¿Por qué el procesamiento incremental de flujos?
Las empresas controladas por datos actuales producen datos continuamente, lo que requiere canalizaciones de datos de ingeniería que ingieren y transforman continuamente estos datos. Estas canalizaciones deben poder procesar y entregar datos exactamente una vez, generar resultados con latencias inferiores a 200 milisegundos y siempre intentar minimizar los costos.
En este artículo se describen los enfoques de procesamiento por lotes e incrementales para las canalizaciones de datos de ingeniería, por qué el procesamiento incremental de flujos es la mejor opción y los pasos siguientes para empezar a trabajar con las ofertas de procesamiento incremental de flujos de Databricks, Streaming en Azure Databricks y ¿Qué es Delta Live Tables?. Estas características permiten escribir y ejecutar rápidamente canalizaciones que garantizan la semántica de entrega, la latencia, el costo, etc.
Problemas de trabajos por lotes repetidos
Al configurar la canalización de datos, es posible que al principio escriba trabajos por lotes repetidos para ingerir los datos. Por ejemplo, cada hora podría ejecutar un trabajo de Spark que lee del origen y escribe datos en un receptor como Delta Lake. El desafío con este enfoque es procesar incrementalmente el origen, ya que el trabajo de Spark que se ejecuta cada hora debe comenzar donde finalizó el último. Puede registrar la marca de tiempo más reciente de los datos procesados y, a continuación, seleccionar todas las filas con marcas de tiempo más recientes que esa marca de tiempo, pero hay problemas:
Para ejecutar una canalización de datos continua, puede intentar programar un trabajo por lotes por hora que lee incrementalmente del origen, realiza transformaciones y escribe el resultado en un receptor, como Delta Lake. Este enfoque puede tener problemas:
- Un trabajo de Spark que consulta todos los datos nuevos después de una marca de tiempo perderá los datos en tiempo de ejecución.
- Un trabajo de Spark que produce un error puede provocar la interrupción de las garantías exactamente una vez, si no se controla cuidadosamente.
- Un trabajo de Spark que muestra el contenido de las ubicaciones de almacenamiento en la nube para buscar nuevos archivos será costoso.
A continuación, deberá transformar repetidamente estos datos. Puede escribir trabajos por lotes repetidos que agreguen los datos o apliquen otras operaciones, lo que complica aún más y reduce la eficacia de la canalización.
Ejemplo de lote
Para comprender completamente los problemas de ingesta y transformación por lotes de la canalización, tenga en cuenta los ejemplos siguientes.
Datos perdidos
Dado un tema de Kafka con datos de uso que determina cuánto se cobra a los clientes y la canalización se ingiere en lotes, la secuencia de eventos puede tener este aspecto:
- El primer lote tiene dos registros a las 8:00 y 8:30 a. m.
- Actualice la marca de tiempo más reciente a las 8:30 a. m.
- Obtiene otro registro a las 8:15 a. m.
- El segundo lote consulta todo después de las 8:30 a. m., por lo que se pierde el registro a las 8:15 a. m.
Además, no desea sobrecargar ni sobrecargar a los usuarios, por lo que debe asegurarse de que está ingeriendo todos los registros exactamente una vez.
Procesamiento redundante
A continuación, supongamos que los datos contienen filas de compras de usuario y desea agregar las ventas por hora para que conozca los tiempos más populares de la tienda. Si las compras de la misma hora llegan en lotes diferentes, tendrá varios lotes que generan salidas durante la misma hora:
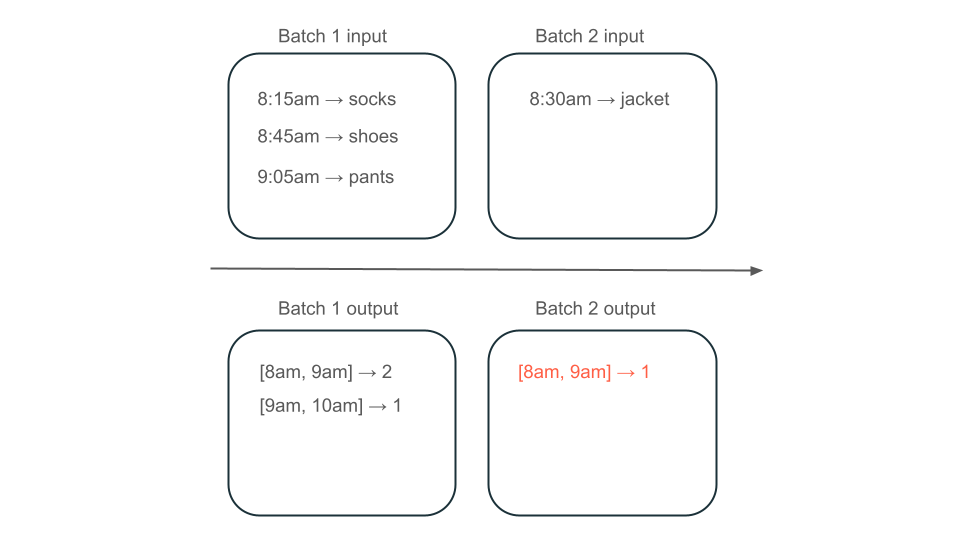
¿La ventana de 8 a 9 a. m. tiene dos elementos (la salida del lote 1), un elemento (la salida del lote 2) o tres (la salida de ninguno de los lotes)? Los datos necesarios para generar una ventana de tiempo determinada aparecen en varios lotes de transformación. Para resolver esto, puede dividir los datos por día y volver a procesar toda la partición cuando necesite calcular un resultado. A continuación, puede sobrescribir los resultados en el receptor:
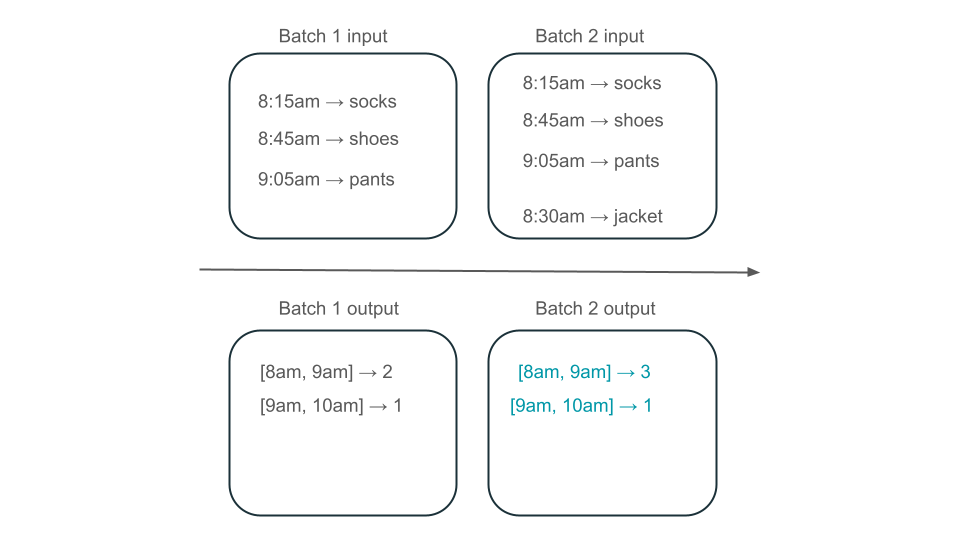
Sin embargo, esto se produce a costa de la latencia y el costo, ya que el segundo lote debe realizar el trabajo innecesario de procesamiento de datos que es posible que ya haya procesado.
No hay problemas con el procesamiento incremental de flujos
El procesamiento incremental de flujos facilita la ingesta y transformación de datos para evitar todos los problemas de los trabajos por lotes repetidos. Databricks Structured Streaming y Delta Live Tables administran las complejidades de implementación del streaming para permitirle centrarse solo en la lógica de negocios. Solo tiene que especificar a qué origen conectarse, a qué transformaciones se deben realizar en los datos y a dónde escribir el resultado.
Ingesta incremental
La ingesta incremental en Databricks se basa en Apache Spark Structured Streaming, que puede consumir incrementalmente un origen de datos y escribirlo en un receptor. El motor de Structured Streaming puede consumir datos exactamente una vez y el motor puede controlar los datos desordenados. El motor se puede ejecutar en cuadernos o mediante tablas de streaming en Delta Live Tables.
El motor de Structured Streaming en Databricks proporciona orígenes de streaming propietarios, como AutoLoader, que pueden procesar archivos en la nube de forma incremental de forma rentable. Databricks también proporciona conectores para otros autobuses de mensajes populares como Apache Kafka, Amazon Kinesis, Apache Pulsar y Google Pub/Sub.
Transformación incremental
La transformación incremental en Databricks con Structured Streaming permite especificar transformaciones en DataFrames con la misma API que una consulta por lotes, pero realiza un seguimiento de los datos entre lotes y valores agregados a lo largo del tiempo para que no tenga que hacerlo. Nunca tiene que volver a procesar los datos, por lo que es más rápido y rentable que los trabajos por lotes repetidos. Structured Streaming genera un flujo de datos que puede anexar al receptor, como Delta Lake, Kafka o cualquier otro conector compatible.
Las vistas materializadas en Delta Live Tables funcionan con el motor de la enzima. La enzima sigue procesando incrementalmente el origen, pero en lugar de producir una secuencia, crea una vista materializada, que es una tabla calculada previamente que almacena los resultados de una consulta que se le proporciona. La enzima puede determinar eficazmente cómo afectan los nuevos datos a los resultados de la consulta y mantiene actualizada la tabla calculada previamente.
Las vistas materializadas crean una vista sobre el agregado que siempre se actualiza de forma eficaz para que, por ejemplo, en el escenario descrito anteriormente, sepa que la ventana de 8 a 9 a. m. tiene tres elementos.
Structured Streaming o Delta Live Tables?
La diferencia significativa entre Structured Streaming y Delta Live Tables es la manera en que se operacionalizan las consultas de streaming. En Structured Streaming, especifique manualmente muchas configuraciones y tendrá que unir manualmente las consultas. Debe iniciar consultas explícitamente, esperar a que finalicen, cancelarlas tras un error y otras acciones. En Delta Live Tables, asigna mediante declaración a Delta Live Tables las canalizaciones que se van a ejecutar y las mantiene en ejecución.
Delta Live Tables también tiene características como Vistas materializadas, que de forma eficaz e incremental precomputen las transformaciones de los datos.
Para más información sobre estas características, consulte Streaming en Azure Databricks y ¿Qué es Delta Live Tables?.
Pasos siguientes
Cree la primera canalización con Delta Live Tables. Consulte Tutorial: ejecute su primera canalización de Delta Live Tables.
Ejecute las primeras consultas de Structured Streaming en Databricks. Consulte Ejecución de la primera carga de trabajo de Structured Streaming.
Use una vista materialiada. Consulte Uso de vistas materializadas en Databricks SQL.