Apache Phoenix en Azure HDInsight
Apache Phoenix es una capa de base de datos relacional de código abierto y masivamente paralela que se basa en Apache HBase. Phoenix permite usar consultas de tipo SQL sobre HBase. Phoenix usa controladores JDBC subyacentes para permitir a los usuarios crear, eliminar y modificar índices, vistas, secuencias y tablas SQL, así como realizar operaciones upsert en filas de forma individual o masiva. Phoenix usa la compilación nativa de NoSQL en lugar de usar MapReduce para compilar consultas, lo que permite crear aplicaciones de baja latencia a partir de HBase. Phoenix agrega coprocesadores para admitir la ejecución de código proporcionado por clientes en el espacio de direcciones del servidor, ejecutando el código colocado con los datos. Este enfoque minimiza la transferencia de datos entre cliente y servidor.
Apache Phoenix facilita las consultas de macrodatos a personas que no son desarrolladores, ya que pueden usar una sintaxis de tipo SQL en lugar de programación. Phoenix está altamente optimizado para HBase, a diferencia de otras herramientas como Apache Hive y Apache Spark SQL. La ventaja para los desarrolladores es que pueden escribir consultas de alto rendimiento con mucho menos código.
Cuando envía una consulta SQL, Phoenix compila la consulta para llamadas nativas de HBase y ejecuta el análisis (o plan) en paralelo para optimización. Gracias a esta capa de abstracción, el desarrollador no tiene que escribir trabajos de MapReduce y puede centrarse, en su lugar, en la lógica de negocios y el flujo de trabajo de la aplicación en torno al almacenamiento de macrodatos de Phoenix.
Optimización del rendimiento de consultas y otras características
Apache Phoenix agrega varias características y mejoras de rendimiento a las consultas de HBase.
Índices secundarios
HBase tiene un índice único, ordenado lexicográficamente por la clave de fila principal. Solo se puede obtener acceso a estos registros a través de la clave de fila. Para obtener acceso a los registros a través de cualquier columna que no sea la clave de fila se requiere examinar todos los datos mientras se aplica el filtro necesario. En un índice secundario, las columnas o expresiones se indexan desde una clave de fila alternativa, lo que permite búsquedas y exámenes de intervalo en ese índice.
Cree un índice secundario con el comando CREATE INDEX:
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Este enfoque puede producir un aumento significativo del rendimiento al ejecutar consultas con índice único. Este tipo de índice secundario es un índice de cobertura que contiene todas las columnas incluidas en la consulta. Por lo tanto, no es necesaria la búsqueda de tabla y el índice satisface toda la consulta.
Vistas
Las vistas de Phoenix proporcionan una manera de superar la limitación de HBase que consiste en que empieza a disminuir el rendimiento al crear más de 100 tablas físicas aproximadamente. Las vistas de Phoenix permiten a varias tablas virtuales compartir una tabla HBase física subyacente.
Crear una vista de Phoenix es similar a usar la sintaxis estándar de vista SQL. Una diferencia es que puede definir columnas para la vista, además de las columnas heredadas de la tabla base. También puede agregar nuevas columnas KeyValue.
Por ejemplo, esta es una tabla física denominada product_metrics con la siguiente definición:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Defina una vista sobre esta tabla, con más columnas:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
Para agregar más columnas posteriormente, use la instrucción ALTER VIEW.
Omitir examen
Omitir examen usa una o varias columnas de un índice compuesto para buscar valores DISTINCT. A diferencia de un examen de intervalo, Omitir examen implementa el análisis dentro de filas y produce un rendimiento mejorado. Al examinar, se omite el primer valor coincidente junto con el índice hasta que se encuentra el siguiente valor.
Omitir examen usa la enumeración SEEK_NEXT_USING_HINT del filtro HBase. Con SEEK_NEXT_USING_HINT, Omitir examen realiza un seguimiento de qué conjunto de claves o rangos de claves se buscan en cada columna. Omitir examen toma una clave que se le pasó durante la evaluación del filtro y determina si es una de las combinaciones. Si no lo es, Omitir examen evalúa la siguiente clave más alta a la que va a saltar.
Transacciones
Si bien HBase proporciona transacciones de nivel de fila, Phoenix se integra con Tephra para agregar compatibilidad con transacciones entre filas o entre tablas con semántica ACID completa.
Al igual que con las transacciones SQL tradicionales, las transacciones proporcionadas a través del administrador de transacciones de Phoenix permiten asegurarse de que una unidad atómica de datos se ha actualizado correctamente, lo que revierte la transacción si se produce un error en la operación de inserción o actualización en cualquier tabla habilitada para transacciones.
Para habilitar las transacciones de Phoenix, vea la documentación sobre las transacciones de Apache Phoenix.
Para crear una nueva tabla con las transacciones habilitadas, establezca la propiedad TRANSACTIONAL en true en una instrucción CREATE:
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
Para modificar una tabla existente para que sea transaccional, use la misma propiedad en una instrucción ALTER:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Nota
No se puede cambiar una tabla transaccional para que vuelva a ser no transaccional.
Tablas cifradas con sal
Puede producirse una zona activa del servidor de regiones al escribir registros con claves secuenciales en HBase. Aunque puede haber varios servidores de regiones en el clúster, todas las escrituras se producen en uno solo. Esta concentración crea el problema de zona activa donde, en lugar de que la carga de trabajo de escritura se distribuya entre todos los servidores de regiones disponibles, solo uno asume la carga. Puesto que cada región tiene un tamaño máximo predefinido, cuando una región alcanza ese límite de tamaño, se divide en dos regiones pequeñas. Cuando ocurre esto, una de estas regiones nuevas toma todos los nuevos registros y se convierte en la nueva zona activa.
Para mitigar este problema y lograr un mejor rendimiento, divida previamente las tablas para que todos los servidores de regiones se usen por igual. Phoenix proporciona tablas cifradas con sal, ya que agrega de forma transparente el byte de cifrado con sal a la clave de fila para una tabla determinada. La tabla se divide previamente en los límites del byte de cifrado con sal para garantizar la distribución igual de la carga entre los servidores de regiones durante la fase inicial de la tabla. Este enfoque distribuye la carga de trabajo de escritura entre todos los servidores de regiones disponibles y mejora el rendimiento de escritura y lectura. Para cifrar una tabla con sal, especifique la propiedad de tabla SALT_BUCKETS al crear la tabla:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Habilitar y ajustar Phoenix con Apache Ambari
Un clúster HDInsight HBase incluye la interfaz de usuario de Ambari para realizar cambios de configuración.
Para habilitar o deshabilitar Phoenix y para controlar la configuración de tiempo de espera de consulta de Phoenix, inicie sesión en la interfaz de usuario web de Ambari (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) con sus credenciales de usuario de Hadoop.Seleccione HBase en la lista de servicios en el menú de la izquierda y, a continuación, seleccione la pestaña Configs (Configuraciones).
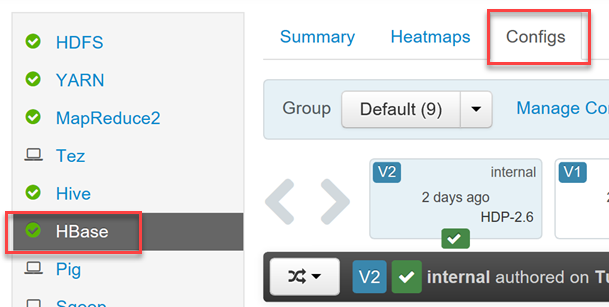
Busque la sección de configuración de Phoenix SQL para habilitar o deshabilitar Phoenix y establecer el tiempo de espera de consulta.