Uso de una canalización de análisis de datos
Las canalizaciones de datos son subyacentes a muchas soluciones de análisis de datos. Como sugiere su nombre, una canalización de datos toma datos sin procesar, los limpia y cambia su forma según sea necesario y normalmente realiza cálculos o agregaciones antes de almacenar los datos procesados. Los clientes, los informes o las API consumen los datos procesados. Una canalización de datos debe proporcionar resultados repetibles, ya sea en una programación o cuando se desencadena con datos nuevos.
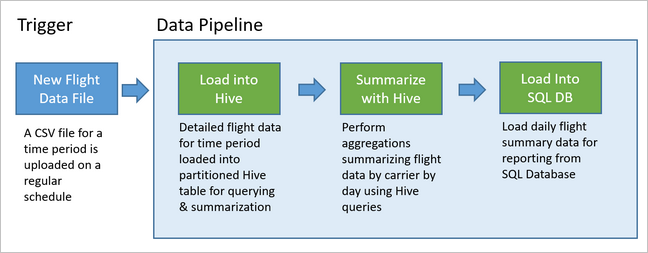
En este artículo se describe cómo poner en operación las canalizaciones de datos de modo que sean repetibles, mediante la ejecución de Oozie en clústeres de Hadoop de HDInsight. El escenario de ejemplo le guía a través de una canalización de datos que prepara y procesa los datos de una serie temporal de vuelos de una compañía aérea.
En el siguiente escenario, los datos de entrada son un archivo sin formato que contiene un lote de datos de vuelos de un mes. Estos datos de vuelo incluyen información como el aeropuerto de origen y destino, las millas de vuelo, las horas de salida y de llegada y así sucesivamente. El objetivo de esta canalización es resumir el rendimiento diario de las compañías aéreas, donde cada compañía tiene una fila por cada día con el retraso promedio de las salidas y las llegadas en minutos y el número total de millas voladas ese día.
| YEAR | MONTH | DAY_OF_MONTH | CARRIER | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
La canalización de ejemplo espera hasta que llegan los datos de un nuevo período vuelo y, a continuación, almacena la información detallada del vuelo en el almacenamiento de datos de Apache Hive para el análisis a largo plazo. La canalización crea también un conjunto de datos mucho menor que resume solo los datos de vuelos diarios. Estos datos de resumen diario de lanzamientos como paquete piloto se envían a una base de datos SQL para proporcionar informes, por ejemplo, para un sitio web.
El siguiente diagrama muestra la canalización de ejemplo.
Introducción a la solución de Apache Oozie
Esta canalización usa Apache Oozie en un clúster de Hadoop de HDInsight.
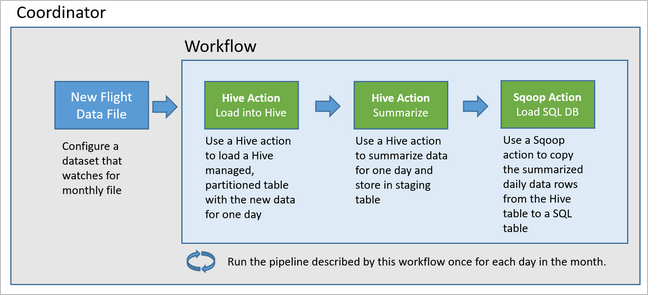
Oozie describe las canalizaciones en términos de acciones, flujos de trabajo y coordinadores. Las acciones determinan el trabajo real que se va a realizar, como la ejecución de una consulta de Hive. Los flujos de trabajo definen la secuencia de las acciones. Los coordinadores definen la programación de cuándo se ejecuta el flujo de trabajo. Los coordinadores también pueden esperar por la disponibilidad de nuevos datos antes de iniciar una instancia del flujo de trabajo.
El siguiente diagrama muestra el diseño de alto nivel de esta canalización de Oozie de ejemplo.
Aprovisionamiento de los recursos de Azure
Esta canalización requiere una base de datos de Azure SQL y un clúster de Hadoop de HDInsight en la misma ubicación. Azure SQL Database almacena tanto los datos de resumen producidos por la canalización como el almacén de metadatos de Oozie.
Aprovisionamiento de Azure SQL Database
Cree una base de datos de Azure SQL Database. Consulte Creación Azure SQL Database en Azure Portal.
Para asegurarse de que el clúster de HDInsight puede acceder a la instancia de Azure SQL Database conectada, configure las reglas de firewall de Azure SQL Database para permitir que los servicios y recursos de Azure accedan al servidor. Para habilitar esta opción en Azure Portal, haga clic en Establecer el firewall del servidor y, luego, seleccione Activado en Permitir que los servicios y recursos de Azure accedan a este servidor para Azure SQL Database. Para más información, consulte Creación y administración de reglas de firewall de IP.
Use el Editor de consultas para ejecutar las siguientes instrucciones SQL para crear la tabla
dailyflightsque almacenará los datos resumidos de cada ejecución de la canalización.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
La base de datos de Azure SQL Database ya está lista.
Aprovisionamiento de un clúster de Apache Hadoop
Cree un clúster de Apache Hadoop con un metastore personalizado. Durante la creación del clúster desde el portal, en la pestaña Almacenamiento, asegúrese de seleccionar su SQL Database en Configuración de metastore. Para más información sobre cómo seleccionar un metastore, consulte Seleccionar un metastore personalizado durante la creación del clúster. Para obtener más sobre la creación de un clúster, consulte Comenzar a usar HDInsight en Linux.
Verificación de la configuración de la tunelización SSH
Para usar la consola web de Oozie para ver el estado de las instancias del coordinador y del flujo de trabajo, configure un túnel SSH al clúster de HDInsight. Para más información, consulte Túnel SSH.
Nota
También puede usar Chrome con la extensión Foxy Proxy para examinar los recursos web del clúster a través del túnel SSH. Configúrelo para enviar por proxy todas las solicitudes a través del host localhost en el puerto 9876 del túnel. Este enfoque es compatible con el subsistema de Windows para Linux, también conocido como Bash en Windows 10.
Ejecute el siguiente comando para abrir un túnel SSH al clúster, donde
CLUSTERNAMEes el nombre del clúster:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netPara comprobar que el túnel está operativo, vaya a Ambari en el nodo principal a través de:
http://headnodehost:8080Para acceder a la consola Web de Oozie desde Ambari, vaya a Oozie>Quick Links> [Active Server] > Oozie Web UI (Vínculos rápidos > [Active Server] > Interfaz de usuario web de Oozie).
Configuración de Hive
Carga de datos
Descargue un archivo CSV de ejemplo que contiene los datos de los vuelos de un mes. Descargue el archivo ZIP
2017-01-FlightData.zipdesde el repositorio de GitHub de HDInsight y descomprima el archivo CSV2017-01-FlightData.csv.Copie este archivo CSV en la cuenta de Azure Storage conectada al clúster de HDInsight y colóquelo en la carpeta
/example/data/flights.Use SCP para copiar los archivos desde el equipo local al almacenamiento local del nodo principal del clúster de HDInsight.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvUse el comando SSH para conectarse al clúster. Modifique el comando siguiente: reemplace
CLUSTERNAMEpor el nombre del clúster y, luego, escriba el comando:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netDesde la sesión de SSH, use el comando HDFS para copiar el archivo desde el almacenamiento local del nodo principal a Azure Storage.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Crear tablas.
Los datos de ejemplo ahora están disponibles. Sin embargo, la canalización requiere dos tablas de Hive para el procesamiento, una para los datos entrantes (rawFlights) y otra para los datos resumidos (flights). Cree estas tablas en Ambari como se indica a continuación.
Inicie sesión en Ambari navegando a
http://headnodehost:8080.En la lista de servicios, seleccione Hive.
Seleccione Go To View (Ir a vista) junto a la etiqueta Hive View 2.0 (Vista de Hive 2.0).
En el área de texto de consultas, pegue las instrucciones siguientes para crear la tabla
rawFlights. La tablarawFlightsproporciona una esquema de lectura de los archivos CSV en la carpeta/example/data/flightsde Azure Storage.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Seleccione Execute (Ejecutar) para crear la tabla.
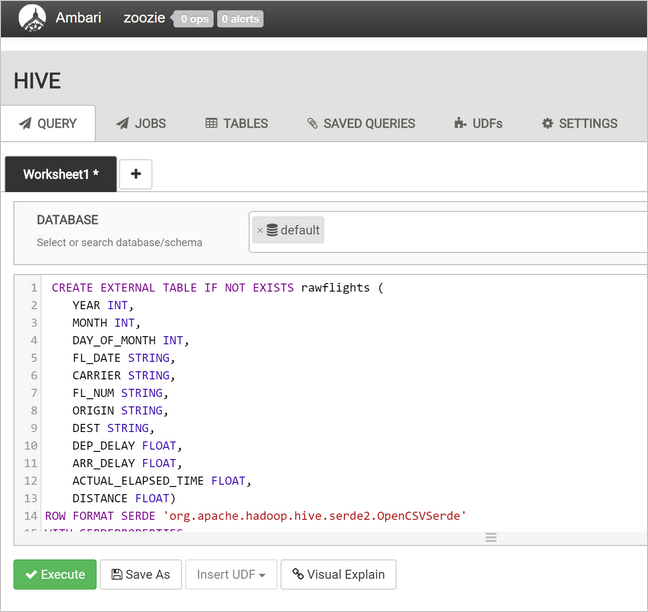
Para crear la tabla
flights, reemplace el texto en el área de texto de consultas por las instrucciones siguientes. La tablaflightses una tabla administrada de Hive que realiza una partición de los datos cargados por año, mes y día del mes. Esta tabla contendrá todos los datos históricos de vuelos, con la granularidad más baja presente en los datos de origen de una fila por cada vuelo.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Seleccione Execute (Ejecutar) para crear la tabla.
Creación del flujo de trabajo de Oozie
Las canalizaciones normalmente procesan los datos en lotes en un intervalo de tiempo determinado. En este caso, la canalización procesa los datos de vuelos diariamente. Este enfoque permite que la llegada de los archivos de entrada CSV sea diaria, semanal, mensual o anual.
El flujo de trabajo de ejemplo procesa los datos de vuelos día a día, en tres pasos principales:
- Ejecución de una consulta de Hive para extraer los datos para el intervalo de fechas de ese día desde el archivo CSV de origen representado por la tabla
rawFlightse inserción de los datos en la tablaflights. - Ejecución de una consulta de Hive para crear dinámicamente una tabla de almacenamiento provisional en Hive del día, que contiene una copia de los datos de vuelos resumidos por día y operador.
- Uso de Apache Sqoop para copiar todos los datos desde la tabla de almacenamiento provisional diaria en Hive a la tabla de destino
dailyflightsen Azure SQL Database. Sqoop lee las filas de origen de los datos de la tabla de Hive que residen en Azure Storage y los carga en la instancia de SQL Database mediante una conexión JDBC.
Estos tres pasos se coordinan mediante un flujo de trabajo de Oozie.
En la estación de trabajo local, cree un archivo denominado
job.properties. Use el texto siguiente como contenido inicial del archivo. Actualice los valores de su entorno específico. La siguiente tabla, ubicada bajo el texto, resume cada una de las propiedades e indica dónde puede encontrar los valores para su propio entorno.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Propiedad Origen del valor nameNode La ruta de acceso completa del contenedor de Azure Storage conectado al clúster de HDInsight. jobTracker El nombre de host interno del nodo principal de YARN del clúster activo. En la página principal de Ambari, seleccione YARN desde la lista de servicios y luego elija Active Resource Manager (Administrador de recursos activo). El identificador URI del nombre de host se muestra en la parte superior de la página. Anexe el puerto 8050. queueName El nombre de la cola YARN usada al programar las acciones de Hive. Deje el valor predeterminado. oozie.use.system.libpath Dejar como true. appBase La ruta de acceso a la subcarpeta de Azure Storage en la que se implementa el flujo de trabajo de Oozie y los archivos auxiliares. oozie.wf.application.path La ubicación del flujo de trabajo de Oozie workflow.xmlque se va a ejecutar.hiveScriptLoadPartition La ruta de acceso en Azure Storage del archivo de consulta de Hive hive-load-flights-partition.hql.hiveScriptCreateDailyTable La ruta de acceso en Azure Storage del archivo de consulta de Hive hive-create-daily-summary-table.hql.hiveDailyTableName El nombre generado de forma dinámica que se utilizará para la tabla de almacenamiento provisional. hiveDataFolder La ruta de acceso en Azure Storage a los datos contenidos en la tabla de almacenamiento provisional. sqlDatabaseConnectionString La cadena de conexión con sintaxis JDBC a su base de datos de Azure SQL. sqlDatabaseTableName El nombre de la tabla en Azure SQL Database en la que se insertan las filas de resumen. Dejar como dailyflights.year El componente año del día cuyos resúmenes de vuelos se calculan. Déjelo tal cual. month El componente mes del día cuyos resúmenes de vuelos se calculan. Déjelo tal cual. day El componente día del día cuyos resúmenes de vuelos se calculan. Déjelo tal cual. En la estación de trabajo local, cree un archivo denominado
hive-load-flights-partition.hql. Use el siguiente código como contenido del archivo.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Las variables de Oozie utilizan la sintaxis
${variableName}. Estas variables se establecen en el archivojob.properties. Oozie sustituye los valores reales en tiempo de ejecución.En la estación de trabajo local, cree un archivo denominado
hive-create-daily-summary-table.hql. Use el siguiente código como contenido del archivo.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Esta consulta crea una tabla de almacenamiento provisional que almacenará únicamente los datos resumidos de un día; observe la instrucción SELECT que calcula los retrasos promedio y la distancia total volada por el operador por día. Los datos insertados en esta tabla se almacenan en una ubicación conocida (la ruta de acceso indicada por la variable hiveDataFolder) para que se pueda utilizar como el origen para Sqoop en el paso siguiente.
En la estación de trabajo local, cree un archivo denominado
workflow.xml. Use el siguiente código como contenido del archivo. Estos pasos anteriores se expresan como acciones independientes en el archivo de flujo de trabajo de Oozie.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
Se tiene acceso a las dos consultas de Hive mediante su ruta de acceso en Azure Storage y los valores de las variables restantes se proporcionan en el archivo job.properties. Este archivo configura la ejecución del flujo de trabajo para el 3 de enero de 2017.
Implementación y ejecución del flujo de trabajo de Oozie
Utilice SCP desde la sesión de bash para implementar el flujo de trabajo de Oozie (workflow.xml), las consultas de Hive (hive-load-flights-partition.hql y hive-create-daily-summary-table.hql) y la configuración del trabajo (job.properties). En Oozie, solo puede existir el archivo job.properties en el almacenamiento local del nodo principal. Todos los demás archivos deben almacenarse en HDFS, en este caso en Azure Storage. La acción de Sqoop utilizada por el flujo de trabajo depende de un controlador JDBC para comunicarse con la instancia de SQL Database, que se debe copiar desde el nodo principal a HDFS.
Cree la subcarpeta
load_flights_by_daybajo la ruta de acceso del usuario en el almacenamiento local del nodo principal. Ejecute el siguiente comando en la sesión SSH abierta:mkdir load_flights_by_dayCopie todos los archivos del directorio actual (los archivos
workflow.xmlyjob.properties) a la subcarpetaload_flights_by_day. Ejecute el siguiente comando en la estación de trabajo local:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_dayCopie los archivos del flujo de trabajo a HDFS. Ejecute los siguientes comandos en la sesión SSH abierta:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_dayCopie
mssql-jdbc-7.0.0.jre8.jardesde el nodo principal local a la carpeta del flujo de trabajo en HDFS. Revise el comando según sea necesario si el clúster contiene un archivo jar diferente. Reviseworkflow.xmlsegún sea necesario para reflejar un archivo jar diferente. Ejecute el siguiente comando en la sesión SSH abierta:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayEjecute el flujo de trabajo. Ejecute el siguiente comando en la sesión SSH abierta:
oozie job -config job.properties -runObserve el estado mediante la consola web de Oozie. Desde dentro de Ambari, seleccione Oozie, Quick Links (Vínculos rápidos) y, a continuación, Oozie Web Console (Consola web de Oozie). En la pestaña Workflow Jobs (Trabajos del flujo de trabajo), seleccione All Jobs (Todos los trabajos).
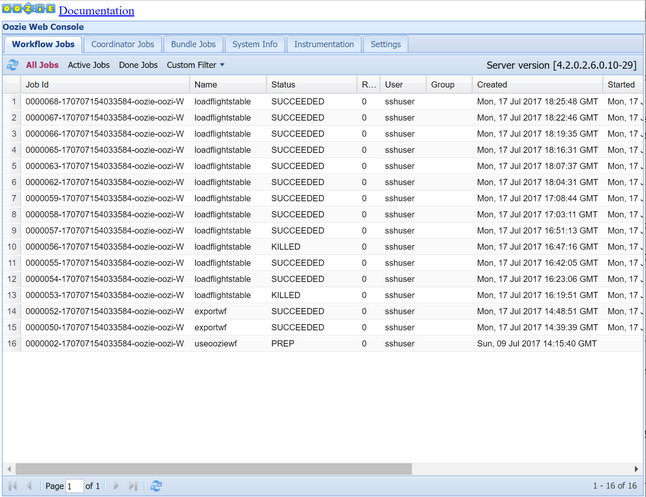
Cuando el estado sea SUCCEEDED (CORRECTO), consulte la tabla de SQL Database para ver las filas insertadas. En Azure Portal, vaya al panel de la base de datos SQL, seleccione Herramientas y abra el Editor de consultas.
SELECT * FROM dailyflights
Ahora que el flujo de trabajo se está ejecutando para el día de la prueba individual, puede encapsular este flujo de trabajo con un coordinador que programe el flujo de trabajo para que se ejecute diariamente.
Ejecución del flujo de trabajo con un coordinador
Puede usar un coordinador para programar que este flujo de trabajo se ejecute diariamente (o todos los días en un intervalo de fechas). Un coordinador se define mediante un archivo XML, por ejemplo coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Como puede ver, la mayor parte del coordinador consiste simplemente en el paso de información de configuración a la instancia del flujo de trabajo. Sin embargo, hay algunos elementos importantes que destacar.
Punto 1: los atributos
startyenddel elementocoordinator-appcontrolan el intervalo de tiempo en el que se ejecuta el coordinador.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Un coordinador es responsable de programar acciones dentro del intervalo de fechas
startyend, según el intervalo especificado en el atributofrequency. Cada acción programada, a su vez, ejecuta el flujo de trabajo según la configuración. En la definición de coordinador anterior, el coordinador está configurado para ejecutar acciones desde el 1 hasta el 5 de enero de 2017. La expresión de frecuencia${coord:days(1)}del lenguaje de expresiones de Oozie establece la frecuencia en un día. Como resultado, el coordinador programa una acción (y por lo tanto, el flujo de trabajo) una vez al día. Para intervalos de fechas que se encuentran en el pasado, como en este ejemplo, la acción se programará para que se ejecute sin retraso. La fecha de inicio para la que se ha programado la ejecución de una acción se llama hora nominal. Por ejemplo, para procesar los datos desde el 1 de enero de 2017, el coordinador programará una acción con una hora nominal de 2017-01-01T00:00:00 GMT.Punto 2: dentro del intervalo de fechas del flujo de trabajo, el elemento
datasetespecifica dónde buscar los datos de un intervalo de fechas determinado en HDFS y configura el modo en que Oozie determina si los datos están disponibles aún para su procesamiento.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>La ruta de acceso a los datos en HDFS se genera dinámicamente según la expresión proporcionada en el elemento
uri-template. En este coordinador se utiliza también una frecuencia de un día con el conjunto de datos. Mientras que las fechas de inicio y final en el elemento coordinador controlan cuándo se programan las acciones (y define sus horas nominales), los elementosinitial-instanceyfrequencydel conjunto de datos controlan el cálculo de la fecha que se utiliza para construiruri-template. En este caso, establezca la instancia inicial en un día antes del inicio del coordinador para asegurarse de que recoge el primer día (1 de enero, 2017) del período de datos. El cálculo de la fecha del conjunto de datos se pone al día desde el valor deinitial-instance(31/12/2016) en incrementos de la frecuencia del conjunto de datos (un día) hasta que encuentra la fecha más reciente que no supera la hora nominal establecida por el coordinador (2017-01-01T00:00:00 GMT para la primera acción).El elemento
done-flagvacío indica que cuando Oozie comprueba la presencia de datos de entrada en el momento prefijado, Oozie determina si los datos están disponibles por la presencia de un directorio o archivo. En este caso es la presencia de un archivo csv. Si hay un archivo csv, Oozie da por supuesto que los datos están listos e inicia una instancia del flujo de trabajo para procesar el archivo. Si no hay ningún archivo csv, Oozie supone que los datos todavía no están preparados y esa ejecución del flujo de trabajo entra en estado de espera.Punto 3: el elemento
data-inespecifica la marca de tiempo que se usará como hora nominal al reemplazar los valores deuri-templatepara el conjunto de datos asociado.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>En este caso, establezca la instancia en la expresión
${coord:current(0)}, lo que se traduce en utilizar la hora nominal de la acción tal como la programó el coordinador originalmente. En otras palabras, cuando el coordinador programa la ejecución de la acción con una hora nominal de 01/01/2017, significa que se utiliza 01/01/2017 para reemplazar las variables YEAR (2017) y MONTH (01) en la plantilla URI. Una vez que se calcula la plantilla URI de esta instancia, Oozie comprueba si el directorio o el archivo esperados están disponibles y programa la próxima ejecución del flujo de trabajo según corresponda.
Los tres puntos anteriores se combinan para producir una situación en la que el coordinador programa el procesamiento de los datos de origen en una base de día a día.
Punto 1: el coordinador comienza con una fecha nominal de 2017-01-01.
Punto 2: Oozie busca los datos disponibles en
sourceDataFolder/2017-01-FlightData.csv.Punto 3: cuando Oozie encuentra el archivo, programa una instancia del flujo de trabajo que procesará los datos del 1 de enero de 2017. Oozie, a continuación, continúa el procesamiento del 2017-01-02. Esta evaluación se repite hasta el 2017-01-05, pero sin incluirlo.
Como con los flujos de trabajo, la configuración de un coordinador se define en un archivo job.properties, que tiene un supraconjunto de la configuración utilizada por el flujo de trabajo.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
Las únicas propiedades nuevas introducidas en este archivo job.properties son:
| Propiedad | Origen del valor |
|---|---|
| oozie.coord.application.path | Indica la ubicación del archivo coordinator.xml que contiene el coordinador de Oozie a ejecutar. |
| hiveDailyTableNamePrefix | Prefijo que se usa al crear dinámicamente el nombre de la tabla de almacenamiento provisional. |
| hiveDataFolderPrefix | Prefijo de la ruta de acceso donde se almacenarán todas las tablas de almacenamiento provisional. |
Implementación y ejecución del coordinador de Oozie
Para ejecutar la canalización con un coordinador, proceda de forma similar a la del flujo de trabajo, excepto que trabajará desde una carpeta un nivel por encima de la carpeta que contiene el flujo de trabajo. Esta convención de carpetas separa los coordinadores de los flujos de trabajo en el disco, por lo que se puede asociar un coordinador con flujos de trabajo secundarios diferentes.
Use SCP desde el equipo local para copiar los archivos del coordinador al almacenamiento local del nodo principal del clúster.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~Conéctese con SSH al nodo principal.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netCopie los archivos del coordinador al HDFS.
hdfs dfs -put ./* /oozie/Ejecute el coordinador.
oozie job -config job.properties -runCompruebe el estado mediante la consola web de Oozie, en esta ocasión, mediante la selección de la pestaña Coordinator Jobs (Trabajos del coordinador) y, a continuación, All jobs (Todos los trabajos).
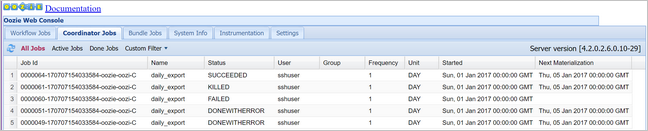
Seleccione una instancia del coordinador para mostrar la lista de acciones programadas. En este caso, debería ver cuatro acciones con horas nominales en el intervalo del 1 de enero de 2017 al 4 de enero de 2017.
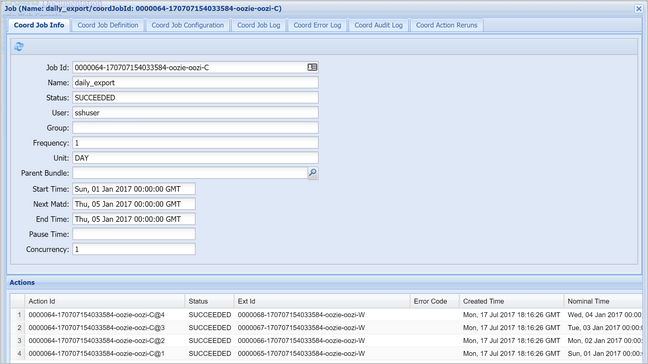
Cada acción de esta lista se corresponde con una instancia del flujo de trabajo que procesa un día de datos, donde el inicio de ese día se indica en la hora nominal.