Uso de Delta Lake en Azure HDInsight en AKS con clústeres de Apache Spark™ (versión preliminar)
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre Comunidad de Azure HDInsight.
Azure HDInsight en AKS es un servicio administrado basado en la nube para el análisis de macrodatos que ayuda a las organizaciones a procesar grandes cantidades de datos. En este tutorial se muestra cómo usar Delta Lake en Azure HDInsight en AKS con clústeres de Apache Spark™.
Requisito previo
Creación de un clúster de Apache Spark™ en Azure HDInsight en AKS
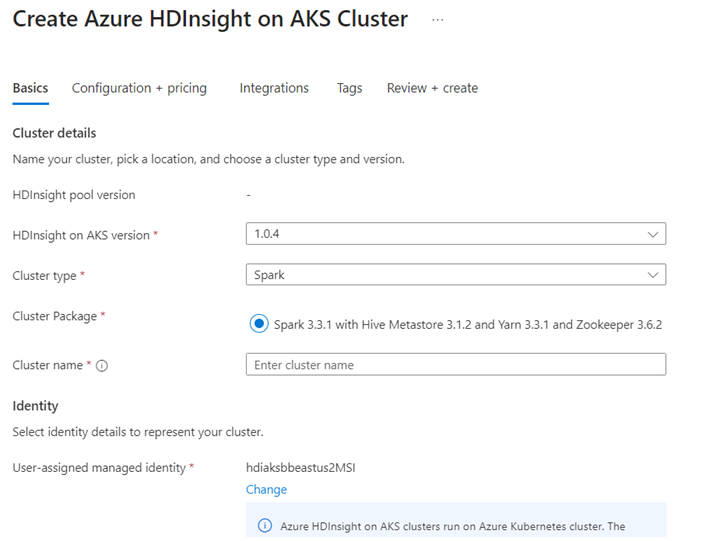
Ejecute el escenario de Delta Lake en Jupyter Notebook. Cree un cuaderno de Jupyter Notebook y seleccione "Spark" al crear un cuaderno, ya que el siguiente ejemplo está en Scala.
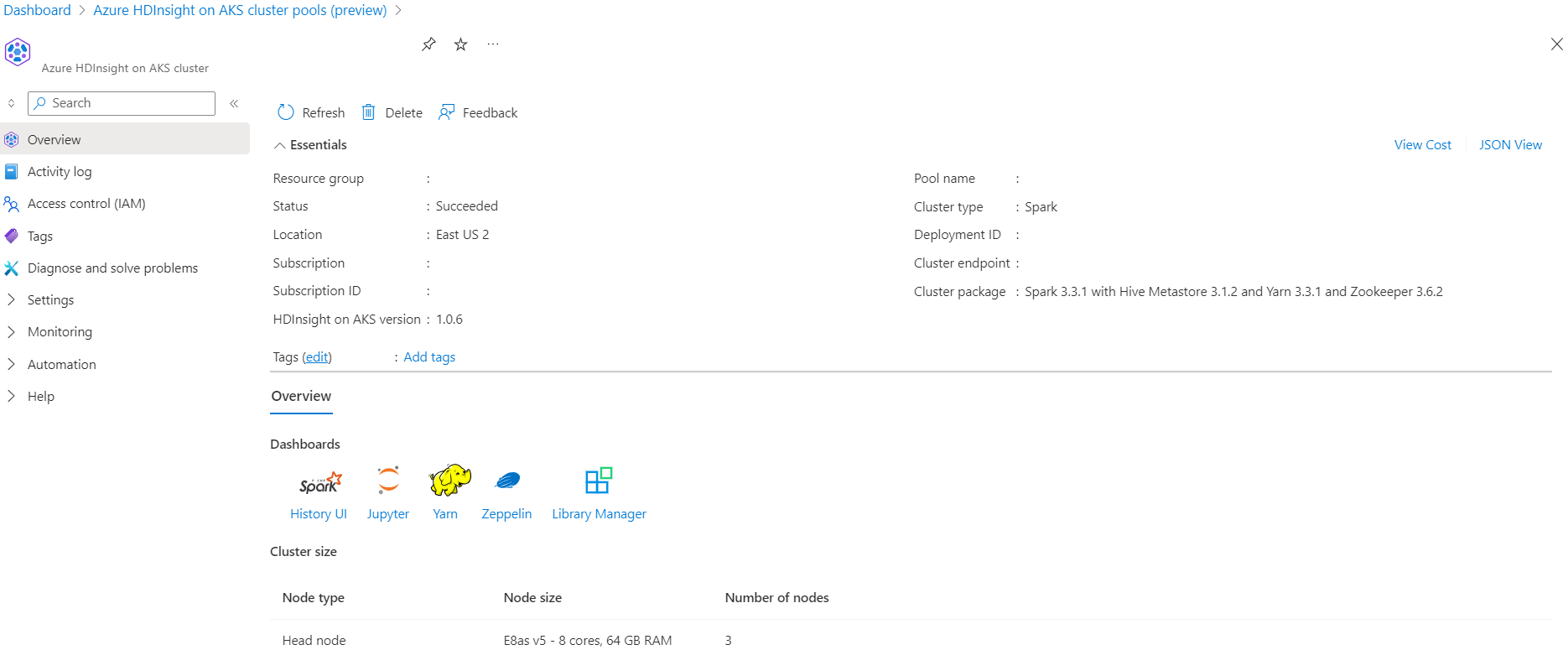


Escenario
- Lectura del formato de datos Parquet de NYC Taxi: la lista de direcciones URL de archivos Parquet la proporciona la NYC Taxi & Limousine Commission.
- Para cada dirección URL (archivo) realice alguna transformación y almacén en formato Delta.
- Calcule la distancia media, el costo promedio por milla y el costo medio de la tabla de Delta mediante la carga incremental.
- Almacene el valor calculado del paso 3 en formato Delta en la carpeta de salida de KPI.
- Cree una tabla de Delta en la carpeta de salida de formato Delta (actualización automática).
- La carpeta de salida de KPI tiene varias versiones de la distancia media y el costo medio por milla de un viaje.
Proporcionar configuraciones necesarias para Delta Lake
Matriz de compatibilidad de Delta Lake con Apache Spark: Delta Lake, cambie la versión de Delta Lake en función de la versión de Apache Spark.
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

Enumeración del archivo de datos
Nota:
Estas direcciones URL de archivo proceden de la NYC Taxi & Limousine Commission.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

Creación de un directorio de salida
La ubicación en la que desea crear la salida del formato Delta, cambie la variable transformDeltaOutputPath y avgDeltaOutputKPIPath si es necesario,
avgDeltaOutputKPIPath: para almacenar el KPI medio en formato DeltatransformDeltaOutputPath: almacenar la salida transformada en formato Delta
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Crear datos de formato Delta a partir del formato Parquet
Los datos de entrada proceden de
listOfDataFile, mientras que los datos descargados proceden de https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.pagePara mostrar el viaje en el tiempo y la versión, cargue los datos individualmente
Realice la transformación y calcule los siguientes KPI empresariales en la carga incremental:
- La distancia media
- El costo promedio por milla
- El costo promedio
Guarde los datos transformados y de KPI en formato Delta
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Lectura del formato Delta mediante la tabla de Delta
- lectura de datos transformados
- lectura de datos de KPI
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
Esquema de impresión
- Imprima el esquema de tabla de Delta para datos de KPI transformados y de promedio.
// tranform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema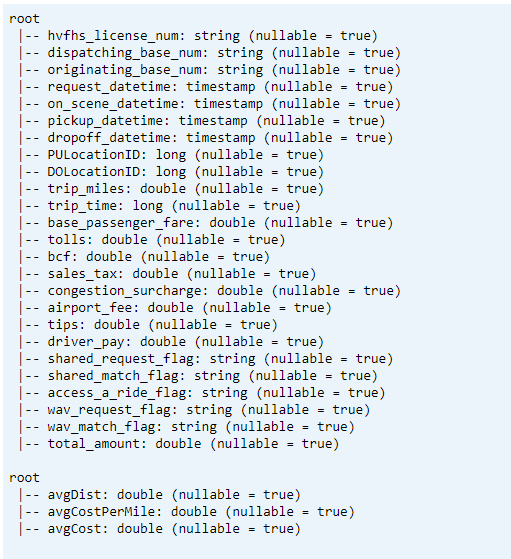
Muestre el último KPI calculado de la tabla de datos
dtAvgKpi.toDF.show(false)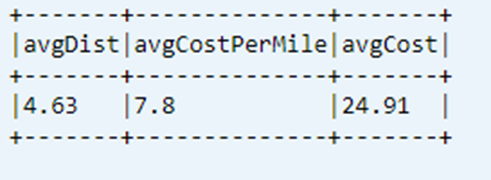


Muestre el historial de KPI calculado
En este paso se muestra el historial de la tabla de transacciones de KPI de _delta_log
dtAvgKpi.history().show(false)

Muestre los datos de KPI después de cada carga de datos
- Con el viaje en el tiempo, puede ver los cambios de KPI después de cada carga
- Puede almacenar todos los cambios de versión en formato CSV en
avgMoMKPIChangePath, para que Power BI pueda leerlos
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

Referencia
- Apache, Apache Spark, Spark y los nombres de proyecto de código abierto asociados son marcas comerciales de Apache Software Foundation (ASF).