúster, inicie un clúster nuevo con la misma configuración y, a continuación, reenvíe los pasos del trabajo con errores uno por uno. Compruebe los resultados de cada paso antes de procesar el siguiente. Este método ofrece la oportunidad de corregir y volver a ejecutar un único paso con errores. Este método también tiene la ventaja de que carga los datos de entrada una sola vez.
- Cree un nuevo clúster de prueba con la misma configuración que el clúster con errores.
- Envíe el primer paso del trabajo para el clúster de prueba.
- Cuando el paso complete el procesamiento, compruebe si hay errores en los archivos de registro correspondientes. Conéctese al nodo maestro del clúster de prueba y vea los archivos de registro que se muestran. Los archivos de registro del paso solo aparecen después de que el paso se ejecute durante un tiempo, finalice o produzca un error.
- Si el primer paso se ha realizado correctamente, ejecute el siguiente. Si se han producido errores, investigue el error en los archivos de registro. Si se ha producido un error en el código, realice la corrección y vuelva a ejecutar el paso.
- Continúe hasta que todos los pasos se ejecuten sin errores.
- Al terminar de depurar el clúster de prueba, elimínelo.
Pasos siguientes
- Administración de clústeres de HDInsight con la interfaz de usuario web de Apache Ambari
- Análisis de registros de HDInsight
- Acceso a registros de aplicación de YARN de Apache Hadoop en HDInsight basado en Linux
- Habilitar los volcados de montón de los servicios de Apache Hadoop en HDInsight basado en Linux
- Problemas conocidos de clústeres de Apache Spark en HDInsight