Envío y administración de trabajos en un clúster de Apache Spark™ en HDInsight en AKS
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones en la Comunidad de Azure HDInsight.
Una vez creado el clúster, el usuario puede usar varias interfaces para enviar y administrar trabajos mediante
- uso de Jupyter
- uso de Zeppelin
- uso de ssh (spark-submit)
Uso de Jupyter
Requisitos previos
Un clúster de Apache Spark™ en HDInsight en AKS. Para obtener más información, consulte Creación de un clúster de Apache Spark.
Jupyter Notebook es un entorno de cuaderno interactivo que admite varios lenguajes de programación.
Creación de un cuaderno de Jupyter Notebook
Vaya a la página del clúster de Apache Spark™ y abra la pestaña Información general. Hacer clic en Jupyter, le pide que autentique y abra la página web de Jupyter.

En la página web de Jupyter, seleccione Nuevo > PySpark para crear un cuaderno.
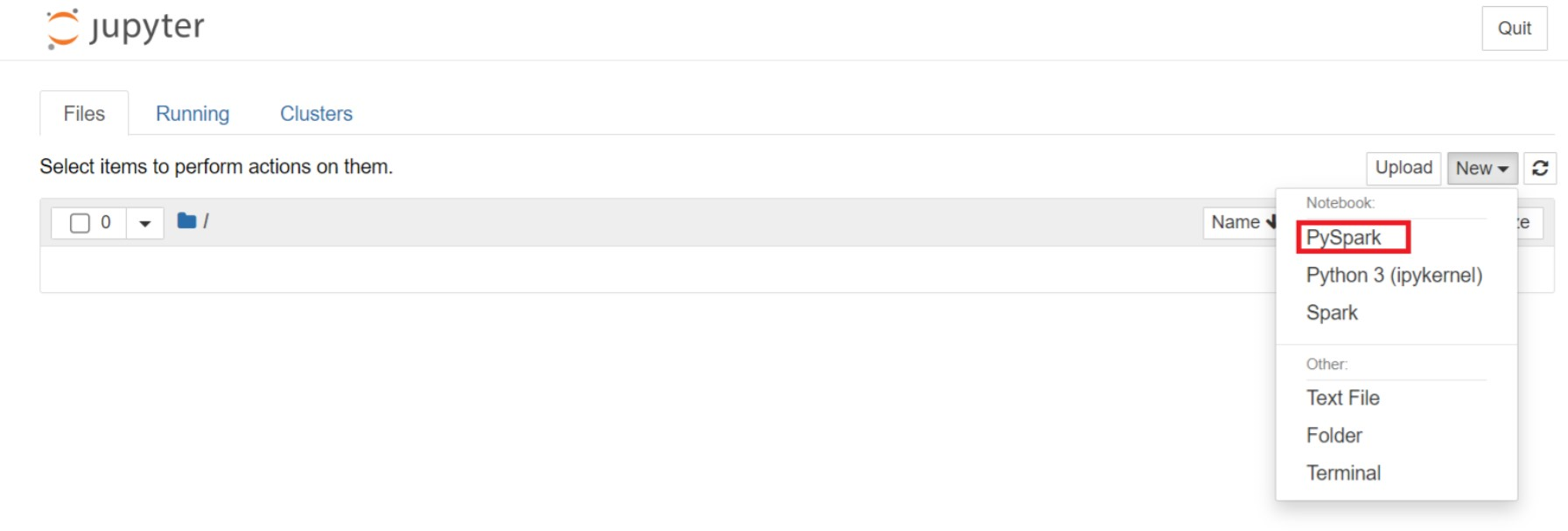
Nuevo cuaderno creado y abierto con el nombre
Untitled(Untitled.ipynb).Nota:
Con pySpark o el kernel de Python 3 para crear un cuaderno, la sesión de Spark se crea automáticamente al ejecutar la primera celda de código. No es necesario crear la sesión explícitamente.
Pegue el código siguiente en una celda vacía del cuaderno de Jupyter Notebook y presione MAYÚS + ENTRAR para ejecutarlo. Consulte aquí para obtener más controles en Jupyter.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Trazar un gráfico con Salario y edad como ejes X e Y
En el mismo cuaderno, pegue el código siguiente en una celda vacía del cuaderno de Jupyter Notebook y presione MAYÚS + ENTRAR para ejecutar el código.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()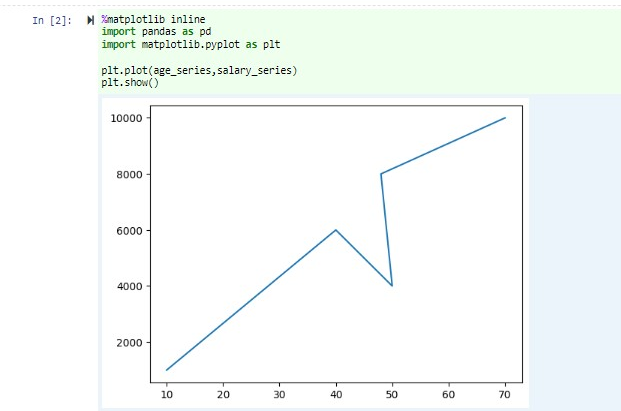




Guardar el cuaderno
En la barra de menús del cuaderno, vaya a Archivo > Guardar y punto de control.
Apague el cuaderno para liberar los recursos del clúster: en la barra de menús del cuaderno, vaya a Archivo > Cerrar y detener. También puede ejecutar cualquiera de los cuadernos en la carpeta de ejemplos.


Uso de cuadernos de Apache Zeppelin
Los clústeres de Apache Spark de HDInsight en AKS incluyen cuadernos de Apache Zeppelin. Use los cuadernos para ejecutar los trabajos de Apache Spark. En este artículo, aprenderá a usar el cuaderno de Zeppelin en un clúster de HDInsight en AKS.
Requisitos previos
Un clúster de Apache Spark en HDInsight en AKS. Para obtener instrucciones, consulte Creación de un clúster de Apache Spark.
Inicio de un cuaderno de Apache Zeppelin
Vaya a la página Información general del clúster de Apache Spark y seleccione Cuaderno de Zeppelin en Paneles de clúster. Se le pide que se autentique y abra la página de Zeppelin.
Creación de un cuaderno. En el panel de encabezado, vaya a Notebook > Crear nueva nota. Por otro lado, asegúrese de que en el encabezado del cuaderno aparece el estado conectado. Denota un punto verde en la esquina superior derecha.
Ejecute el código siguiente en el Cuaderno de Zeppelin:
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Seleccione el botón Reproducir para que el párrafo ejecute el fragmento de código. El estado en la esquina derecha del párrafo debería avanzar de READY (Listo), PENDING (Pendiente) o RUNNING (En ejecución) a FINISHED (Finalizado). El resultado se muestra en la parte inferior del mismo párrafo. La captura de pantalla es similar a esta imagen:
Salida:





Uso de enviar trabajos de Spark
Crear un archivo con el siguiente comando `#vim samplefile.py'
Este comando abre el archivo vim
Pegue el código siguiente en el archivo vim
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Guardar el archivo con el método siguiente.
- Presione el botón Escape
- Escriba el comando
:wq
Ejecute el siguiente comando para ejecutar el trabajo.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Supervisión de consultas en un clúster de Apache Spark en HDInsight en AKS
Interfaz de usuario del historial de Spark
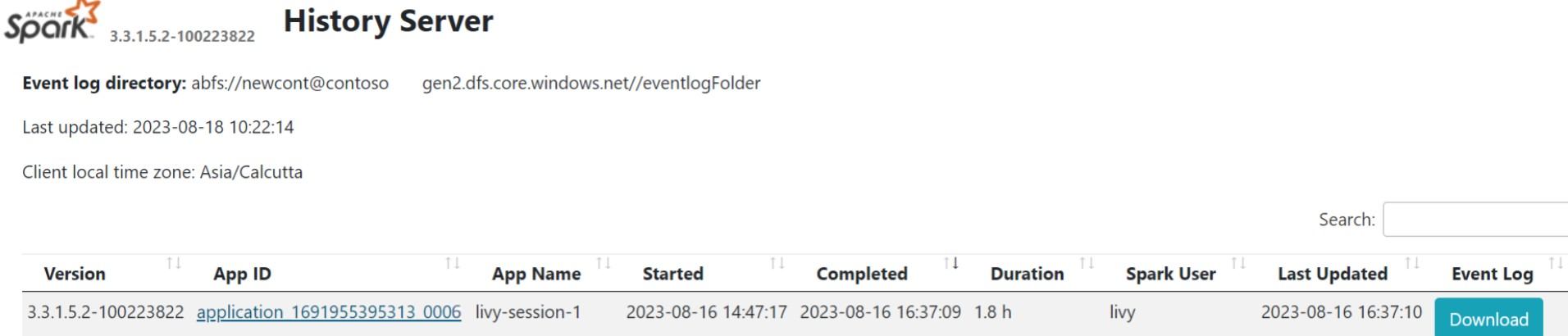
Haga clic en la interfaz de usuario del servidor de historial de Spark en la pestaña información general.

Seleccione la ejecución reciente de la interfaz de usuario con el mismo identificador de aplicación.
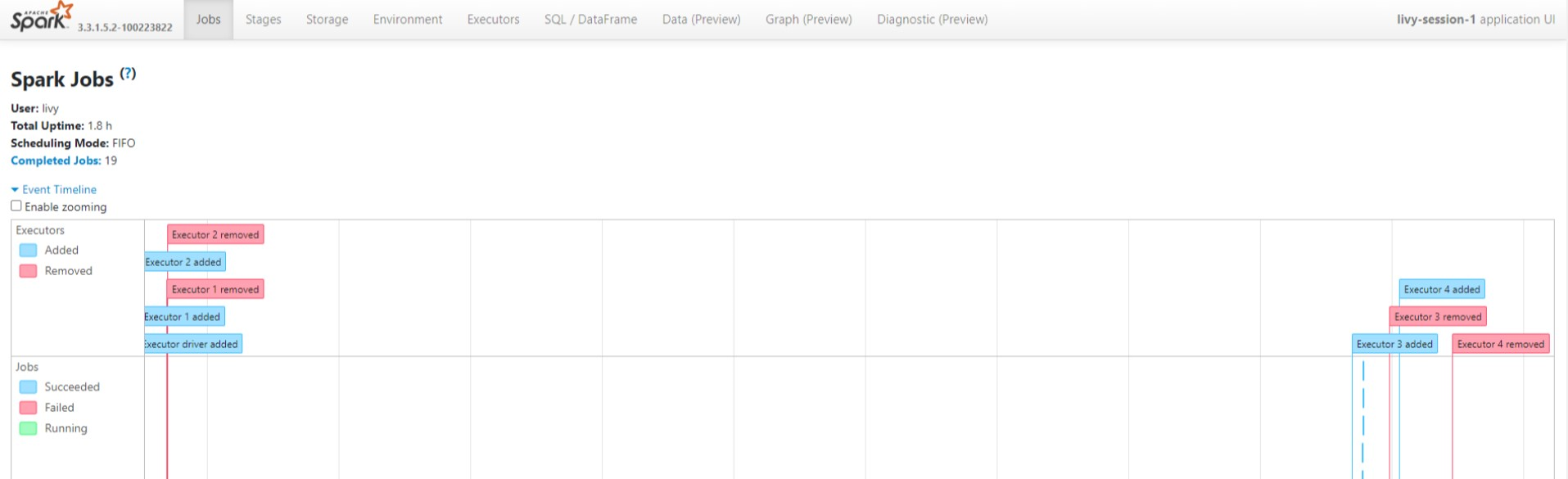
Vea los ciclos del grafo acíclico dirigido y las fases del trabajo en la interfaz de usuario del servidor de historial de Spark.



Interfaz de usuario de sesión de Livy
Para abrir la interfaz de usuario de sesión de Livy, escriba el siguiente comando en el explorador
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui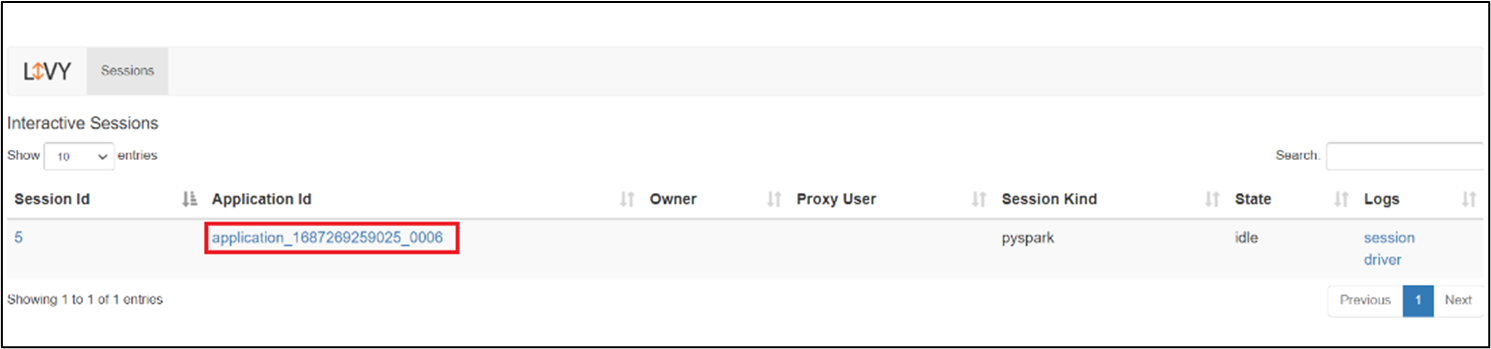
Para ver los registros de controladores, haga clic en la opción controlador en registros.

Interfaz de usuario de Yarn
En la pestaña Información general, haga clic en Yarn y abra la interfaz de usuario de Yarn.
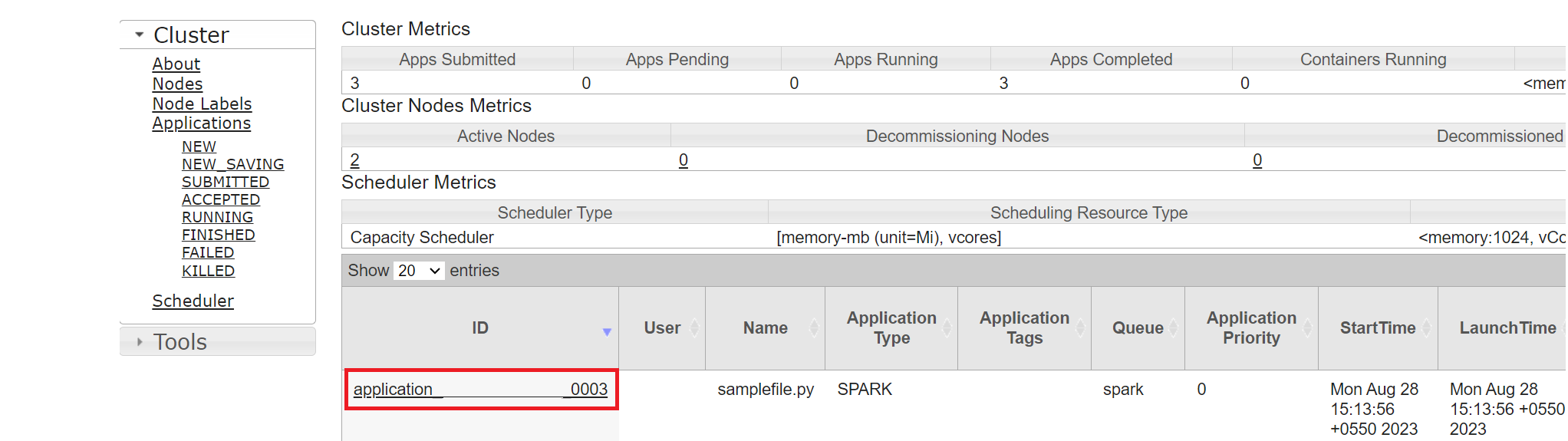
Puede realizar un seguimiento del trabajo que ejecutó recientemente con el mismo identificador de aplicación.
Haga clic en el identificador de aplicación de Yarn para ver los registros detallados del trabajo.


Referencia
- Apache, Apache Spark, Spark y los nombres de proyecto de código abierto asociados son marcas comerciales de Apache Software Foundation (ASF).