¿Qué es Trino? (versión preliminar)
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre Comunidad de Azure HDInsight.
Trino (anteriormente PrestoSQL) es un motor de consultas SQL distribuido de código abierto para el análisis federado e interactivo de orígenes de datos heterogéneos. Puede consultar datos a gran escala (de gigabytes a petabytes) de varios orígenes para permitir el análisis en toda la empresa.
Trino se usa para una amplia gama de casos de uso analíticos y es una excelente opción para consultas interactivas y consultas ad hoc.
Algunas de las características clave que ofrece Trino:
- Un sistema multiinquilino adaptable capaz de ejecutar simultáneamente cientos de consultas de memoria, E/S y CPU intensivas y escalar a miles de nodos de trabajo, a la vez que usa recursos de clúster de forma eficaz.
- Diseño extensible y federado para reducir la complejidad de la integración de varios sistemas.
- Alto rendimiento, con varias características y optimizaciones clave relacionadas.
- Totalmente compatible con el ecosistema de Hadoop.
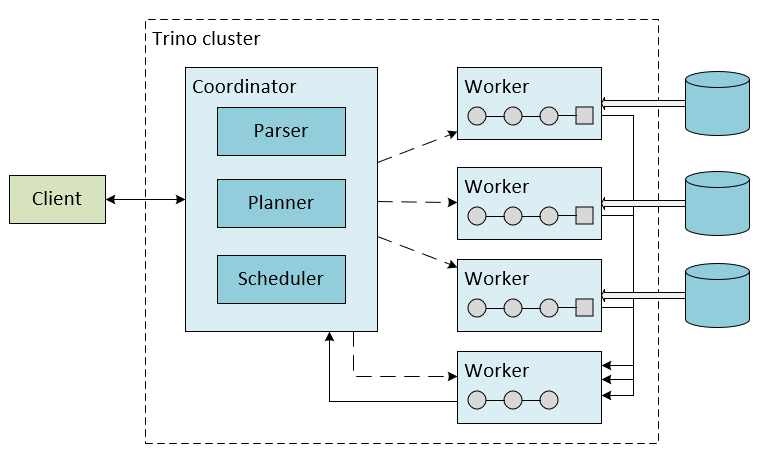
Hay dos tipos de servidores de Trino: coordinadores y trabajadores.
Coordinador
El coordinador de Trino es el servidor responsable de analizar instrucciones, planear consultas y administrar nodos de trabajo de Trino. Es el "cerebro" de una instalación de Trino y también es el nodo al que se conecta un cliente para enviar instrucciones para su ejecución. El coordinador realiza un seguimiento de la actividad en cada trabajo y coordina la ejecución de una consulta. El coordinador crea un modelo lógico de una consulta, que implica una serie de fases, que se traduce en una serie de tareas conectadas que se ejecutan en un clúster de trabajos de Trino.
Trabajador
Un trabajo de Trino es un servidor en una instalación de Trino, que es responsable de ejecutar tareas y procesar datos. Los nodos de trabajo capturan datos de conectores e intercambian datos intermedios entre sí. El coordinador es responsable de capturar los resultados de los trabajos y devolver los resultados finales al cliente.