Cómo utilizar Azure Pipelines con Apache Flink® en HDInsight en AKS
Importante
Azure HDInsight en AKS se retiró el 31 de enero de 2025. Obtenga más información con este anuncio.
Debe migrar las cargas de trabajo a microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo.
Importante
Esta característica está actualmente en versión preliminar. Los Términos de uso complementarios para las versiones preliminares de Microsoft Azure incluyen más términos legales que se aplican a las características de Azure que se encuentran en versión beta, en versión preliminar o, de lo contrario, aún no se han publicado en disponibilidad general. Para obtener información sobre esta versión preliminar específica, consulte información de la versión preliminar de Azure HDInsight en AKS. Para preguntas o sugerencias de características, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre Comunidad de Azure HDInsight.
En este artículo, aprenderá a usar Azure Pipelines con HDInsight en AKS para enviar trabajos de Flink con la API REST del clúster. Le guiaremos a través del proceso mediante una canalización YAML de ejemplo y un script de PowerShell, ambos que simplifican la automatización de las interacciones de la API REST.
Prerrequisitos
Suscripción de Azure. Si no tiene una suscripción de Azure, cree una cuenta gratuita.
Una cuenta de GitHub donde puede crear un repositorio. Crear uno gratis.
Cree el directorio
.pipeline, copie flink-azure-pipelines.yml y flink-job-azure-pipeline.ps1Organización de Azure DevOps. Cree uno gratis. Si el equipo ya tiene uno, asegúrese de que es administrador del proyecto de Azure DevOps que desea usar.
Capacidad de ejecutar canalizaciones en agentes hospedados por Microsoft. Para usar agentes hospedados por Microsoft, la organización de Azure DevOps debe tener acceso a trabajos paralelos hospedados por Microsoft. Puede comprar un trabajo paralelo o solicitar una concesión gratuita.
Un clúster de Flink. Si no tiene uno, Cree un clúster de Flink en HDInsight en AKS.
Cree un directorio en la cuenta de almacenamiento del clúster para copiar el archivo JAR de la tarea. Más adelante, deberás configurar el directorio en la canalización YAML para especificar la ubicación del archivo jar del trabajo (<JOB_JAR_STORAGE_PATH>).
Pasos para configurar la canalización
Creación de una entidad de servicio para Azure Pipelines
Crear entidad de servicio de Microsoft Entra para acceder a Azure: conceder permiso para acceder a HDInsight en el clúster de AKS con el rol Colaborador, anote appId, password y tenant de la respuesta.
az ad sp create-for-rbac -n <service_principal_name> --role Contributor --scopes <Flink Cluster Resource ID>`
Ejemplo:
az ad sp create-for-rbac -n azure-flink-pipeline --role Contributor --scopes /subscriptions/abdc-1234-abcd-1234-abcd-1234/resourceGroups/myResourceGroupName/providers/Microsoft.HDInsight/clusterpools/hiloclusterpool/clusters/flinkcluster`
Referencia
Nota
Los nombres de proyecto de código abierto asociados de Apache, Apache Flink, Apache Flink y son marcas comerciales de la Apache Software Foundation (ASF).
Crear una bóveda de claves
Cree una nueva instancia de Azure Key Vault, puedes seguir este tutorial para crear una nueva instancia de Azure Key Vault.
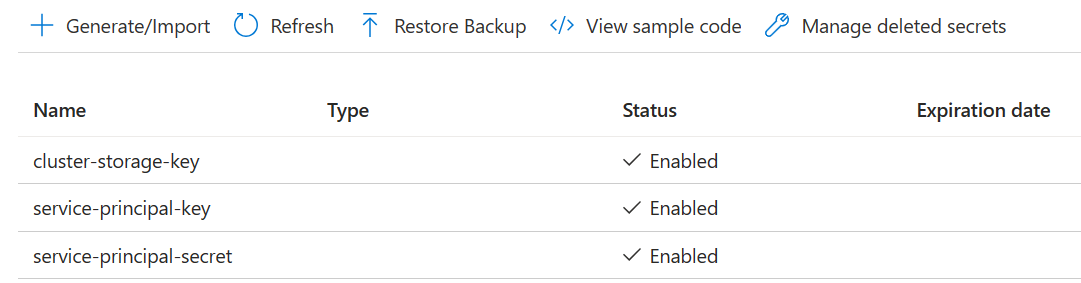
Crear tres secretos
clave de almacenamiento del clúster para la clave de almacenamiento.
clave de principal de servicio para clientId o appId del cliente o aplicación.
clave del servicio principal para el secreto principal.
Conceda permiso a la entidad de servicio para acceder a Azure Key Vault con el rol "Oficial de secretos de Key Vault".

Configuración de canalización
Vaya al proyecto y haga clic en Configuración del proyecto.
Desplácese hacia abajo y seleccione Conexiones de servicio y, a continuación, Nueva conexión de servicio.
Seleccione Azure Resource Manager.
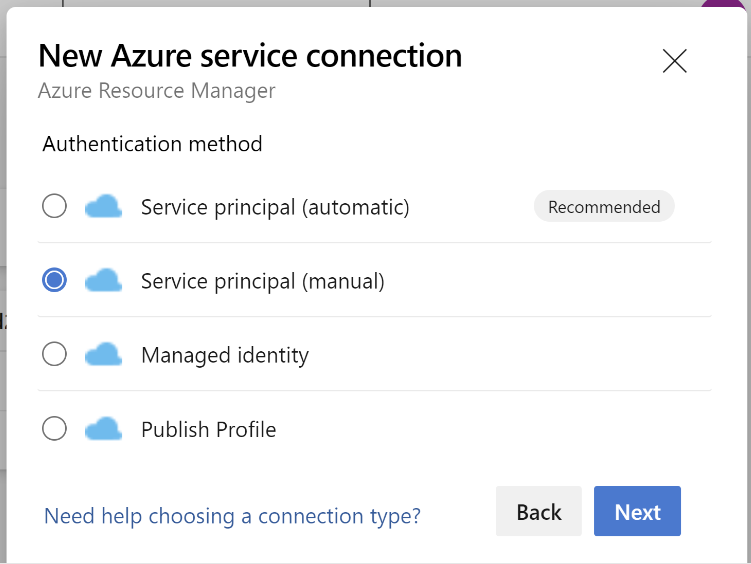
En el método de autenticación, seleccione Entidad de servicio (manual).

Edite las propiedades de conexión del servicio. Seleccione el principal de servicio que creó recientemente.
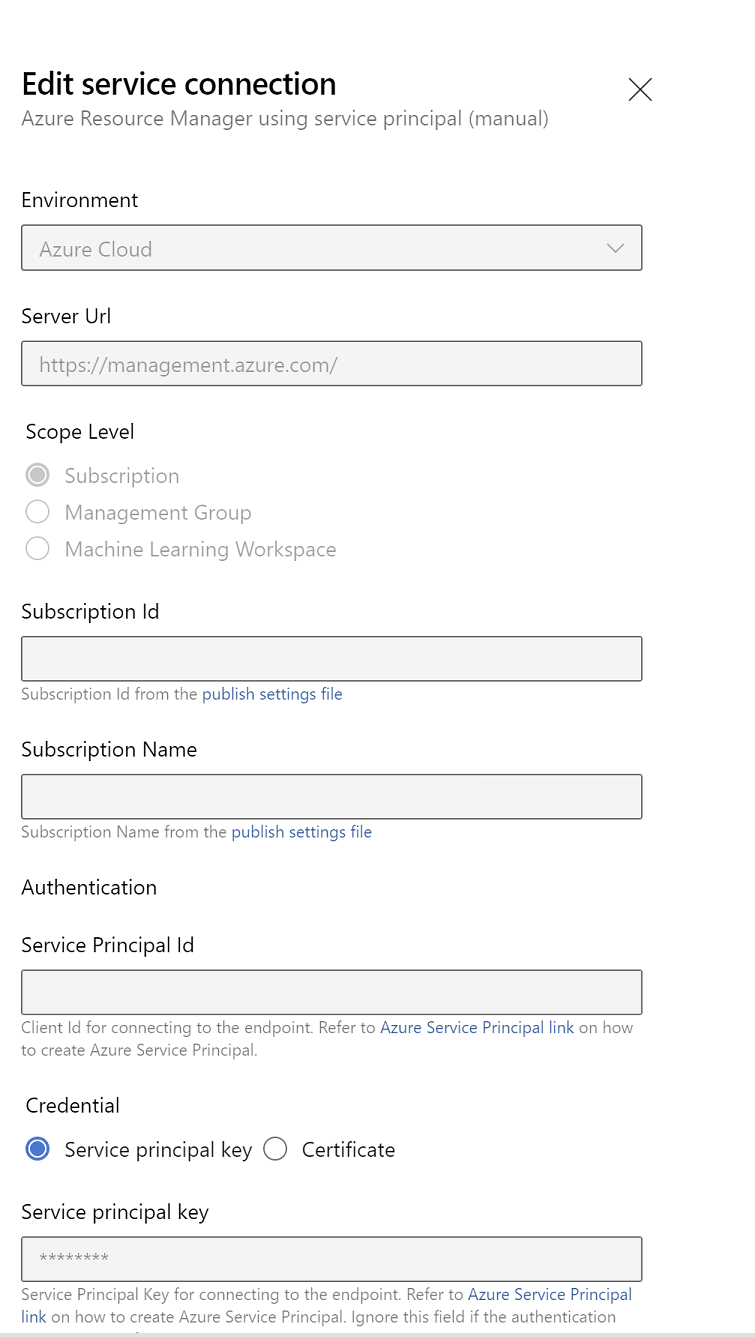
Haga clic en Comprobar para comprobar si la conexión se configuró correctamente. Si se produce el siguiente error:

A continuación, debe asignar el rol Lector a la suscripción.
Después de eso, la verificación debería ser exitosa.
Guarde la conexión de servicio.

Vaya a canalizaciones y haga clic en Nueva canalización.
Seleccione GitHub como ubicación del código.
Seleccione el repositorio. Consulte cómo crear un repositorio en GitHub. imagen select-github-repo.
Seleccione el repositorio. Para obtener más información, consulte Creación de un repositorio en GitHub.
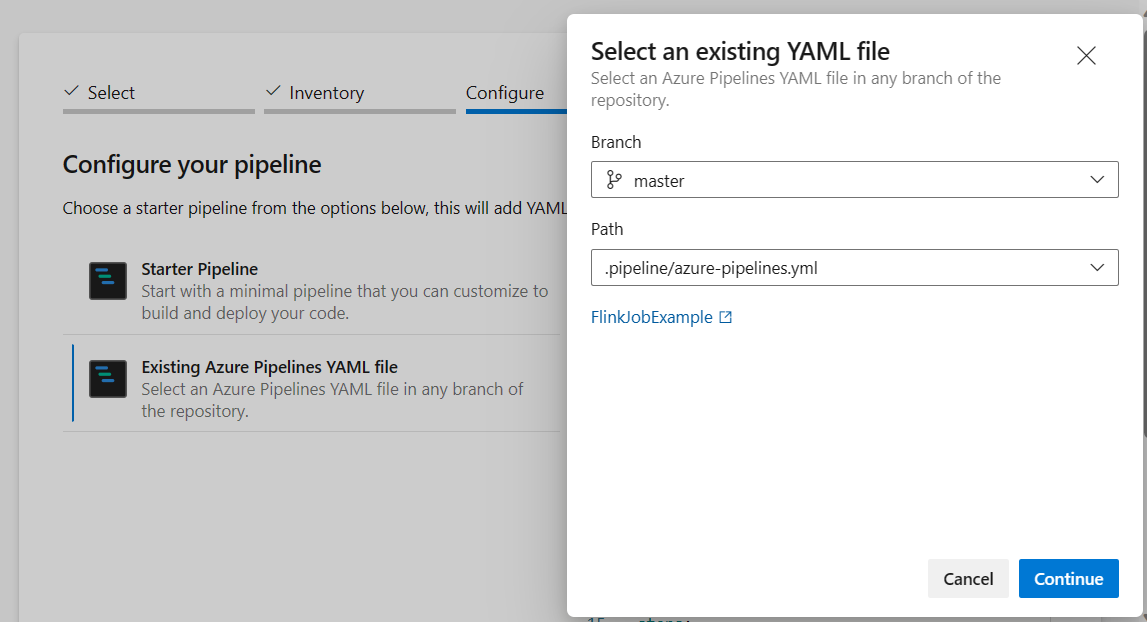
En la opción de configurar su canalización, puede elegir archivo YAML de Azure Pipelines existente. Seleccione el script de rama y canalización que copió anteriormente. (.pipeline/flink-azure-pipelines.yml)
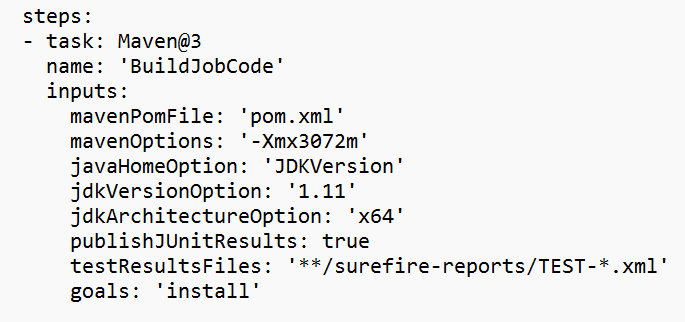
Reemplace el valor en la sección variable.

Corrija la sección de compilación de código según sus necesidades y configure <JOB_JAR_LOCAL_PATH> en la sección variable para la ruta de acceso local del archivo jar del trabajo.
Agregue la variable de canalización "action" y configure el valor "RUN".
Puede cambiar los valores de la variable antes de ejecutar la canalización.
NUEVO: este valor es predeterminado. Inicia un nuevo trabajo y, si el trabajo ya se está ejecutando, actualiza el trabajo en ejecución con el archivo jar más reciente.
SAVEPOINT: Este valor toma el punto de guardado para la ejecución del trabajo.
DELETE: cancele o elimine el trabajo en ejecución.
Guarde y ejecute la canalización. Puede ver la tarea en ejecución en el portal en la sección de trabajos de Flink.








Nota
Este es un ejemplo para enviar el trabajo mediante la canalización. Puede seguir la documentación de la API REST de Flink para escribir su propio código para enviar el trabajo.