Técnicas de CI/CD con carpetas de Git y Databricks Git (Repositorios)
Aprenda técnicas para usar carpetas de Git de Databricks en flujos de trabajo de CI/CD. Al configurar carpetas de Git de Databricks en el área de trabajo, puede usar el control de código fuente para los archivos de proyecto en repositorios de Git y puede integrarlas en las canalizaciones de ingeniería de datos.
La figura siguiente muestra información general sobre las técnicas y el flujo de trabajo.
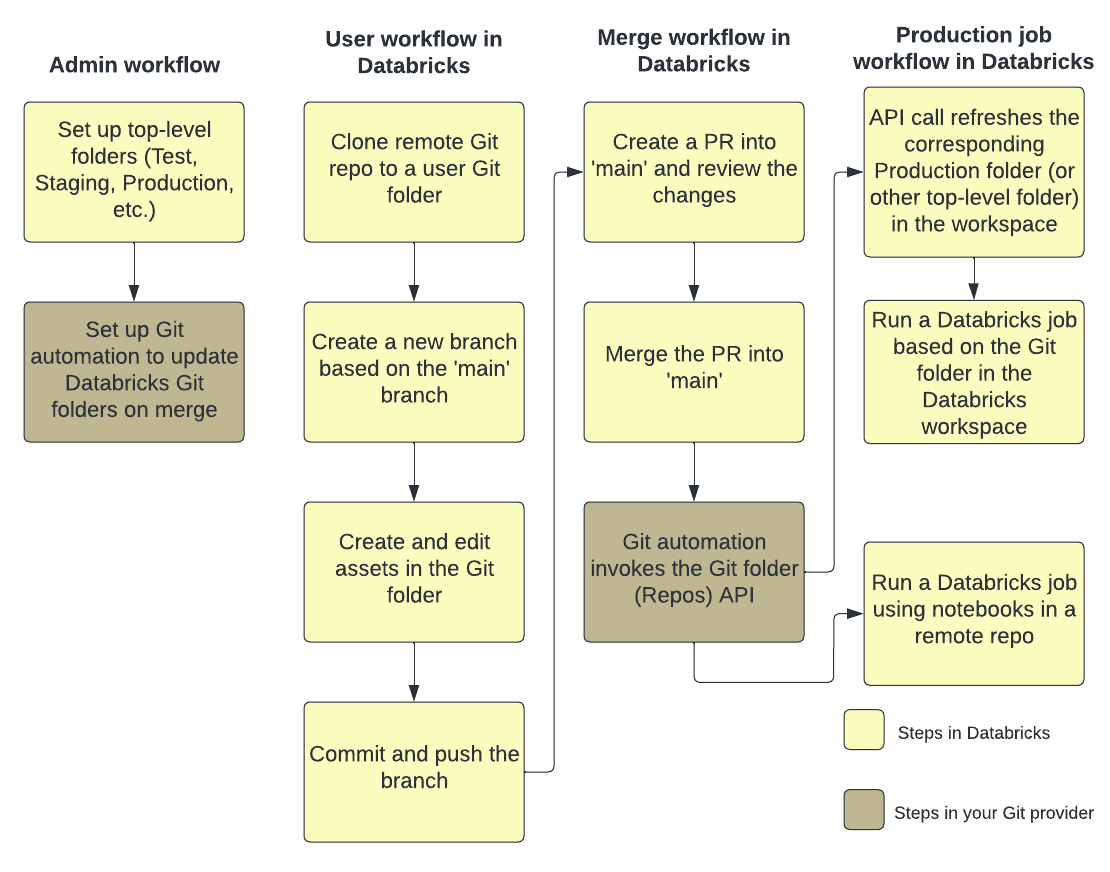
Para obtener información general sobre CI/CD con Azure Databricks, consulte ¿Qué es CI/CD en Azure Databricks?
Flujo de desarrollo
Las carpetas de Git de Databricks tienen carpetas de nivel de usuario. Las carpetas de nivel de usuario se crean automáticamente cuando los usuarios clonan por primera vez un repositorio remoto. Puede considerar las carpetas de Git de Databricks en carpetas de usuario como “comprobaciones locales” que son individuales para cada usuario y donde los usuarios realizan cambios en su código.
En la carpeta de usuario de las carpetas de Git de Databricks, clone el repositorio remoto. Un procedimiento recomendado es crear una nueva rama de características o seleccionar una rama creada previamente para su trabajo, en lugar de confirmar y enviar directamente los cambios en la rama principal. Puede realizar cambios, confirmar y enviar cambios en esa rama. Cuando esté listo para combinar el código, puede hacerlo en la interfaz de usuario de carpetas de Git.
Requisitos
Este flujo de trabajo requiere que ya haya configurado la integración con Git.
Nota:
Databricks recomienda que cada desarrollador trabaje en su propia rama de características. Para información sobre cómo resolver conflictos de combinación, consulte Resolución de conflictos de combinación.
Colaboración en carpetas de Git
El flujo de trabajo siguiente usa una rama llamada feature-b que se basa en la rama principal.
- Clone el repositorio de Git existente en el área de trabajo de Databricks.
- Use la interfaz de usuario de carpetas de Git para crear una rama de características desde la rama principal. En este ejemplo se usa una sola rama de características
feature-bpor motivos de simplicidad. Puede crear y usar varias ramas de características para realizar su trabajo. - Realice las modificaciones en los cuadernos y otros archivos de Azure Databricks en el repositorio.
- Confirme e inserte los cambios en el repositorio de Git.
- Ahora, los colaboradores pueden clonar el repositorio de Git en su propia carpeta de usuario.
- Al trabajar en una nueva rama, un compañero de trabajo realiza cambios en los cuadernos y otros archivos de la carpeta Git.
- El colaborador confirma y envía sus cambios al proveedor de Git.
- Para combinar los cambios de otras ramas o volver a base de la rama característica-b en Databricks, en la interfaz de usuario de carpetas de Git, use uno de los flujos de trabajo siguientes:
- Combinación de ramas. Si no hay ningún conflicto, la combinación se inserta en el repositorio de Git remoto mediante
git push. - Fusionar mediante cambio de base en otra rama.
- Combinación de ramas. Si no hay ningún conflicto, la combinación se inserta en el repositorio de Git remoto mediante
- Cuando esté listo para combinar el trabajo en el repositorio de Git remoto y
mainrama, use la interfaz de usuario de carpetas de Git para combinar los cambios de característica-b. Si lo prefiere, puede combinar los cambios directamente en el repositorio de Git que respalda la carpeta de Git.
Flujo de trabajo de producción
Las carpetas de Git de Databricks proporcionan dos opciones para ejecutar los trabajos de producción:
- Opción 1: Proporcione una referencia remota de Git en la definición del trabajo. Por ejemplo, ejecute un cuaderno específico en la rama
mainde un repositorio de Git. - opción 2: configure un repositorio de Git de producción y llame a las API de Repos para actualizarlo mediante programación. Ejecute trabajos en la carpeta Git de Databricks que clona este repositorio remoto. La llamada de Repos API debe ser la primera tarea del trabajo.
Opción 1: Ejecute trabajos mediante cuadernos en un repositorio remoto
Simplifique el proceso de definición de trabajo y mantenga un único origen de verdad mediante la ejecución de un trabajo de Azure Databricks con cuadernos ubicadas en un repositorio de Git remoto. Esta referencia de Git puede ser una confirmación, etiqueta o rama de Git y la proporciona en la definición del trabajo.
Esto ayuda a evitar cambios accidentales en el trabajo de producción, como cuando un usuario realiza modificaciones locales en un repositorio de producción o cambia las ramas. También automatiza el paso de CD, ya que no es necesario crear una carpeta Git de producción independiente en Databricks, administrar permisos para él y mantenerla actualizada.
Consulte Uso de Git con trabajos.
opción 2: Configuración de una carpeta Git de producción y automatización de Git
En esta opción, configurará una carpeta Git de producción y automatización para actualizar la carpeta Git en combinación.
Paso 1: Configuración de las carpetas de nivel superior
El administrador crea carpetas de nivel superior que no son de usuario. El caso de uso más común para estas carpetas de nivel superior es crear carpetas de desarrollo, almacenamiento provisional y producción que contengan carpetas de Git de Databricks para las versiones o ramas adecuadas para desarrollo, almacenamiento provisional y producción. Por ejemplo, si la empresa usa la rama main para producción, la “carpeta Git de producción” debe tener desprotegida la rama main desprotegida.
Normalmente, los permisos en estas carpetas de nivel superior son de solo lectura para todos los usuarios que no son administradores del área de trabajo. Para estas carpetas de nivel superior, se recomienda proporcionar solo entidades de servicio con permisos CAN EDIT y CAN MANAGE para evitar modificaciones accidentales en el código de producción por parte de los usuarios del área de trabajo.
Paso 2: Configuración de actualizaciones automatizadas en carpetas de Git de Databricks con la API de carpetas de Git
Para mantener una carpeta de Git en Databricks en la versión más reciente, puede configurar la automatización de Git para llamar a la API de repositorios . En el proveedor de Git, configure la automatización que, después de cada combinación correcta de una solicitud de incorporación de cambios en la rama principal, llama al punto de conexión de la API repos en la carpeta Git adecuada para actualizarla a la versión más reciente.
Por ejemplo, en GitHub esto se puede lograr con Acciones de GitHub. Para más información, consulte Repos API.
Uso de una entidad de servicio para la automatización con carpetas de Git en Databricks
Puede usar la consola de la cuenta de Azure Databricks o la CLI de Databricks para crear una entidad de servicio autorizada para acceder a las carpetas de Git del área de trabajo.
Para crear una nueva entidad de servicio, consulte Administrar entidades de servicio. Cuando tenga una entidad de servicio en el área de trabajo, puede vincular sus credenciales de Git a ella para que pueda acceder a las carpetas de Git del área de trabajo como parte de la automatización.
Autorización de una entidad de servicio para tener acceso a carpetas de Git
Para proporcionar acceso autorizado a los repositorios de Git para un principal de servicio mediante la consola de la cuenta de Azure Databricks:
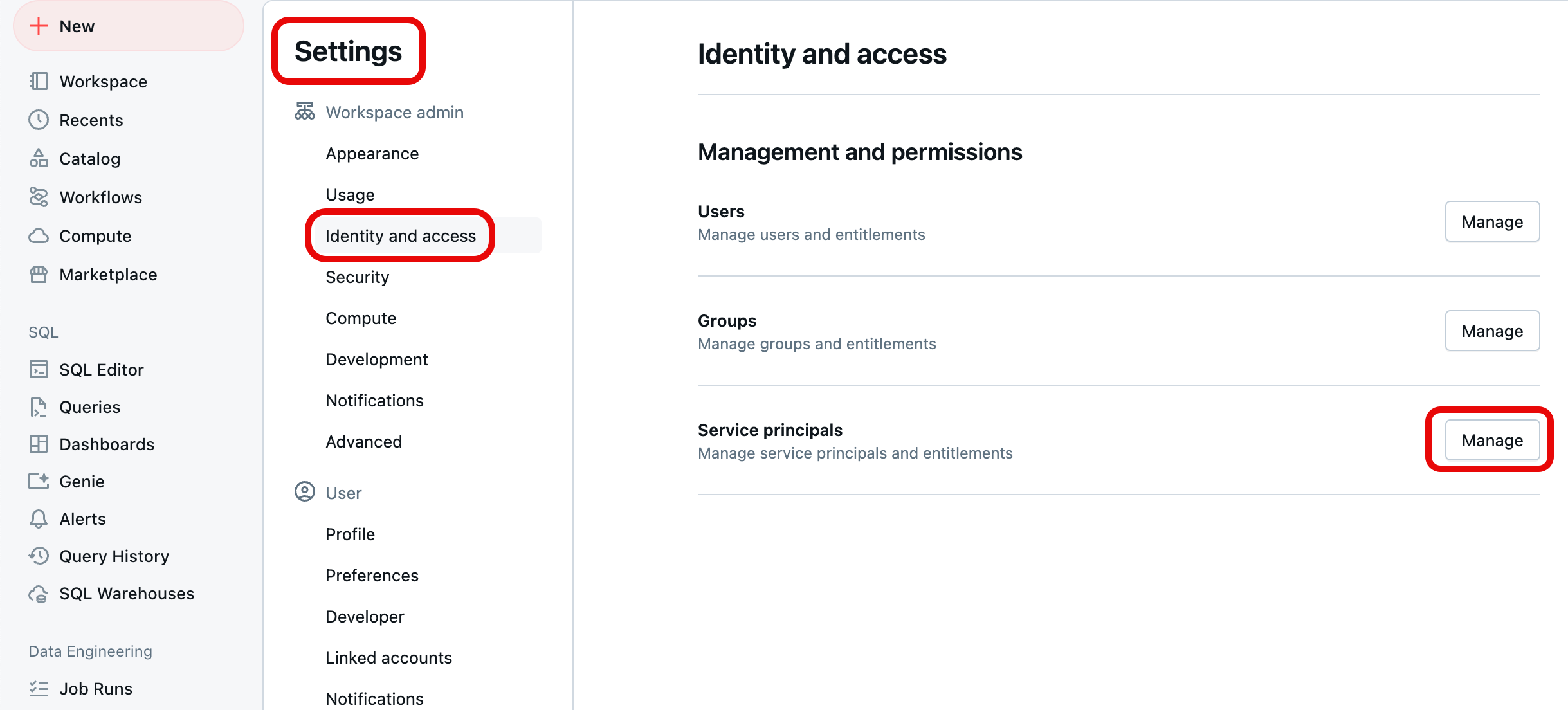
Inicie sesión en el área de trabajo de Azure Databricks. Debe tener privilegios de administrador en el área de trabajo para completar estos pasos. Si no tiene privilegios de administrador para el área de trabajo, hágalo o póngase en contacto con el administrador de la cuenta.
En la esquina superior derecha de cualquier página, haga clic en el nombre de usuario y seleccione Configuración.
Seleccione Identidad y acceso en Administrador de área de trabajo en el panel de navegación de la izquierda y, a continuación, seleccione el botón Administrar para Entidades de servicio.
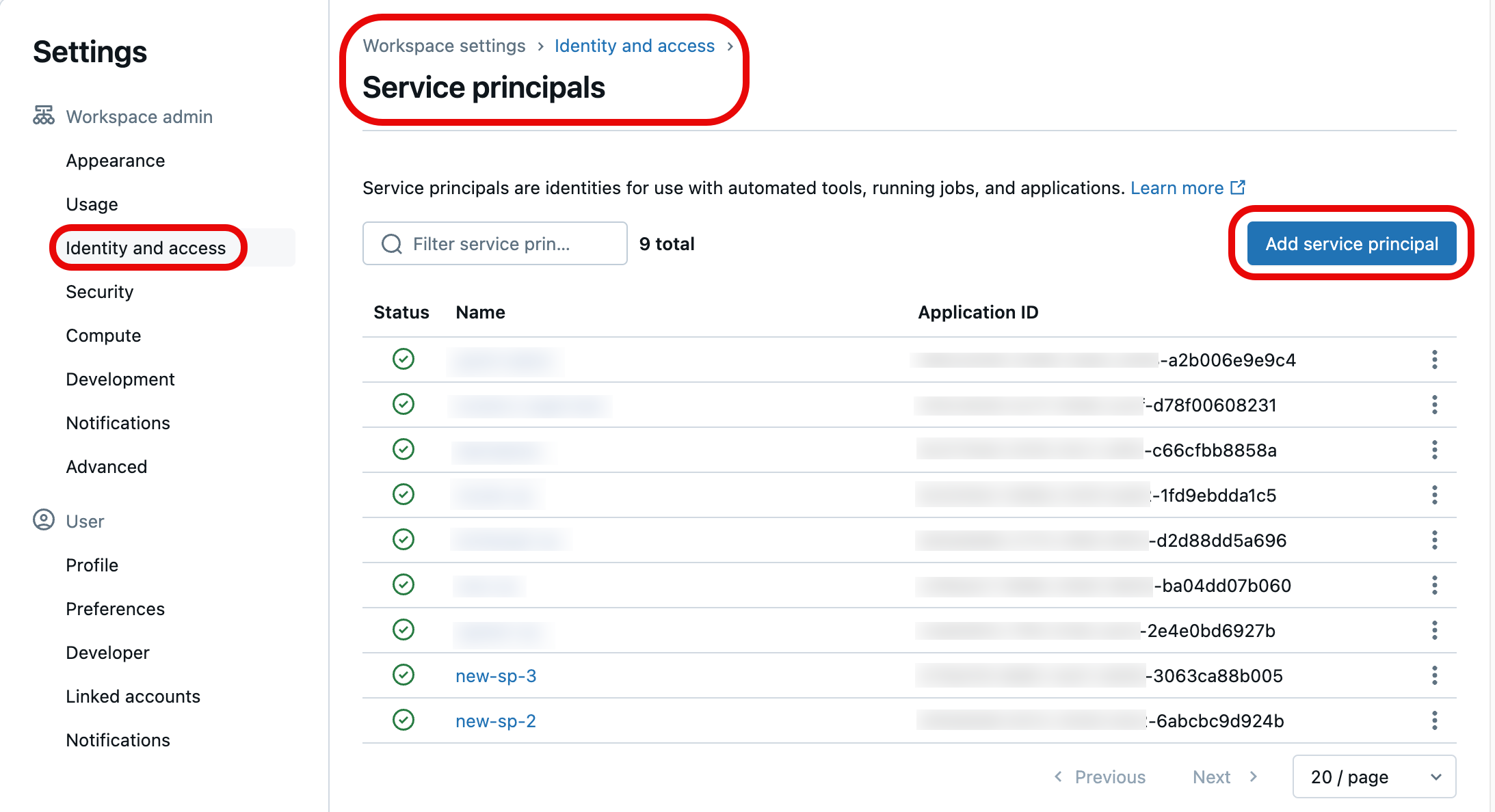
En la lista de entidades de servicio, seleccione la que desea actualizar con credenciales de acceso a Git. También puede crear una nueva entidad de servicio seleccionando Agregar entidad de servicio.
Seleccione la pestaña Integración de Git. (Si no creó la entidad de servicio o no se le ha asignado el privilegio del administrador de entidades de servicio, aparecerá atenuada). En él, elija el Proveedor de Git para las credenciales (por ejemplo, GitHub), seleccione Vincular cuenta de Gity, a continuación, seleccione Vínculo.
También puede usar un token de acceso personal (PAT) de Git si no desea vincular sus propias credenciales de Git. Para usar un PAT en su lugar, seleccione Token de acceso personal y proporcione la información del token para que la cuenta de Git la use al autenticar el acceso de la entidad de servicio. Para más información sobre cómo adquirir un PAT desde un proveedor de Git, consulte Configuración de credenciales de Git & conectar un repositorio remoto a Azure Databricks.
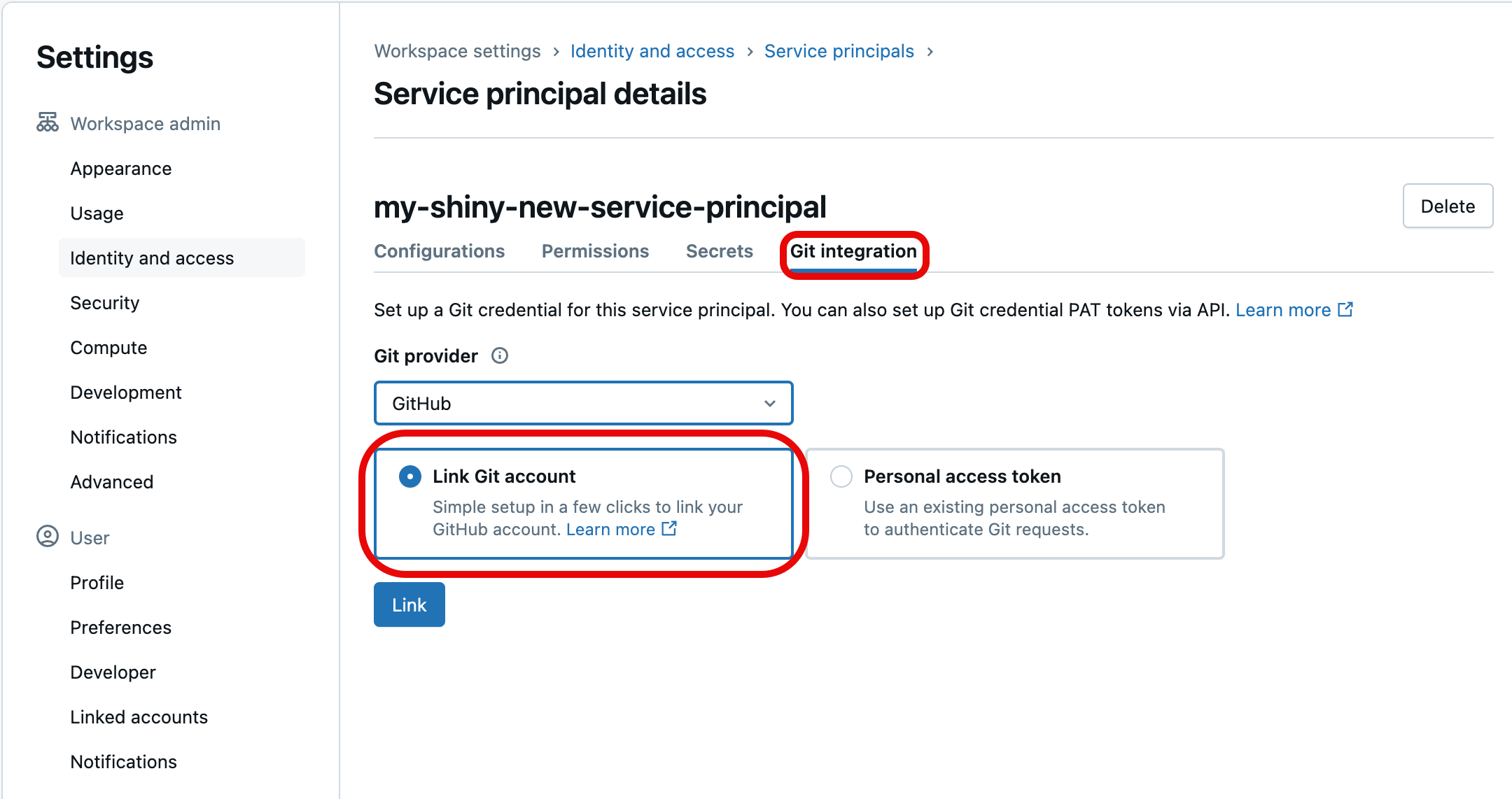
Se le pedirá que seleccione la cuenta de usuario de Git para vincularla. Elija la cuenta de usuario de Git que usará la entidad de servicio para acceder y seleccione Continuar. (Si no ve la cuenta de usuario que quiere usar, seleccione Usar una cuenta diferente).
En el cuadro de diálogo siguiente, seleccione Autorizar Databricks. Verá el mensaje "Vinculando cuenta..." brevemente, y, a continuación, los detalles actualizados de la entidad de servicio.
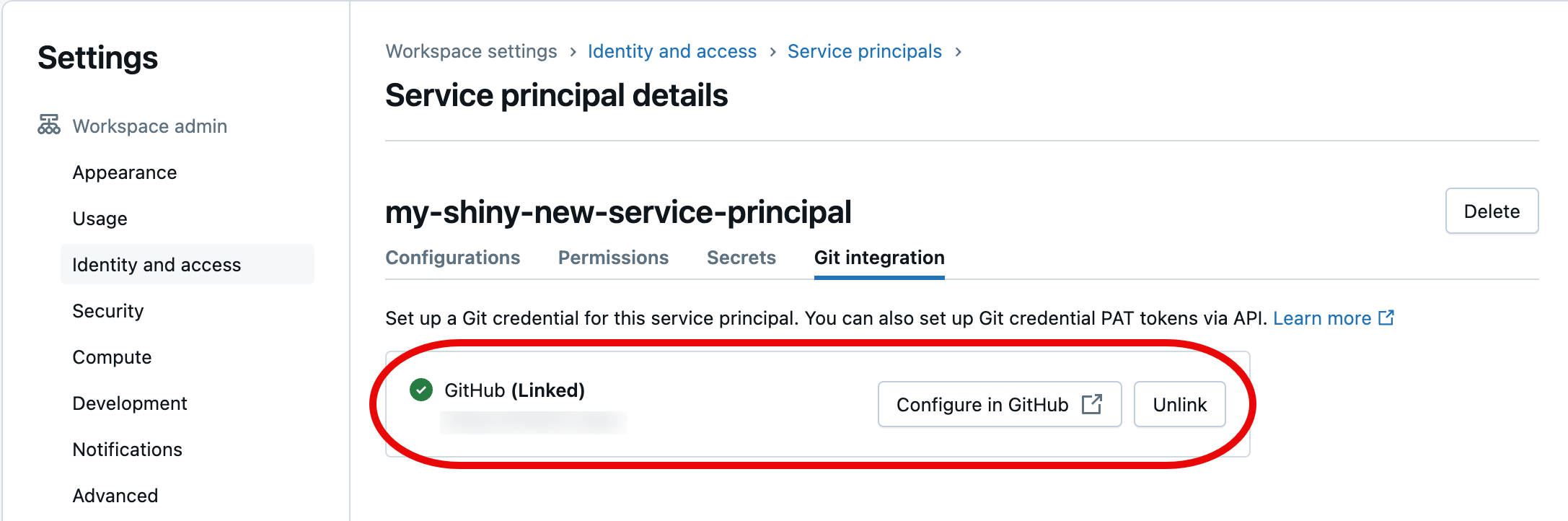
La entidad de servicio que elegiste aplicará ahora las credenciales de Git vinculadas al acceder a los recursos de la carpeta Git de tu área de trabajo de Azure Databricks como parte de tu automatización.
Integración de Terraform
También puede administrar carpetas de Git de Databricks en una configuración totalmente automatizada mediante Terraform y databricks_repo:
resource "databricks_repo" "this" {
url = "https://github.com/user/demo.git"
}
Para usar Terraform para agregar credenciales de Git a una entidad de servicio, agregue la siguiente configuración:
provider "databricks" {
# Configuration options
}
provider "databricks" {
alias = "sp"
host = "https://....cloud.databricks.com"
token = databricks_obo_token.this.token_value
}
resource "databricks_service_principal" "sp" {
display_name = "service_principal_name_here"
}
resource "databricks_obo_token" "this" {
application_id = databricks_service_principal.sp.application_id
comment = "PAT on behalf of ${databricks_service_principal.sp.display_name}"
lifetime_seconds = 3600
}
resource "databricks_git_credential" "sp" {
provider = databricks.sp
depends_on = [databricks_obo_token.this]
git_username = "myuser"
git_provider = "azureDevOpsServices"
personal_access_token = "sometoken"
}
Configuración de una canalización automatizada de CI/CD con carpetas de Git de Databricks
Esta es una automatización sencilla que se puede ejecutar como una acción de GitHub.
Requisitos
- Ha creado una carpeta de Git en un área de trabajo de Databricks en la que se realiza el seguimiento de la rama base en la que se combina.
- Tiene un paquete de Python que crea los artefactos que se van a colocar en una ubicación de DBFS. El código debe:
- Actualizar el repositorio asociado a la rama preferida (por ejemplo,
development) para que contenga las versiones más recientes de los cuadernos. - Compilar los artefactos y copiarlos en la ruta de acceso de la biblioteca.
- Reemplazar las últimas versiones de artefactos de compilación para evitar tener que actualizar manualmente las versiones de artefactos en el trabajo.
- Actualizar el repositorio asociado a la rama preferida (por ejemplo,
Creación de un flujo de trabajo automatizado de CI/CD
Configure secretos para que el código pueda acceder al área de trabajo de Databricks. Agregue los siguientes secretos al repositorio de Github:
- DEPLOYMENT_TARGET_URL: establézcalo en la dirección URL del área de trabajo. No incluya la
/?osubcadena. - DEPLOYMENT_TARGET_TOKEN: establézcalo en un token de acceso personal (PAT) de Databricks. Puede generar un PAT de Databricks siguiendo las instrucciones de autenticación de tokens de acceso personal de Azure Databricks.
- DEPLOYMENT_TARGET_URL: establézcalo en la dirección URL del área de trabajo. No incluya la
Vaya a la pestaña Acciones del repositorio de Git y haga clic en el botón Nuevo flujo de trabajo. En la parte superior de la página, seleccione Configurar un flujo de trabajo usted mismo y pegue este script:

# This is a basic automation workflow to help you get started with GitHub Actions. name: CI # Controls when the workflow will run on: # Triggers the workflow on push for main and dev branch push: paths-ignore: - .github branches: # Set your base branch name here - your-base-branch-name # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "deploy" deploy: # The type of runner that the job will run on runs-on: ubuntu-latest environment: development env: DATABRICKS_HOST: ${{ secrets.DEPLOYMENT_TARGET_URL }} DATABRICKS_TOKEN: ${{ secrets.DEPLOYMENT_TARGET_TOKEN }} REPO_PATH: /Workspace/Users/someone@example.com/workspace-builder DBFS_LIB_PATH: dbfs:/path/to/libraries/ LATEST_WHEEL_NAME: latest_wheel_name.whl # Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it - uses: actions/checkout@v3 - name: Setup Python uses: actions/setup-python@v3 with: # Version range or exact version of a Python version to use, using SemVer's version range syntax. python-version: 3.8 # Download the Databricks CLI. See https://github.com/databricks/setup-cli - uses: databricks/setup-cli@main - name: Install mods run: | pip install pytest setuptools wheel - name: Extract branch name shell: bash run: echo "##[set-output name=branch;]$(echo ${GITHUB_REF#refs/heads/})" id: extract_branch - name: Update Databricks Git folder run: | databricks repos update ${{env.REPO_PATH}} --branch "${{ steps.extract_branch.outputs.branch }}" - name: Build Wheel and send to Databricks DBFS workspace location run: | cd $GITHUB_WORKSPACE python setup.py bdist_wheel dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}} # there is only one wheel file; this line copies it with the original version number in file name and overwrites if that version of wheel exists; it does not affect the other files in the path dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}}${{env.LATEST_WHEEL_NAME}} # this line copies the wheel file and overwrites the latest version with itActualice los siguientes valores de variable de entorno por los suyos:
- DBFS_LIB_PATH: la ruta de acceso de DBFS a las bibliotecas (paquetes wheel) que usará en esta automatización, que comienza con
dbfs:. Por ejemplo:dbfs:/mnt/myproject/libraries. - REPO_PATH: la ruta de acceso del área de trabajo de Databricks a la carpeta Git donde se actualizarán los cuadernos.
- LATEST_WHEEL_NAME: nombre del archivo de rueda de Python compilado por última vez (
.whl). Esto se usa para evitar actualizar manualmente las versiones de wheel en los trabajos de Databricks. Por ejemplo,your_wheel-latest-py3-none-any.whl.
- DBFS_LIB_PATH: la ruta de acceso de DBFS a las bibliotecas (paquetes wheel) que usará en esta automatización, que comienza con
Seleccione Confirmar cambios... para confirmar el script como un flujo de trabajo de Acciones de GitHub. Una vez combinada la solicitud de cambios de este flujo de trabajo, vaya a la pestaña Acciones del repositorio de Git y confirme que las acciones se realizan correctamente.