Tutorial: Uso de Apache HBase in Azure HDInsight
Este tutorial muestra cómo crear un clúster de Apache HBase en Azure HDInsight, crear tablas de HBase y consultar tablas mediante Apache Hive. Para obtener información general de HBase, consulte este artículo de información general de HBase en HDInsight.
En este tutorial, aprenderá a:
- Crear clústeres de Apache HBase
- Creación de tablas de HBase e inserción de datos
- Usar Apache Hive para consultar Apache HBase
- Usar las API de REST de HBase con Curl
- Comprobar el estado del clúster
Prerrequisitos
Un cliente SSH. Para más información, consulte Conexión a través de SSH con HDInsight (Apache Hadoop).
Bash. Los ejemplos de este artículo usan el shell de Bash en Windows 10 para los comandos de curl. Consulte la Guía de instalación del subsistema de Windows para Linux para Windows 10 para conocer los pasos de instalación. Otros shells de Unix también funcionarán. Los ejemplos de curl, con algunas pequeñas modificaciones, pueden funcionar en un símbolo del sistema de Windows. También puede usar el cmdlet de Windows PowerShell Invoke-RestMethod.
Crear clústeres de Apache HBase
El siguiente procedimiento utiliza una plantilla de Azure Resource Manager para crear un clúster de HBase. La plantilla también crea la cuenta de Azure Storage predeterminada dependiente. Para comprender los parámetros utilizados en el procedimiento y otros métodos de creación del clúster, consulte Creación de clústeres de Hadoop basados en Linux en HDInsight.
Seleccione la imagen siguiente para abrir la plantilla en Azure Portal. La plantilla se encuentra en las plantillas de inicio rápido de Azure.

En el cuadro de diálogo Implementación personalizada, escriba los valores siguientes:
Propiedad Descripción Subscription seleccione la suscripción de Azure que usa para crear este clúster. Resource group cree un grupo de administración de recursos de Azure o use uno existente. Location especifique la ubicación del grupo de recursos. ClusterName escriba el nombre del clúster de HBase. Nombre de inicio de sesión y contraseña del clúster El nombre de inicio de sesión predeterminado es admin.Nombre de usuario y contraseña de SSH El nombre de usuario predeterminado es sshuser.Otros parámetros son opcionales.
Cada clúster tiene una dependencia de cuenta de Azure Storage. Después de eliminar un clúster, los datos permanecen en la cuenta de almacenamiento. El nombre de cuenta de almacenamiento de clúster predeterminado es el nombre del clúster con "store" anexado. Está codificado de forma rígida en la sección de variables de plantilla.
Seleccione Acepto los términos y condiciones indicadas anteriormente y, después, seleccione Comprar. Se tarda aproximadamente 20 minutos en crear un clúster.
Después de que se elimine un clúster de HBase, puede crear otro clúster de HBase mediante el mismo contenedor de blobs predeterminado. El nuevo clúster selecciona las tablas de HBase que creó en el clúster original. Para evitar incoherencias, recomendamos deshabilitar las tablas de HBase antes de eliminar el clúster.
Creación de tablas e inserción de datos
Puede usar SSH para conectarse a los clústeres de HBase y, después, usar el shell de Apache HBase para crear tablas de HBase e insertar y consultar datos.
Para la mayoría de las personas, los datos aparecen en formato tabular:

En HBase (una implementación de Cloud BigTable), los mismos datos tienen un aspecto similar al siguiente:

Para usar el shell de HBase, siga estos pasos:
Use el comando
sshpara conectarse al clúster de HBase. Modifique el siguiente comando: reemplaceCLUSTERNAMEpor el nombre del clúster y, luego, escriba el comando:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUse el comando
hbase shellpara iniciar el shell interactivo de HBase. Escriba el siguiente comando en la conexión SSH:hbase shellUse el comando
createpara crear una tabla de HBase con dos familias de columnas. Los nombres de columna y tabla distinguen mayúsculas de minúsculas. Escriba el comando siguiente:create 'Contacts', 'Personal', 'Office'Use el comando
listpara mostrar todas las tablas de HBase. Escriba el comando siguiente:listUse el comando
putpara insertar valores en una columna especificada en una fila especificada de una tabla determinada. Escriba los siguientes comandos:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Use el comando
scanpara buscar y devolver los datos de tablaContacts. Escriba el comando siguiente:scan 'Contacts'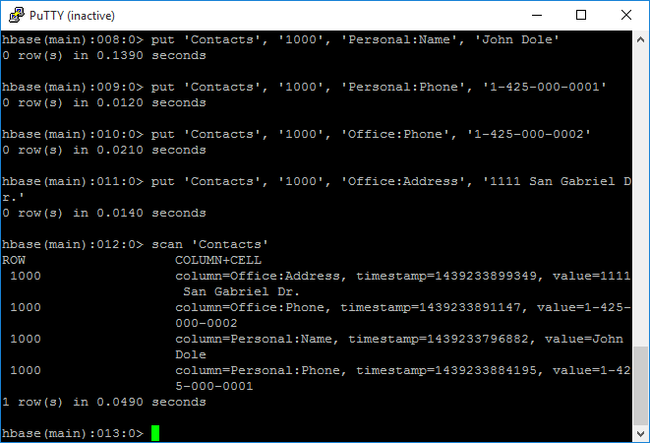
Use el comando
getpara capturar el contenido de una fila. Escriba el comando siguiente:get 'Contacts', '1000'Observará que los resultados son similares a los del comando
scanporque solo hay una fila.Para más información sobre el esquema de tabla de HBase, consulte Introduction to Apache HBase Schema Design (Introducción al diseño de esquema de Apache HBase). Para ver más comandos de HBase, consulte Guía de referencia de Apache HBase.
Use el comando
exitpara detener el shell interactivo de HBase. Escriba el comando siguiente:exit
Para cargar datos de forma masiva en la tabla HBase de contactos
HBase incluye varios métodos de carga de datos en las tablas. Para obtener más información, vea Carga masiva.
Se puede encontrar un archivo de datos de ejemplo en un contenedor de blobs público, wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. El contenido del archivo de datos es:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
Opcionalmente, puede crear un archivo de texto y cargarlo en su propia cuenta de almacenamiento. Para obtener instrucciones, consulte Carga de datos para trabajos de Apache Hadoop en HDInsight.
Este procedimiento usa la tabla HBase Contacts que creó en el último procedimiento.
Desde la conexión SSH abierta, ejecute el siguiente comando para transformar el archivo de datos en StoreFiles y almacenarlo en una ruta de acceso relativa especificada por
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtEjecute el siguiente comando para cargar los datos desde
/example/data/storeDataFileOutputen la tabla de HBase:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsPuede abrir el shell de HBase y usar el comando
scanpara mostrar el contenido de la tabla.
Usar Apache Hive para consultar Apache HBase
Puede consultar datos en las tablas de HBase mediante Apache Hive. En esta sección, creará una tabla de Hive que se asigna a la tabla de HBase y la usará para consultar los datos de la tabla de HBase.
En la conexión SSH abierta, use el siguiente comando para iniciar Beeline:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminPara más información sobre Beeline, consulte Uso de Hive con Hadoop en HDInsight con Beeline.
Ejecute el siguiente script de HiveQL para crear una tabla de Hive que se asigne a la tabla de HBase. Asegúrese de haber creado la tabla de ejemplo a la que se hace referencia anteriormente en este artículo mediante el shell de HBase antes de ejecutar esta instrucción.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Ejecute el siguiente script de HiveQL para consultar los datos de la tabla de HBase:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Para salir de Beeline, use
!exit.Para cerrar la conexión SSH, use
exit.
Clústeres de Hive y HBase independientes
No es necesario ejecutar la consulta de Hive para acceder a los datos de HBase desde el clúster de HBase. Cualquier clúster que incluya Hive (incluidos Spark, Hadoop, HBase o Interactive Query) se puede usar para consultar datos de HBase, siempre que se hayan completado los siguientes pasos:
- Ambos clústeres deben estar conectados a la misma red virtual y subred.
- Copie
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmldesde los nodos principales del clúster de HBase a los nodos principales y de trabajo del clúster de Hive.
Protección de los clústeres
También se pueden consultar los datos de HBase desde Hive mediante HBase habilitado para ESP:
- Cuando se sigue un patrón de varios clústeres, ambos clústeres deben estar habilitados para ESP.
- Para permitir que Hive consulte los datos de HBase, asegúrese de que el usuario
hivetiene permisos para acceder a los datos de HBase mediante el complemento Apache Ranger de HBase. - Cuando usa clústeres independientes habilitados para ESP, el contenido del archivo
/etc/hostsde los nodos principales del clúster de HBase se debe anexar al archivo/etc/hostsde los nodos principales y de trabajo del clúster de Hive.
Nota:
Después de escalar los clústeres, se debe anexar de nuevo el archivo /etc/hosts.
Uso de la API REST de HBase mediante Curl
La API REST de HBase se protege con la autenticación básica. Siempre debe crear solicitudes usando HTTP segura (HTTPS) para así garantizar que las credenciales se envían de manera segura al servidor.
Para habilitar las API REST de HBase en el clúster de HDInsight, agregue el siguiente script de inicio personalizado a la sección Acción de script. Puede agregar el script de inicio al crear el clúster o después de que se haya creado el clúster. En Tipo de nodo, seleccione Servidores de regiones para asegurarse de que el script se ejecuta solo en los servidores de regiones de HBase. El script inicia el proxy de REST de HBase en el puerto 8090 en servidores de región.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiEstablezca la variable de entorno por facilidad de uso. Edite los comandos siguientes al reemplazar
MYPASSWORDpor la contraseña de inicio de sesión del clúster. ReemplaceMYCLUSTERNAMEpor el nombre del clúster de HBase. Después, escriba los comandos.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEUse el siguiente comando para enumerar las tablas de HBase existentes:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Use el siguiente comando para crear una nueva tabla de HBase con dos familias de columnas:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vEl esquema se ofrece con el formato JSON.
Use el siguiente comando para instalar algunos datos:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vDebe codificar en Base64 los valores especificados en el modificador -d. En el ejemplo:
MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Personal: Nombre
Sm9obiBEb2xl: John Doe
false-row-key permite insertar varios valores (por lotes).
Use el siguiente comando para obtener una fila:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Nota:
Todavía no se admite el examen a través del punto de conexión del clúster.
Para más información sobre Rest de HBase, consulte la guía de referencia de Apache HBase.
Nota
Thrift no es compatible con HBase en HDInsight.
Al usar Curl o cualquier otra comunicación REST con WebHCat, debe proporcionar el nombre de usuario y la contraseña del administrador del clúster de HDInsight para autenticar las solicitudes. También debe usar el nombre del clúster como parte del identificador uniforme de recursos (URI) que se utiliza para enviar las solicitudes al servidor:
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Recibirá una respuesta similar a la siguiente:
{"status":"ok","version":"v1"}
Comprobar el estado del clúster
HBase en HDInsight se incluye con una interfaz de usuario web para la supervisión de clústeres. Mediante la interfaz de usuario web, puede solicitar estadísticas o información acerca de las regiones.
Para acceder a la interfaz de usuario maestra de HBase
Inicie sesión en la interfaz de usuario de Ambari Web en
https://CLUSTERNAME.azurehdinsight.net, dondeCLUSTERNAMEes el nombre del clúster de HBase.Seleccione HBase en el menú izquierdo.
Seleccione Vínculos rápidos en la parte superior de la página, seleccione el vínculo del nodo Zookeeper activo y, después, haga clic en HBase Master UI (Interfaz de usuario maestra de HBase). La interfaz de usuario se abre en otra pestaña del explorador:
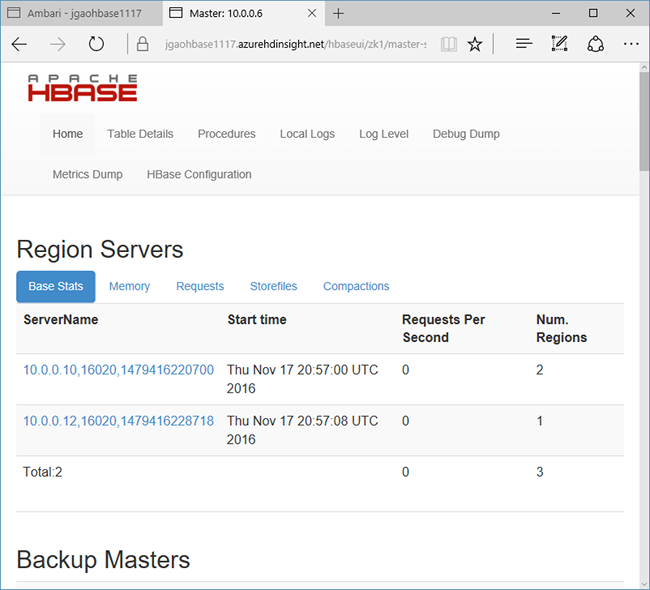
La interfaz de usuario maestra de HBase contiene las siguientes secciones:
- servidores regionales
- maestros de copia de seguridad
- tablas
- tareas
- atributos de software
Recreación del clúster
Después de que se elimine un clúster de HBase, puede crear otro clúster de HBase mediante el mismo contenedor de blobs predeterminado. El nuevo clúster selecciona las tablas de HBase que creó en el clúster original. No obstante, para evitar incoherencias, se recomienda deshabilitar las tablas de HBase antes de eliminar el clúster.
Puede usar el comando de HBase disable 'Contacts'.
Limpieza de recursos
Si no va a seguir usando esta aplicación, puede eliminar el clúster HBase que creó mediante los siguientes pasos:
- Inicie sesión en Azure Portal.
- En el cuadro Búsqueda en la parte superior, escriba HDInsight.
- Seleccione Clústeres de HDInsight en Servicios.
- En la lista de clústeres de HDInsight que aparece, haga clic en el signo ... situado junto al clúster que ha creado para este tutorial.
- Haga clic en Eliminar. Haga clic en Sí.
Pasos siguientes
En este tutorial, ha aprendido a crear un clúster de Apache HBase. Y también cómo crear tablas y ver los datos de esas tablas desde el shell de HBase. También ha aprendido a usar una consulta de Hive sobre los datos de las tablas de HBase. Además, ya sabe cómo usar las API de REST de C# para HBase para crear una tabla de HBase y recuperar los datos de la tabla. Para obtener más información, consulte: