Use las funciones definidas por el usuario de C# con el streaming de Apache Hive y Apache Pig en Apache Hadoop de HDInsight.
Aprenda a usar funciones definidas por el usuario (UDF) de C# con Apache Hive y Apache Pig en HDInsight.
Importante
Los pasos que se describen en este documento funcionan con clústeres de HDInsight basado en Linux. Linux es el único sistema operativo que se usa en la versión 3.4 de HDInsight, o en las superiores. Para obtener más información, consulte el artículo relativo al control de versiones de componentes de HDInsight.
Tanto Hive como Pig pueden pasar datos a aplicaciones externas para el procesamiento. Este proceso se conoce como streaming. Cuando se usa una aplicación .NET, los datos se pasan a la aplicación en STDIN y la aplicación devuelve los resultados en STDOUT. Para leer y escribir en STDIN y STDOUT, puede usar Console.ReadLine() y Console.WriteLine() desde una aplicación de la consola.
Requisitos previos
Estar familiarizado con la escritura y la compilación del código C# orientado a .NET Framework 4.5.
Use el IDE que prefiera. Recomendamos Visual Studio o Visual Studio Code. En los pasos descritos en este documento se utiliza Visual Studio 2019.
Una manera de cargar archivos .exe en el clúster y ejecutar trabajos de Pig y Hive. Es aconsejable usar las herramientas de Data Lake para Visual Studio, Azure PowerShell y CLI de Azure. En los pasos descritos en este documento se emplean las herramientas Data Lake para Visual Studio para cargar los archivos y ejecutar la consulta de ejemplo de Hive.
Para obtener información sobre otras formas de ejecutar consultas de Hive, consulte ¿Qué son Apache Hive y HiveQL en Azure HDInsight?
Hadoop en un clúster de HDInsight. Para obtener más información sobre cómo crear un clúster, consulte Creación de clústeres de HDInsight.
.NET en HDInsight
Los clústeres de HDInsight basados en Linux usan Mono (https://mono-project.com) para ejecutar aplicaciones .NET. La versión 4.2.1 de Mono está incluida en la versión 3.6 de HDInsight.
Si desea conocer más detalles sobre la compatibilidad entre Mono y las versiones de .NET Framework, consulte la página en la que se trata la compatibilidad de Mono.
Para obtener más información sobre la versión de .NET Framework y Mono incluida en las versiones de HDInsight, consulte el artículo relativo a las versiones de componentes de HDInsight.
Creación de proyectos de C#
En las siguientes secciones se describe cómo crear un proyecto de C# en Visual Studio para una UDF de Apache Hive y una UDF de Apache Pig.
UDF de Apache Hive
Para crear un proyecto de C# para una UDF de Apache Hive:
Inicie Visual Studio.
Seleccione Crear un proyecto.
En la ventana Crear un proyecto, seleccione la plantilla Aplicación de consola (.NET Framework) (la versión de C#). Luego, seleccione Siguiente.
En la ventana Configurar el nuevo proyecto, escriba un nombre de proyecto de HiveCSharp y vaya a una ubicación donde guardar el nuevo proyecto o créela. Seleccione Crear.
En el IDE de Visual Studio, reemplace el contenido de Program.cs por el código siguiente:
using System; using System.Security.Cryptography; using System.Text; using System.Threading.Tasks; namespace HiveCSharp { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Parse the string, trimming line feeds // and splitting fields at tabs line = line.TrimEnd('\n'); string[] field = line.Split('\t'); string phoneLabel = field[1] + ' ' + field[2]; // Emit new data to stdout, delimited by tabs Console.WriteLine("{0}\t{1}\t{2}", field[0], phoneLabel, GetMD5Hash(phoneLabel)); } } /// <summary> /// Returns an MD5 hash for the given string /// </summary> /// <param name="input">string value</param> /// <returns>an MD5 hash</returns> static string GetMD5Hash(string input) { // Step 1, calculate MD5 hash from input MD5 md5 = System.Security.Cryptography.MD5.Create(); byte[] inputBytes = System.Text.Encoding.ASCII.GetBytes(input); byte[] hash = md5.ComputeHash(inputBytes); // Step 2, convert byte array to hex string StringBuilder sb = new StringBuilder(); for (int i = 0; i < hash.Length; i++) { sb.Append(hash[i].ToString("x2")); } return sb.ToString(); } } }En la barra de menús, seleccione Compilar>Compilar solución para compilar el proyecto.
Cierre la solución.
UDF de Apache Pig
Para crear un proyecto de C# para una UDF de Apache Hive:
Abra Visual Studio.
En la ventana Inicio, seleccione Crear un proyecto.
En la ventana Crear un proyecto, seleccione la plantilla Aplicación de consola (.NET Framework) (la versión de C#). Luego, seleccione Siguiente.
En la ventana Configurar el nuevo proyecto, escriba un nombre de proyecto de PigUDF y vaya a una ubicación donde guardar el nuevo proyecto o créela. Seleccione Crear.
En el IDE de Visual Studio, reemplace el contenido de Program.cs por el código siguiente:
using System; namespace PigUDF { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Fix formatting on lines that begin with an exception if(line.StartsWith("java.lang.Exception")) { // Trim the error info off the beginning and add a note to the end of the line line = line.Remove(0, 21) + " - java.lang.Exception"; } // Split the fields apart at tab characters string[] field = line.Split('\t'); // Put fields back together for writing Console.WriteLine(String.Join("\t",field)); } } } }Este código analiza las líneas que se envían desde Pig y cambia el formato de las que comienzan por
java.lang.Exception.En la barra de menús, elija Compilar>Compilar solución para compilar el proyecto.
Deje abierta la solución.
Carga en el almacenamiento
A continuación, cargue las aplicaciones UDF de Hive y Pig que se van a almacenar en un clúster de HDInsight.
En Visual Studio, vaya a Ver>Explorador de servidores.
En el Explorador de servidores, haga clic con el botón derecho en Azure, seleccione Conectar a la suscripción de Microsoft Azure y complete el proceso de inicio de sesión.
Expanda el clúster de HDInsight en el que desee implementar esta aplicación. Aparecerá una entrada con el texto (Cuenta de almacenamiento predeterminada) en la lista.
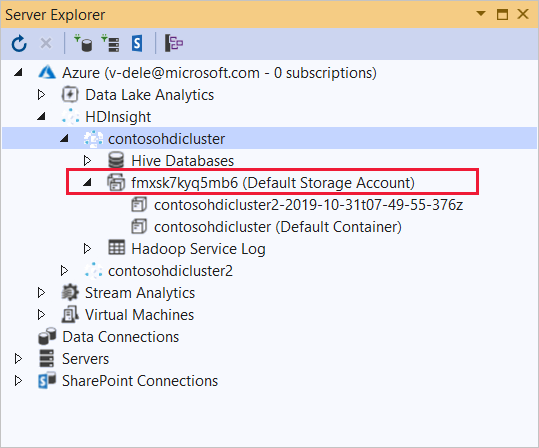
Si se puede expandir esta entrada, significa que está utilizando una cuenta de Azure Storage como almacenamiento predeterminado para el clúster. Para ver los archivos incluidos en el almacenamiento predeterminado del clúster, expanda la entrada y, a continuación, haga doble clic en (Contenedor predeterminado).
Si esta entrada no se puede expandir, quiere decir que está usando Azure Data Lake Storage como almacenamiento predeterminado para el clúster. Para ver los archivos incluidos en el almacenamiento predeterminado del clúster, haga doble clic en la entrada (Cuenta de almacenamiento predeterminada) .
Para cargar los archivos .exe, siga uno de estos métodos:
Si está usando una cuenta de Azure Storage, seleccione el icono Cargar blob.

En el cuadro de diálogo Cargar nuevo archivo, en Nombre de archivo, seleccione Examinar. En el cuadro de diálogo Cargar blob, vaya a la carpeta
bin\debugdel proyecto HiveCSharp y, a continuación, elija el archivo HiveCSharp.exe. Por último, seleccione Abrir y, a continuación, Aceptar para completar la carga.Si usa Azure Data Lake Storage, haga clic con el botón derecho en un área vacía de la lista de archivos y, después, seleccione Cargar. Por último, elija el archivo HiveCSharp.exe y seleccione Abrir.
Una vez que la carga del archivo HiveCSharp.exe haya finalizado, repita el proceso de carga con el archivo PigUDF.exe.
Ejecución de una consulta de Apache Hive
Ahora puede ejecutar una consulta de Hive que use su aplicación UDF de Hive.
En Visual Studio, vaya a Ver>Explorador de servidores.
Expanda Azure y, después, haga lo mismo con HDInsight.
Haga clic con el botón derecho en el clúster en el que ha implementado la aplicación HiveCSharp y, a continuación, elija Escribir una consulta de Hive.
Use el siguiente texto para la consulta de Hive:
-- Uncomment the following if you are using Azure Storage -- add file wasbs:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen1 -- add file adl:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen2 -- add file abfs:///HiveCSharp.exe; SELECT TRANSFORM (clientid, devicemake, devicemodel) USING 'HiveCSharp.exe' AS (clientid string, phoneLabel string, phoneHash string) FROM hivesampletable ORDER BY clientid LIMIT 50;Importante
Quite la marca de comentario de la instrucción
add fileque coincide con el tipo de almacenamiento predeterminado que se usa para su clúster.Esta consulta selecciona los campos
clientid,devicemakeydevicemodeldehivesampletabley, a continuación, los pasa a la aplicación HiveCSharp.exe. La consulta espera que la aplicación devuelva tres campos, que están almacenados comoclientid,phoneLabelyphoneHash. La consulta también espera que HiveCSharp.exe esté en la raíz del contenedor de almacenamiento predeterminado.Cambie el valor predeterminado de Interactivo a Lote y después seleccione Enviar para enviar el trabajo al clúster de HDInsight. Se abre la ventana Resumen del trabajo de Hive.
Seleccione Actualizar para actualizar el resumen hasta que el valor de Estado del trabajo cambie a Completado. Para ver la salida del trabajo, seleccione Salida de trabajo.
Ejecución de un trabajo de Apache Pig
También puede ejecutar un trabajo de Pig que use su aplicación UDF de Pig.
Use SSH para conectarse a su clúster de HDInsight. (por ejemplo, ejecute el comando
ssh sshuser@<clustername>-ssh.azurehdinsight.net). Para obtener más información, consulte Uso de SSH con HDInsight.Utilice el siguiente comando para iniciar la línea de comandos de Pig:
pigSe muestra un símbolo del sistema
grunt>.Escriba lo siguiente para ejecutar un trabajo de Pig que usa la aplicación de .NET Framework:
DEFINE streamer `PigUDF.exe` CACHE('/PigUDF.exe'); LOGS = LOAD '/example/data/sample.log' as (LINE:chararray); LOG = FILTER LOGS by LINE is not null; DETAILS = STREAM LOG through streamer as (col1, col2, col3, col4, col5); DUMP DETAILS;La instrucción
DEFINEcrea un alias destreamerpara la aplicación de PigUDF.exe yCACHElo carga desde el almacenamiento predeterminado del clúster. Más adelante,streamerse usa con el operadorSTREAMpara procesar las líneas individuales incluidas enLOGy devolver los datos como una serie de columnas.Nota
El nombre de la aplicación que se usa para el streaming debe ir entre caracteres
`(acento grave) cuando se usa como alias, y entre caracteres'(comilla sencilla) cuando se utiliza conSHIP.Después de escribir la última línea, debe iniciarse el trabajo. Devuelve un resultado similar al texto siguiente:
(2019-07-15 16:43:25 SampleClass5 [WARN] problem finding id 1358451042 - java.lang.Exception) (2019-07-15 16:43:25 SampleClass5 [DEBUG] detail for id 1976092771) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1317358561) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1737534798) (2019-07-15 16:43:25 SampleClass7 [DEBUG] detail for id 1475865947)Use
exitpara salir de Pig.
Pasos siguientes
En este documento, ha aprendido a utilizar una aplicación de .NET Framework desde Hive y Pig en HDInsight. Si quiere obtener información sobre cómo usar Python con Hive y Pig, vea Uso de Python con Apache Hive y Apache Pig en HDInsight.
Para conocer otras formas de usar Pig y Hive y para obtener información acerca del uso de MapReduce, consulte los siguientes artículos: