Shiny en Azure Databricks
Shiny es un paquete de R, disponible en CRAN, que se usa para crear paneles y aplicaciones de R interactivos. Puede usar Shiny dentro de RStudio Server hospedado en clústeres de Azure Databricks. También puede desarrollar, hospedar y compartir aplicaciones de Shiny directamente desde un cuaderno de Azure Databricks.
Para empezar a trabajar con Shiny, consulte los tutoriales de Shiny. Puede ejecutar estos tutoriales en cuadernos de Azure Databricks.
En este artículo se describe cómo ejecutar aplicaciones Shiny en Azure Databricks y cómo usar Apache Spark dentro de aplicaciones Shiny.
Shiny dentro de cuadernos de R
Introducción a Shiny dentro de cuadernos de R
El paquete Shiny se incluye en Databricks Runtime. Puede desarrollar y probar de forma interactiva aplicaciones Shiny dentro de los cuadernos de R de Azure Databricks de forma similar a RStudio hospedado.
Para comenzar, siga estos pasos:
Cree un cuaderno de R.
Importe el paquete de Shiny y ejecute la aplicación de ejemplo
01_hellocomo se muestra a continuación:library(shiny) runExample("01_hello")Cuando la aplicación está lista, la salida incluye la dirección URL de la aplicación Shiny como un vínculo en el que se puede hacer clic, lo que abre una nueva pestaña. Para compartir esta aplicación con otros usuarios, consulte Compartir la dirección URL de la aplicación Shiny.

Nota:
- Los mensajes de registro aparecen en el resultado del comando, de forma similar al mensaje de registro predeterminado (
Listening on http://0.0.0.0:5150) que se muestra en el ejemplo. - Para detener la aplicación Shiny, haga clic en Cancelar.
- La aplicación Shiny utiliza el proceso del cuaderno de R. Si desasocia el cuaderno del clúster o cancela la celda que ejecuta la aplicación, la aplicación Shiny se termina. No se pueden ejecutar otras celdas mientras se ejecuta la aplicación Shiny.
Ejecución de aplicaciones Shiny desde carpetas de Git de Databricks
Puede ejecutar aplicaciones de Shiny que están activadas Carpetas de Git de Databricks.
Ejecute la aplicación.
library(shiny) runApp("006-tabsets")
Ejecución de aplicaciones Shiny a partir de archivos
Si el código de la aplicación Shiny forma parte de un proyecto administrado por el control de versiones, puede ejecutarlo dentro del cuaderno.
Nota:
Debe usar la ruta de acceso absoluta o establecer el directorio de trabajo con setwd().
Consulte el código de un repositorio utilizando un código similar a:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Para ejecutar la aplicación, escriba código similar al siguiente en otra celda:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Compartir la dirección URL de la aplicación Shiny
La dirección URL de la aplicación Shiny generada al iniciar una aplicación se puede compartir con otros usuarios. Cualquier usuario de Azure Databricks con el permiso CAN ATTACH TO en el clúster puede ver e interactuar con la aplicación siempre y cuando se estén ejecutando tanto la aplicación como el clúster.
Si finaliza el clúster en el que se ejecuta la aplicación, la aplicación ya no es accesible. Puede deshabilitar la terminación automática en la configuración del clúster.
Si adjunta y ejecuta el cuaderno que hospeda la aplicación Shiny en un clúster diferente, se cambia la dirección URL de Shiny. Además, si reinicia la aplicación en el mismo clúster, Shiny podría elegir un puerto aleatorio diferente. Para garantizar una dirección URL estable, puede establecer la opción shiny.port o, al reiniciar la aplicación en el mismo clúster, puede especificar el argumento port.
Shiny en un servidor de RStudio hospedado
Requisitos
Importante
Con RStudio Server Pro, debe deshabilitar la autenticación con proxy.
Asegúrese de que auth-proxy=1 no está dentro de /etc/rstudio/rserver.conf.
Introducción a Shiny en RStudio Server hospedado
Abra RStudio en Azure Databricks.
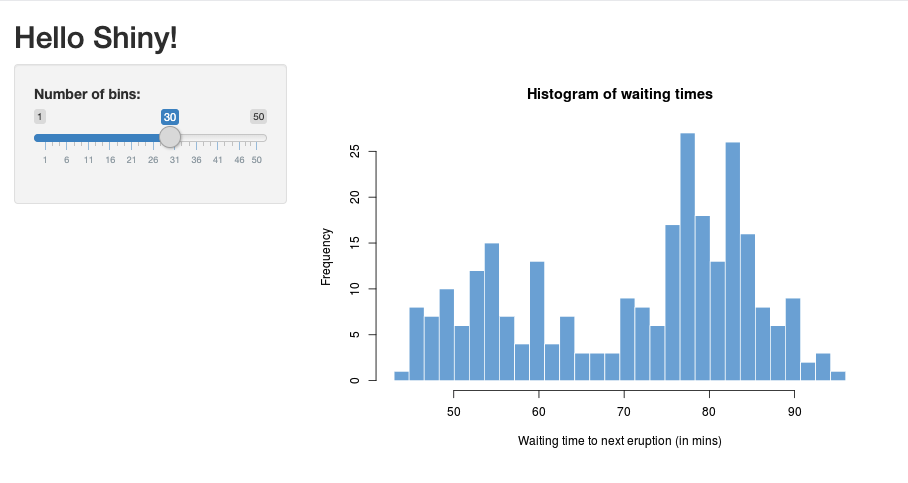
En RStudio, importe el paquete de Shiny y ejecute la aplicación de ejemplo
01_hellocomo se muestra a continuación:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Aparece una nueva ventana en la que se muestra la aplicación Shiny.
Ejecución de una aplicación de Shiny a partir de un script de R
Para ejecutar una aplicación de Shiny desde un script de R, abra el script de R en el editor de RStudio y haga clic en el botón Ejecutar aplicación en la parte superior derecha.
Uso de Apache Spark en aplicaciones de Shiny
Puede usar Apache Spark dentro de aplicaciones de Shiny con SparkR o sparklyr.
Uso de SparkR con Shiny en un cuaderno
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Uso de sparklyr con Shiny en un cuaderno
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
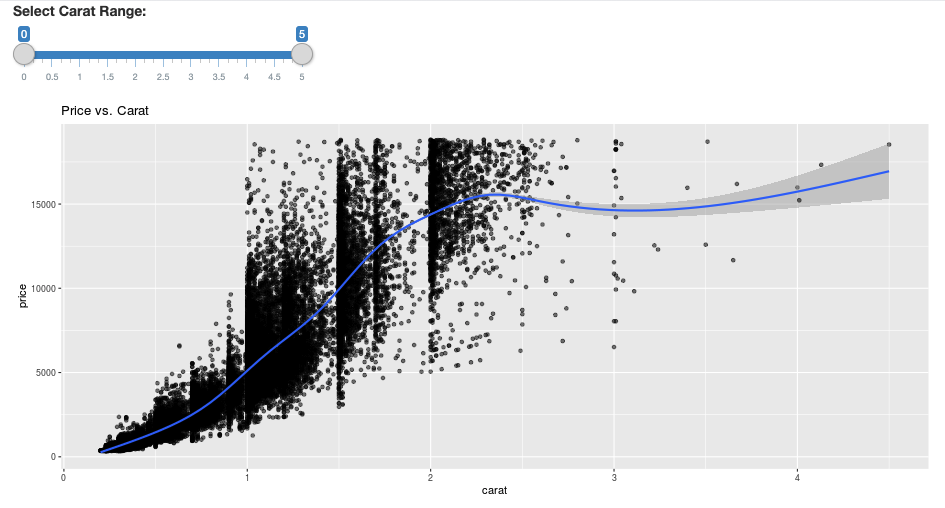
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
Preguntas más frecuentes
- ¿Por qué aparece atenuada la aplicación de Shiny pasado un determinado tiempo?
- ¿Por qué desaparece la ventana del visor de Shiny después de un determinado tiempo?
- ¿Por qué los trabajos de larga duración de Spark nunca vuelven?
- ¿Cómo se evita el tiempo de espera?
- La aplicación se bloquea inmediatamente después de iniciarse, aunque el código parece que es correcto. ¿Qué está ocurriendo?
- ¿Cuántas conexiones se pueden aceptar para un vínculo de aplicación de Shiny durante el desarrollo?
- ¿Puede usarse una versión diferente del paquete de Shiny de la que está instalada en Databricks Runtime?
- ¿Cómo se puede desarrollar una aplicación de Shiny que se puede publicar en un servidor de Shiny y acceder a los datos en Azure Databricks?
- ¿Se puede desarrollar una aplicación de Shiny dentro de un cuaderno de Azure Databricks?
- ¿Cómo puedo guardar las aplicaciones Shiny que he desarrollado en RStudio Server hospedado?
¿Por qué aparece atenuada la aplicación de Shiny pasado un determinado tiempo?
Si no existe ninguna interacción con la aplicación de Shiny, la conexión a la aplicación se apaga después de unos 4 minutos.
Para volver a conectarse, actualice la página de la aplicación de Shiny. Se restablece el estado del panel.
¿Por qué desaparece la ventana del visor de Shiny después de un determinado tiempo?
Si la ventana del visor de Shiny desaparece después de estar inactiva durante varios minutos, se debe al mismo tiempo de espera que cuando la aplicación se atenúa.
¿Por qué los trabajos de larga duración de Spark nunca vuelven?
Esto también se debe al tiempo de espera de inactividad. Cualquier trabajo de Spark que se ejecute durante más tiempo que los tiempos de espera mencionados anteriormente no podrá representar su resultado porque la conexión se cierra antes de que el trabajo vuelva.
¿Cómo se evita el tiempo de espera?
Hay una solución alternativa sugerida en Solicitud de característica: Hacer que el cliente envíe mensajes activos para evitar el tiempo de espera de TCP en algunos equilibradores de carga en Github. La solución alternativa envía latidos para mantener el WebSocket activo cuando la aplicación está inactiva. Sin embargo, si la aplicación está bloqueada por un cálculo de larga duración, esta solución alternativa no funciona.
Shiny no admite tareas de larga duración. Una entrada de blog de Shiny recomienda usar promesas y futuros para ejecutar tareas de larga duración de forma asincrónica y mantener la aplicación desbloqueada. Este es un ejemplo en el que se usan latidos para mantener la aplicación de Shiny activa y se ejecuta un trabajo de Spark de larga duración en una construcción
future.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages(‘future’) install.packages(‘promises’) library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)Hay un límite máximo de 12 horas desde que se carga la página inicial, después de lo cual se finalizará cualquier conexión, incluso si está activa. Debe actualizar la aplicación Shiny para volver a conectarse en estos casos. Sin embargo, la conexión WebSocket subyacente puede cerrarse en cualquier momento por una variedad de factores, como la inestabilidad de red o el modo de suspensión del equipo. Databricks recomienda volver a escribir aplicaciones de Shiny de forma que no requieran una conexión de larga duración y no dependan demasiado del estado de sesión.
La aplicación se bloquea inmediatamente después de iniciarse, aunque el código parece que es correcto. ¿Qué está ocurriendo?
La cantidad total de datos que se puede mostrar en una aplicación Shiny en Azure Databricks no puede pasar de 50 MB. Si el tamaño total de los datos de la aplicación supera este límite, se bloqueará inmediatamente después del inicio. Para evitar esto, Databricks recomienda reducir el tamaño de los datos, por ejemplo, disminuir la resolución de los datos mostrados o de las imágenes.
¿Cuántas conexiones se pueden aceptar para un vínculo de aplicación de Shiny durante el desarrollo?
Databricks recomienda hasta 20.
¿Puede usarse una versión diferente del paquete de Shiny de la que está instalada en Databricks Runtime?
Sí. Consulte Corrección de la versión de los paquetes de R.
¿Cómo se puede desarrollar una aplicación de Shiny que se puede publicar en un servidor de Shiny y acceder a los datos en Azure Databricks?
Aunque puede acceder a los datos de forma natural mediante SparkR o sparklyr durante el desarrollo y las pruebas en Azure Databricks, después de publicar una aplicación de Shiny en un servicio de hospedaje independiente, no puede acceder directamente a los datos y tablas de Azure Databricks.
Para permitir que la aplicación funcione fuera de Azure Databricks, debe volver a escribir cómo acceder a los datos. Estas son algunas opciones:
- Uso de JDBC/ODBC para enviar consultas a un clúster de Azure Databricks.
- Uso de Databricks Connect.
- Acceso directo a los datos en el almacenamiento de objetos.
Databricks recomienda trabajar con el equipo de soluciones de Azure Databricks para encontrar el mejor enfoque para la arquitectura de análisis y datos existente.
¿Se puede desarrollar una aplicación de Shiny dentro de un cuaderno de Azure Databricks?
Sí, puede desarrollar una aplicación de Shiny dentro de un cuaderno de Azure Databricks.
¿Cómo puedo guardar las aplicaciones Shiny que he desarrollado en RStudio Server hospedado?
Puede guardar el código de la aplicación en DBFS o comprobar el código en el control de versiones.