Clúster de modo de aplicación de Apache Flink en HDInsight on AKS
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones en Comunidad de Azure HDInsight.
HDInsight on AKS ahora ofrece un clúster de modo de aplicación de Flink. Este clúster le permite administrar el ciclo de vida de modo de aplicación de Flink de clúster mediante Azure Portal con una interfaz fácil de usar y las API de REST de administración de recursos de Azure. Los clústeres de modo de aplicación están diseñados para admitir trabajos grandes y de larga duración con recursos dedicados, y gestionar tareas de procesamiento de datos que consuman muchos recursos o sean extensas.
Este modo de implementación le permite asignar recursos dedicados para aplicaciones de Flink específicas, lo que garantiza que tienen suficiente potencia de cálculo y memoria para controlar grandes cargas de trabajo de forma eficaz.

Ventajas
Implementación simplificada del clúster con el archivo jar del trabajo.
API de REST fácil de usar: HDInsight on AKS proporciona API de REST de ARM fáciles de usar para administrar operaciones de trabajo de modo de aplicación como Actualizar, Puntos de retorno, Cancelar, Eliminar.
Actualizaciones de trabajos y administración de estados fáciles de administrar: la integración de Azure Portal nativa proporciona una experiencia sin problemas para actualizar trabajos y restaurarlos a su último estado guardado (punto de retorno). Esta funcionalidad garantiza la continuidad y la integridad de datos a lo largo del ciclo de vida de trabajo.
Automatización de trabajos de Flink mediante Azure Pipelines u otras herramientas CI/CD: con HDInsight on AKS, los usuarios de Flink tienen acceso a API de REST de ARM fáciles de usar y puede integrar sin problemas las operaciones de trabajo de Flink en su instancia de Azure Pipelines u otras herramientas de CI/CD.
Características clave
Detener e iniciar trabajos con puntos de retorno: los usuarios pueden detener e iniciar correctamente sus trabajos de modo de aplicación de Flink desde su estado anterior (punto de retorno). Los puntos de retorno garantizan que se conserve el progreso del trabajo, lo que permite llevar a cabo reanudaciones sin problemas.
Actualizaciones de trabajo: el usuario puede actualizar el trabajo de modo de aplicación en ejecución después de actualizar el archivo jar en la cuenta de almacenamiento. Esta actualización toma automáticamente el punto de retorno e inicia el trabajo de modo de aplicación con un nuevo archivo jar.
Actualizaciones sin estado: realizar un reinicio nuevo para un trabajo de modo de aplicación se simplifica mediante actualizaciones sin estado. Esta característica permite a los usuarios iniciar un reinicio limpio mediante el archivo JAR del trabajo actualizado.
Administración de puntos de retorno: en cualquier momento dado, los usuarios pueden crear puntos de retorno para sus trabajos en ejecución. Estos puntos de retorno se pueden enumerar y usar para reiniciar el trabajo desde un punto de control específico según sea necesario.
Cancelar: cancela el trabajo de forma permanente.
Eliminar: elimine el clúster de modo de aplicación.
Cómo crear un clúster de aplicación de Flink
Requisitos previos
Complete los requisitos previos en las secciones siguientes:
Agregue el archivo jar de trabajo en la cuenta de almacenamiento.
Antes de configurar un clúster de modo de aplicación de Flink, se requieren varios pasos preparatorios. Uno de estos pasos implica colocar el archivo JAR del trabajo de modo de aplicación en la cuenta de almacenamiento del clúster.
Cree un directorio para el archivo JAR del trabajo de modo de aplicación:
Dentro de los contenedores dedicados, cree un directorio donde cargue el archivo JAR del trabajo de modo de aplicación. Este directorio actúa como ubicación para almacenar los archivos JAR que desea incluir en la ruta de clases del clúster o trabajo de Flink.
Directorio de puntos de retorno (opcional):
Si los usuarios piensan tomar puntos de retorno durante la ejecución del trabajo, cree un directorio independiente dentro de la cuenta de almacenamiento para almacenar estos puntos de retorno. Este directorio se usa para almacenar los datos de los puntos de control y los metadatos de los puntos de retorno.
Ejemplo de estructura de directorio:
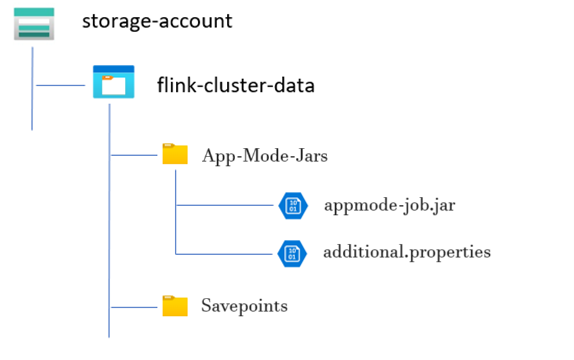

Crear un clúster de modo de aplicación de Flink
Los clústeres de modo de aplicación de Flink se pueden crear una vez completada la implementación del grupo de clústeres, vamos a seguir los pasos en caso de que empiece a trabajar con un grupo de clústeres existente.
En Azure Portal, escriba Grupos de clústeres de HDInsight/HDInsight/HDInsight en AKS y seleccione Grupos de clústeres de Azure HDInsight en AKS para ir a la página de grupos de clústeres. En la página de grupos de clústeres de HDInsight en AKS, seleccione el grupo de clústeres en el que desea crear un nuevo clúster de Flink.

En la página grupo de clústeres específico, haga clic en + Nuevo clúster y proporcione la siguiente información:
Propiedad Descripción Suscripción Este campo se rellena automáticamente con la suscripción de Azure registrada para el grupo de clústeres. Grupo de recursos Este campo se rellena automáticamente y muestra el grupo de recursos en el grupo de clústeres. Region Este campo se rellena automáticamente y muestra la región seleccionada en el grupo de clústeres. Grupo de clústeres Este campo se rellena automáticamente y muestra el nombre del grupo de clústeres en el que se está creando el clúster. Para crear un clúster en un grupo diferente, busque el grupo de clústeres en el portal y haga clic en + Nuevo clúster. HDInsight en la versión del grupo de AKS Este campo se rellena automáticamente y muestra la versión del grupo de clústeres en la que se crea el clúster. HDInsight en la versión de AKS Seleccione la versión secundaria o de revisión de HDInsight en AKS del nuevo clúster. Tipo de clúster En la lista desplegable, seleccione Flink. Nombre del clúster Escriba el nombre del nuevo clúster. Identidad administrada asignada por el usuario En la lista desplegable, seleccione la identidad administrada que se va a usar con el clúster. Si es el propietario de la Identidad de servicio administrada (MSI) y la MSI no tiene el rol de Operador de identidad administrada en el clúster, haga clic en el enlace situado debajo del cuadro para asignar el permiso necesario desde la MSI del grupo de agentes AKS. Si el MSI ya tiene los permisos correctos, no se muestra ningún vínculo. Consulte los requisitos previos para otras asignaciones de roles necesarias para el MSI. Cuenta de almacenamiento En la lista desplegable, seleccione la cuenta de almacenamiento que se va a asociar al clúster de Flink y especifique el nombre del contenedor. A la identidad administrada se le concede acceso a la cuenta de almacenamiento especificada mediante el rol "Propietario de datos de blobs de almacenamiento" durante la creación del clúster. Virtual network La red virtual para el clúster. Subnet La subred virtual para el clúster. Habilitar catálogo de Hive para Flink SQL:
Propiedad Descripción Uso del catálogo de Hive Habilite esta opción para usar un metastore de Hive externo. SQL Database para Hive En la lista desplegable, seleccione la instancia de SQL Database en la que se van a agregar tablas de hive-metastore. Nombre de usuario administrador de SQL Escriba el nombre de usuario de administrador de SQL Server. Esta cuenta es utilizada por el metastore para comunicarse con la base de datos SQL. Key Vault En la lista desplegable, seleccione Key Vault, que contiene un secreto con contraseña para el nombre de usuario administrador del servidor SQL. Es necesario configurar una directiva de acceso con todos los permisos necesarios, como permisos de clave, permisos secretos y permisos de certificado en el MSI, que se usa para la creación del clúster. MSI necesita un rol Administrador de Key Vault. Agregue los permisos necesarios mediante IAM. Nombre secreto de contraseña de SQL Escriba el nombre del secreto de Key Vault donde se almacena la contraseña de la base de datos SQL. 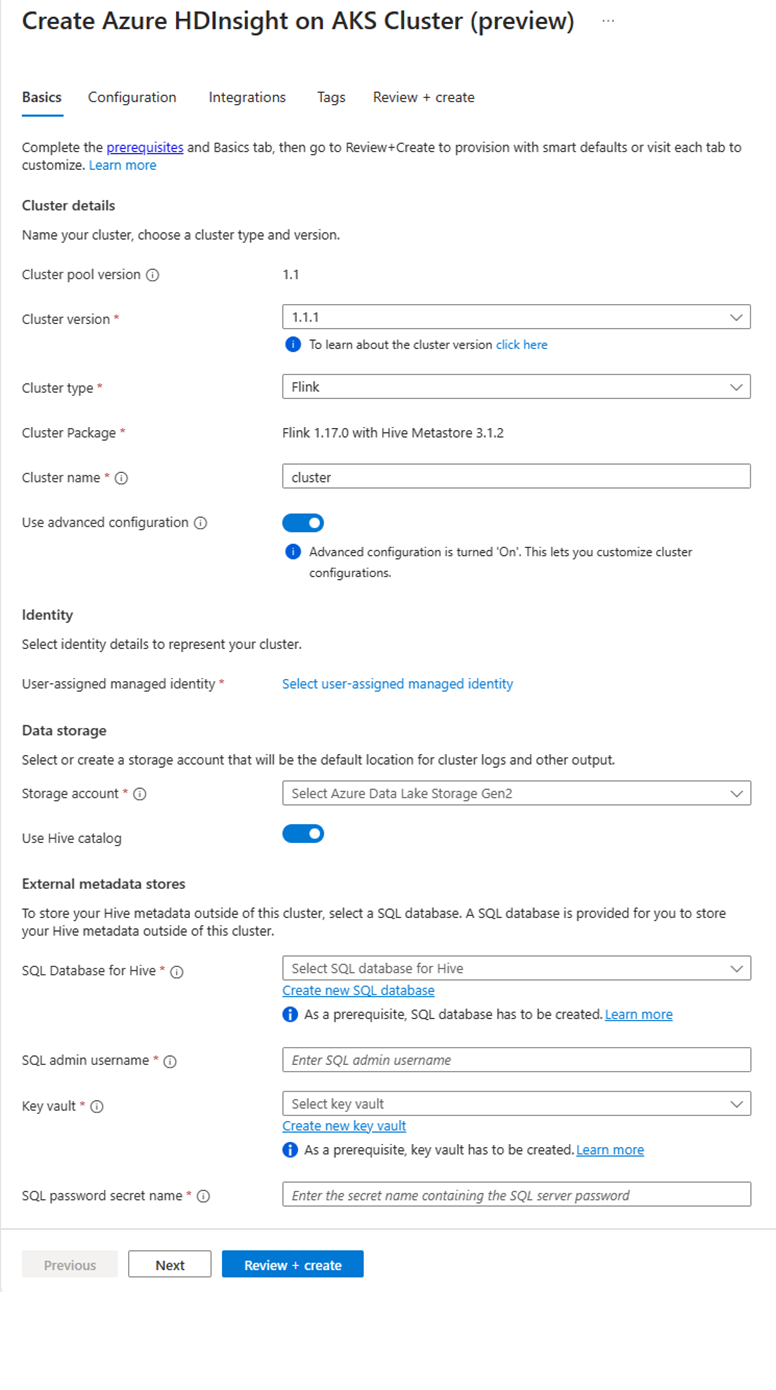
Nota:
De forma predeterminada, utilizamos la cuenta de almacenamiento para el catálogo de Hive igual que la cuenta de almacenamiento y el contenedor utilizados durante la creación del clúster.
Seleccione Siguiente: Configuración para continuar.
En la página Configuración, proporcione la siguiente información:
Propiedad Descripción Tamaño del nodo Seleccione el tamaño del nodo que se va a usar para los nodos de Flink, tanto los nodos principal como los nodos de trabajo. Número de nodos Seleccione el número de nodos para el clúster de Flink; de forma predeterminada, los nodos principales son dos. El ajuste de tamaño de los nodos de trabajo ayuda a determinar las configuraciones del administrador de tareas para Flink. El administrador de trabajos y los servidores de historial están en nodos principales. En la sección Implementación, elija el tipo de implementación como Modo de aplicación y facilite la siguiente información:
Propiedad Descripción Ruta de acceso del archivo Jar Proporcione la ruta de acceso de ABFS (Storage) para el archivo jar del trabajo. Por ejemplo: abfs://flink@teststorage.dfs.core.windows.net/appmode/job.jarClase de entrada (opcional) Clase principal para el clúster de modo de aplicación. Por ejemplo: com.microsoft.testjob Argumentos (opcional) Argumento para la clase principal del trabajo. Nombre del punto de retorno Nombre del punto de retorno antiguo, que desea usar para iniciar el trabajo Modo de actualización Seleccione la opción Actualizar predeterminada. Esta opción se usa cuando se está produciendo la actualización de la versión principal del clúster. Hay tres opciones disponibles. UPDATE: se usa cuando un usuario quiere recuperar desde el último punto de retorno después de la actualización. STATELESS_UPDATE: se usa cuando un usuario quiere reiniciar el trabajo después de una actualización. LAST_STATE_UPDATE: se usa cuando un usuario quiere recuperar el trabajo desde el último punto de control después de la actualización Configuración del trabajo de Flink Agregue más configuración necesaria para el trabajo de Flink. Seleccione "Agregación del registro de trabajo". Active la casilla si desea cargar el registro de trabajo en el almacenamiento remoto. Ayuda a depurar los problemas del trabajo. La ubicación predeterminada del registro de trabajo es "StorageAccount/Container/DeploymentId/logs". Puede cambiar el directorio de registro predeterminado configurando "pipeline.remote.log.dir". El intervalo predeterminado para la recopilación de registros es de 600 segundos. El usuario puede cambiarlo configurando "pipeline.log.aggregation.interval".
En la sección Configuración del servicio, proporcione la siguiente información:
Propiedad Descripción CPU del administrador de tareas Entero. Escriba el tamaño de las CPU del administrador de tareas (en núcleos). Memoria del administrador de tareas en MB Escriba el tamaño de memoria del administrador de tareas en MB. Min de 1800 MB. CPU del administrador de trabajos Entero. Escriba el número de CPU para el administrador de trabajos (en núcleos). Memoria del administrador de trabajos en MB Escriba el tamaño de memoria en MB. Mínimo de 1800 MB. CPU del servidor de historial Entero. Escriba el número de CPU para el administrador de trabajos (en núcleos). Memoria del servidor de historial en MB Escriba el tamaño de memoria en MB. Mínimo de 1800 MB. 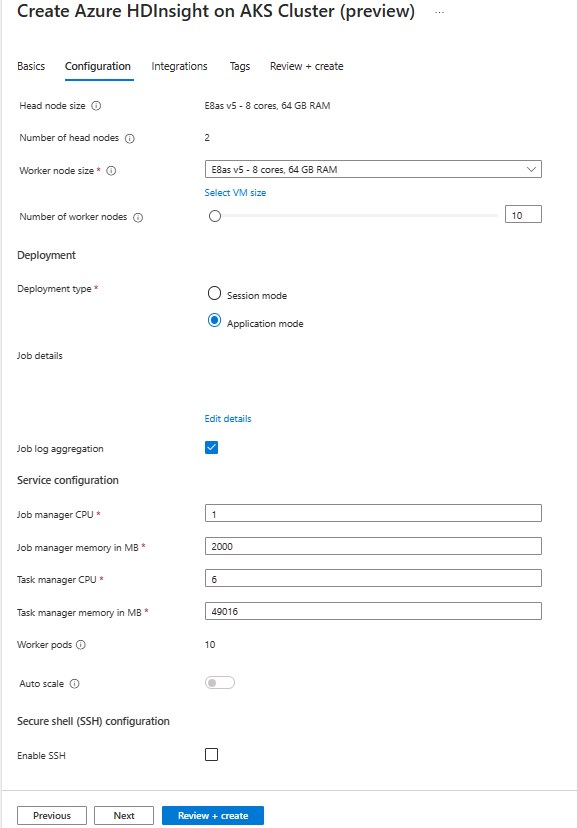
Haga clic en el botón Siguiente: Integración para continuar con la página siguiente.
En la página Integración, proporcione la siguiente información:
Propiedad Descripción Log Analytics Esta característica solo está disponible si el grupo de clústeres tiene asociado el área de trabajo del análisis de registros, una vez habilitados los registros que se van a recopilar se pueden seleccionar. Azure Prometheus Esta característica consiste en ver información y registros directamente en el clúster mediante el envío de métricas y registros al área de trabajo de Azure Monitor. 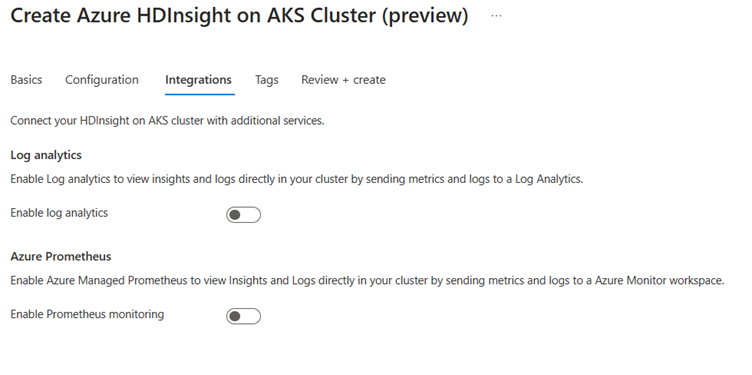
Haga clic en el botón Siguiente: Etiquetas para continuar con la página siguiente.
En la página Etiquetas, proporcione la siguiente información:
Propiedad Descripción Nombre Opcional. Escriba un nombre como HDInsight en AKS para identificar fácilmente todos los recursos asociados a los recursos del clúster. Valor Puede dejar esto en blanco. Resource Seleccione Todos los recursos. Seleccione Siguiente: Revisar y crear para continuar.
En el página Revisar y crear, busque el mensaje Validación correcta en la parte superior de la página y haga clic en Crear.




Se muestra la página Implementación en curso en la que se crea el clúster. Se tarda entre 5 y 10 minutos en crear el clúster. Una vez creado el clúster, se muestra el mensaje "Su implementación ha finalizado". Si se aleja de la página, puede comprobar el estado actual de las notificaciones.
Administrar el trabajo de aplicación desde el portal
HDInsight AKS proporciona formas de administrar trabajos de Flink. Puede volver a iniciar un trabajo con errores. Reinicie el trabajo desde el portal.
Para ejecutar el trabajo de Flink desde el portal, vaya a:
Portal > Grupo de clústeres de HDInsight on AKS > Clúster de Flink > Configuración > Trabajos de Flink.

Detener: detener el trabajo no requería ningún parámetro. El usuario puede detener el trabajo seleccionando la acción. Una vez detenido el trabajo, el estado del trabajo en el portal se DETENDRÁ.
Inicio: inicia el trabajo desde el punto de retorno. Para iniciar el trabajo, seleccione el trabajo detenido e inícielo.
Actualizar: Actualizar ayuda a reiniciar trabajos con código de trabajo actualizado. Los usuarios deben actualizar el archivo JAR del trabajo más reciente en la ubicación de almacenamiento y actualizar el trabajo desde el portal. Esta acción detiene el trabajo con el punto de retorno y se inicia de nuevo con el archivo JAR más reciente.
Actualización sin estado: sin estado es como una actualización, pero implica un reinicio nuevo del trabajo con el código más reciente. Una vez actualizado el trabajo, el estado del trabajo en el portal se muestra como En ejecución.
Punto de retorno: tome el punto de retorno para el trabajo de Flink.
Cancelar: finalice el trabajo.
Eliminar: elimine el clúster de modo de aplicación.
Ver detalles del trabajo: para ver los detalles del trabajo, el usuario puede hacer clic en el nombre del trabajo. Proporciona los detalles sobre el trabajo y el resultado de la última acción.
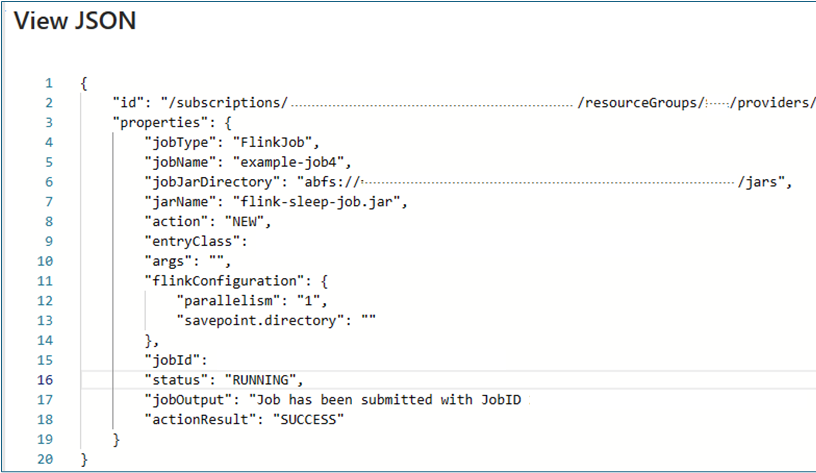

Para cualquier acción con error, esta vista json proporciona excepciones detalladas y los motivos del error.