Administración de configuración de Apache Flink® en HDInsight en AKS
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud sobre AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre la comunidad de Azure HDInsight.
HDInsight en AKS proporciona un conjunto de configuraciones predeterminadas de Apache Flink para la mayoría de las propiedades y algunas basadas en perfiles de aplicación comunes. Sin embargo, en caso de que necesite modificar las propiedades de configuración de Flink para mejorar el rendimiento de determinadas aplicaciones con el uso de estados, el paralelismo o la configuración de la memoria, puede cambiar la configuración de los trabajos de Flink mediante la sección Trabajos de Flink en HDInsight en el clúster AKS.
Vaya a Configuración > Trabajos de Flink > Haga clic en Actualizar.
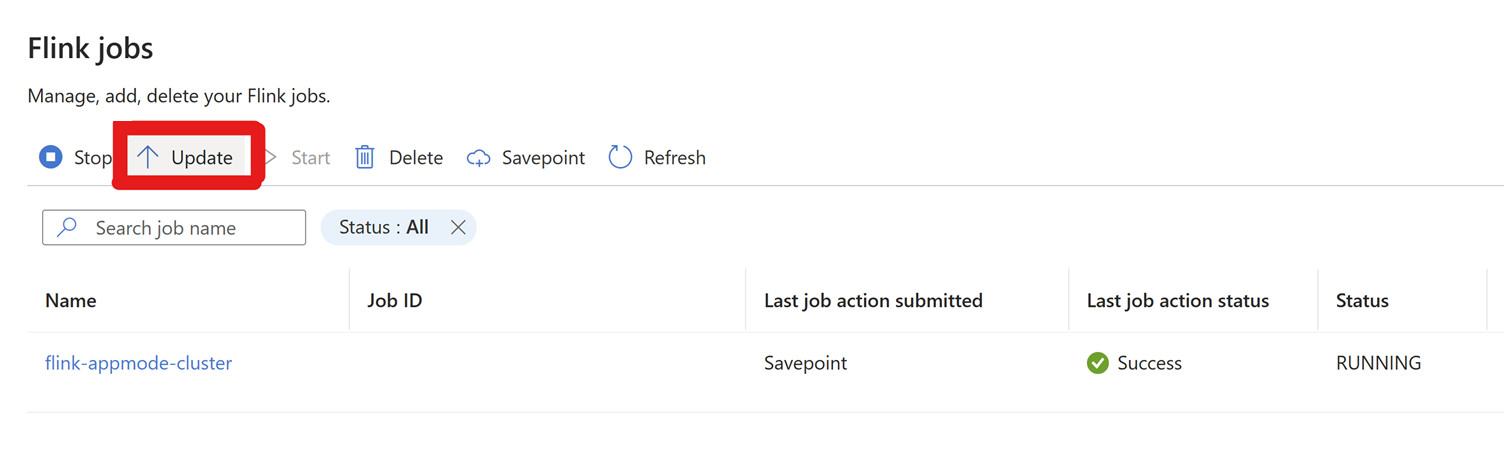
Haga clic en + Agregar una fila para editar la configuración.

Aquí se cambia el intervalo de punto de control a nivel de clúster.
Para actualizar los cambios, haga clic en Aceptar y, luego, en Guardar.
Una vez guardadas, las nuevas configuraciones se actualizan en unos minutos (unos 5 minutos).
Configuraciones que se pueden actualizar mediante las opciones de Administración de configuración.
processMemory size:La configuración predeterminada del tamaño de memoria del proceso del administrador de trabajos y el administrador de tareas sería la memoria configurada por el usuario durante la creación del clúster.
Este tamaño se puede configurar mediante la propiedad de configuración siguiente. Para cambiar la memoria de proceso del administrador de tareas, use esta configuración.
taskmanager.memory.process.size : <value>Ejemplo:
taskmanager.memory.process.size : 2000mbPara el administrador de trabajos
jobmanager.memory.process.size : <value>Nota:
La memoria de proceso configurable máxima es igual a la memoria configurada para
jobmanager/taskmanager.


Intervalo de punto de control
El intervalo de punto de control determina la frecuencia con la que Flink desencadena un punto de control. Se define en milisegundos y se puede establecer mediante la siguiente propiedad de configuración
execution.checkpoint.interval: <value>
El valor predeterminado es de 60 000 milisegundos (1 minuto), pero este valor se puede cambiar según sea necesario.
Back-end de estado
El back-end de estado determina cómo Flink administra y conserva el estado de la aplicación. Afecta a cómo se almacenan los puntos de control. Puede configurar el back-end de estado mediante la siguiente propiedad:
state.backend: <value>
De manera predeterminada, los clústeres de Apache Flink en HDInsight en AKS usan Rocks DB.
Ruta de acceso de almacenamiento de puntos de control
De forma predeterminada, se permiten puntos de control persistentes almacenando los puntos de control en almacenamiento abfs según lo configurado por el usuario. Incluso si se produce un error en el trabajo, dado que los puntos de control se conservan, se puede iniciar fácilmente con el punto de control más reciente.
state.checkpoints.dir: <path> Reemplace <path> por la ruta de acceso deseada donde se almacenan los puntos de control.
De forma predeterminada, se almacenan en la cuenta de almacenamiento (ABFS) configurada por el usuario. Este valor se puede cambiar por cualquier ruta de acceso deseada siempre que los pods de Flink puedan acceder a ella.
Número máximo de llamadas simultáneas
Puede limitar el número máximo de puntos de control simultáneos estableciendo la siguiente propiedad: checkpoint.max-concurrent-checkpoints: <value>.
Reemplace <value> por el número máximo deseado de puntos de control simultáneos. Por ejemplo, 1 para permitir solo un punto de control a la vez.
Número máximo de puntos de control retenidos
Puede limitar el número máximo de puntos de control que se van a conservar estableciendo la siguiente propiedad: state.checkpoints.num-retained: <value> Reemplace <value> por el número máximo deseado. De forma predeterminada, se conservan cinco puntos de control como máximo.
Ruta de acceso de almacenamiento de puntos de retorno
De forma predeterminada, se permiten puntos de retorno persistentes si se almacenan en almacenamiento abfs (según lo haya configurado el usuario). Si el usuario quiere detener y más adelante iniciar el trabajo con un punto de retorno determinado, puede configurar esta ubicación.
state.checkpoints.dir: <path> Reemplace <path> por la ruta de acceso deseada donde están almacenados los puntos de retorno.
De forma predeterminada, se almacenan en la cuenta de almacenamiento configurada por el usuario. (Admitimos ABFS). Este valor se puede cambiar por cualquier ruta de acceso deseada siempre que los pods de Flink puedan acceder a ella.
Alta disponibilidad del administrador de trabajos
En HDInsight en AKS, Flink usa Kubernetes como back-end. Incluso si el administrador de trabajos produce un error entre medias debido a cualquier problema conocido o desconocido, el pod se reinicia en unos segundos. Por lo tanto, incluso si el trabajo se reinicia debido a este problema, se recupera de nuevo del punto de control más reciente.
Preguntas más frecuentes
¿Por qué se produce un error en el trabajo entre sí? Incluso si los trabajos fallan abruptamente, si los puntos de control se suceden continuamente, entonces el trabajo se reinicia por defecto desde el último punto de control.
¿Se debe cambiar la estrategia de trabajo entre medias? Hay casos de uso en los que el trabajo debe modificarse mientras está en producción debido a algún error de nivel de trabajo. Durante ese tiempo, el usuario puede detener el trabajo, que tomaría automáticamente un punto de retorno y lo guardaría en la ubicación del punto de retorno.
Haga clic en
savepointy espere a quesavepointse complete.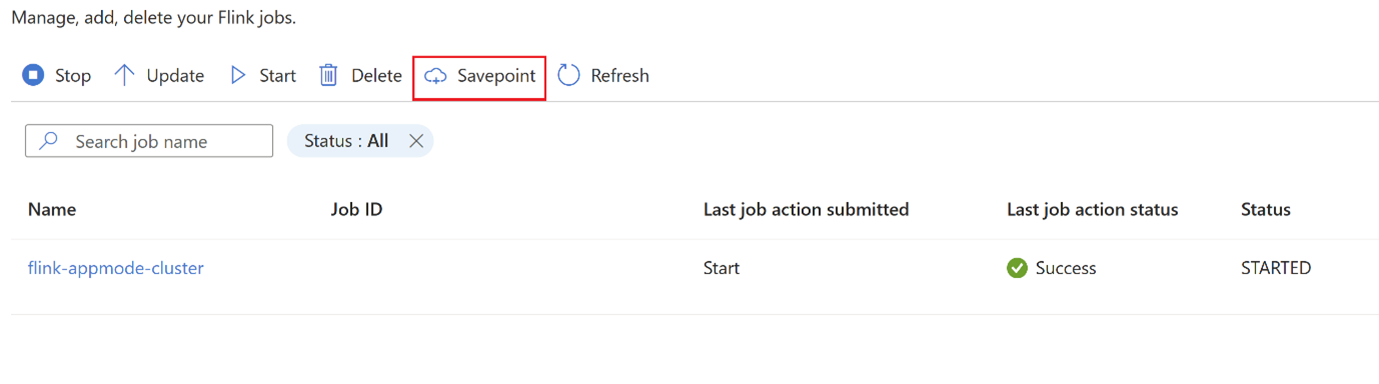
Después de finalizar el punto de guardado, haga clic en iniciar y aparecerá la pestaña Iniciar trabajo. Seleccione el nombre del punto de retorno en la lista desplegable. Edite las configuraciones si es necesario. Después, haga clic en Aceptar.
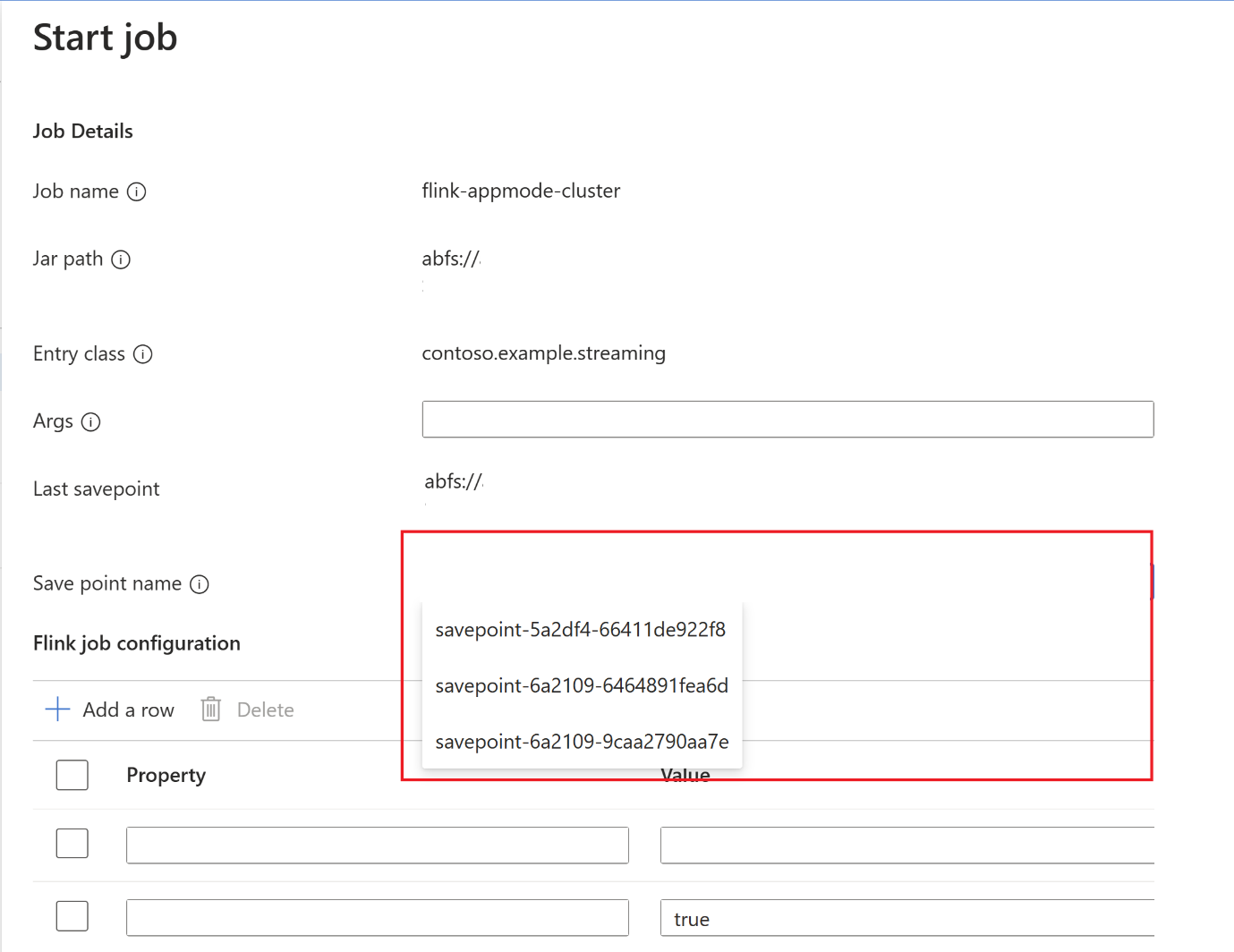


Dado que el punto de retorno se proporciona en el trabajo, Flink sabe desde dónde empezar a procesar los datos.
Referencia
- Configuraciones de Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink y los nombres de proyecto de código abierto asociados son marcas comerciales de laApache Software Foundation(ASF).