Febrero de 2019
Estas características y mejoras de la plataforma Azure Databricks se publicaron en febrero de 2019.
Nota:
Las versiones se publican por fases. Es posible que su cuenta de Azure Databricks no se actualice hasta una semana después de la fecha de lanzamiento inicial.
Databricks Light está disponible con carácter general
26 de febrero - 5 de marzo de 2019: versión 2.92
Ya está disponible Databricks Light (también conocido como Data Engineering Light). Databricks Light es el empaquetado de Databricks del entorno de ejecución de código abierto de Apache Spark. Proporciona una opción de entorno de ejecución para los trabajos que no necesitan las ventajas de rendimiento avanzado, confiabilidad y escalado automático que proporciona Databricks Runtime. Puede seleccionar Databricks Light solo cuando se crea un clúster para ejecutar un trabajo de JAR, Python o spark-submit. No se puede seleccionar este entorno de ejecución para los clústeres en los que se ejecutan cargas de trabajo interactivas o de cuadernos. Consulte Databricks Light.
Versión preliminar pública del marco MLflow administrado en Azure Databricks
26 de febrero - 5 de marzo de 2019: versión 2.92
MLflow es una plataforma de código abierto para administrar el ciclo de vida completo del aprendizaje automático. Aborda tres funciones principales:
- Seguimiento de los experimentos para registrar y comparar parámetros y resultados.
- Administración e implementación de modelos de una gran variedad de bibliotecas de aprendizaje automático en una gran variedad de plataformas de inferencia y servicio de modelos.
- Empaquetado de código de aprendizaje automático en un formato reutilizable y reproducible para compartirlo con otros científicos de datos o transferirlo a producción.
Azure Databricks ahora proporciona una versión hospedada y totalmente administrada de MLflow integrada con características de seguridad empresarial, alta disponibilidad y otras características del área de trabajo de Azure Databricks, como la administración de experimentos y ejecuciones, y la captura de revisiones de cuadernos. MLflow en Azure Databricks ofrece una experiencia integrada para el seguimiento y la protección de las ejecuciones de entrenamiento de los modelos de Machine Learning, así como la ejecución de proyectos de aprendizaje automático. Al usar MLflow administrado en Azure Databricks, obtiene las ventajas de ambas plataformas, entre las que se incluyen:
- Áreas de trabajo: realice un seguimiento de los experimentos y los resultados, y organícelos en colaboración en áreas de trabajo de Azure Databricks, con un servidor de seguimiento de MLflow hospedado y una interfaz de usuario de experimentos integrada. Cuando usa MLflow en un cuaderno, Azure Databricks captura automáticamente las revisiones del cuaderno para que pueda reproducir el mismo código y se ejecute más adelante.
- Seguridad: aproveche un modelo de seguridad común para todo el ciclo de vida del aprendizaje automático mediante listas ACL.
- Trabajos: ejecute proyectos de MLflow como trabajos de Azure Databricks de forma remota y directa desde cuadernos de Azure Databricks.
Esta es una demostración de un flujo de trabajo de seguimiento en un área de trabajo de Azure Databricks:
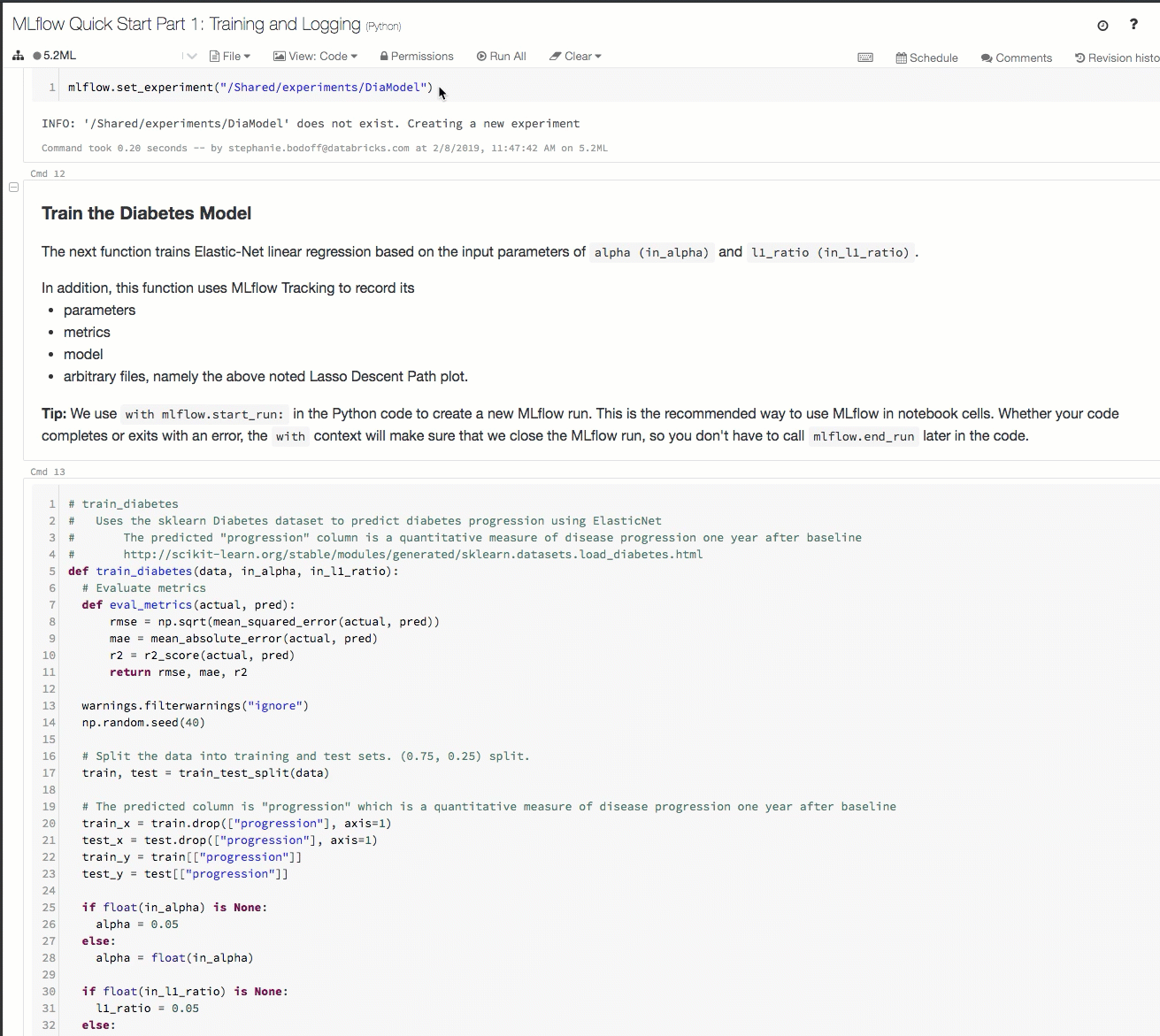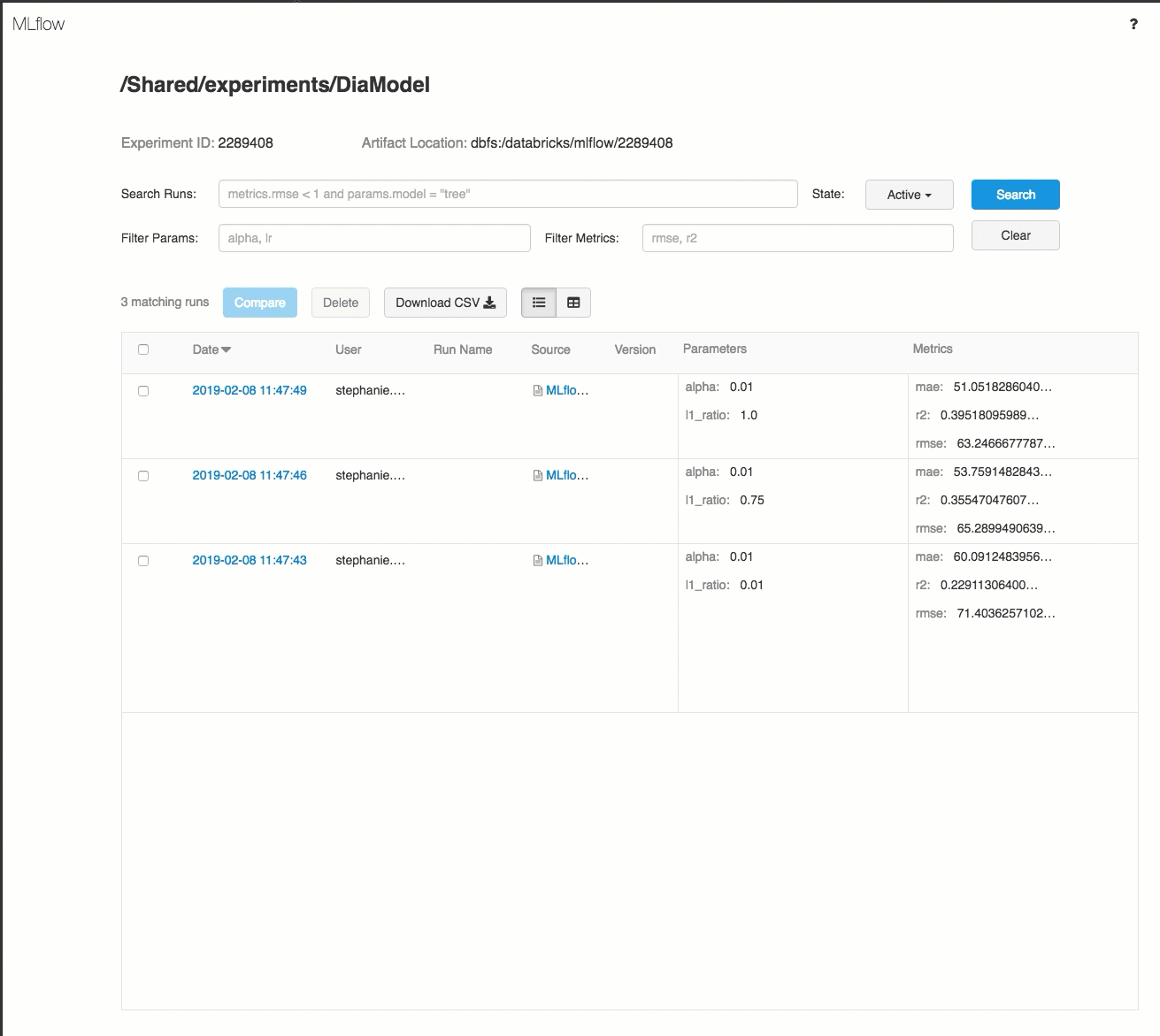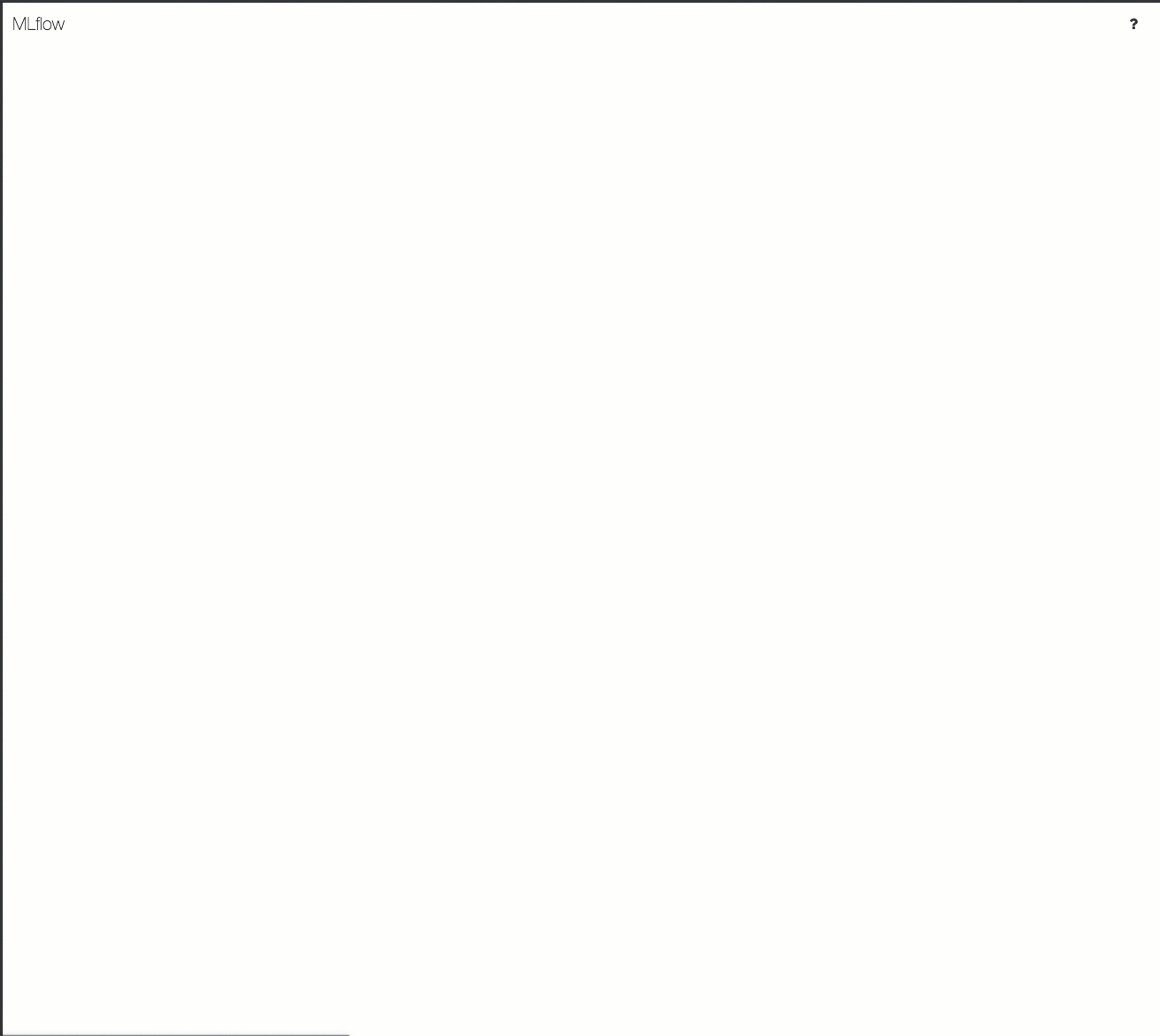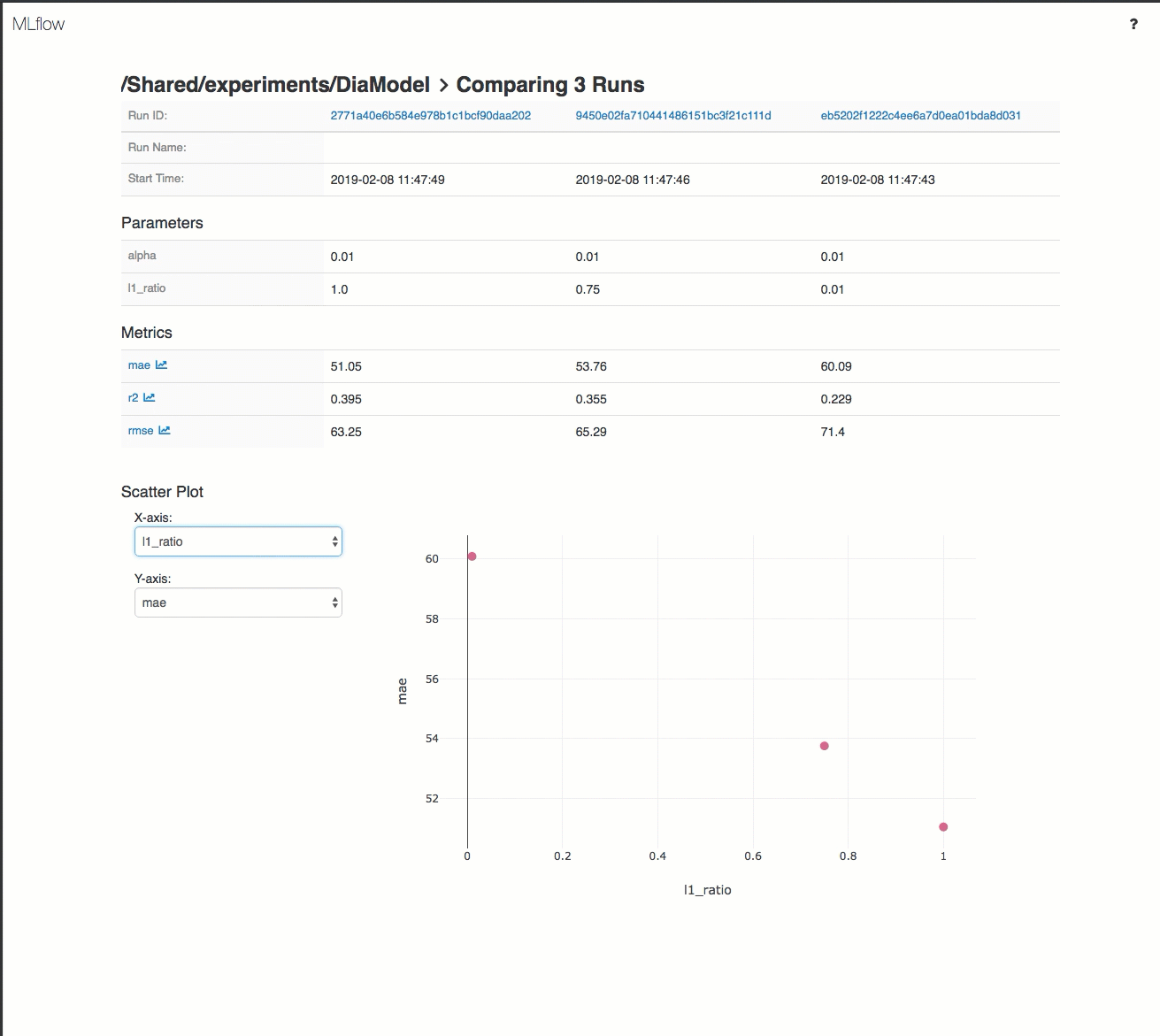
Para más información, consulte Seguimiento de las ejecuciones de aprendizaje automático y aprendizaje profundo y Ejecución de proyectos de MLflow en Azure Databricks.
El conector de Azure Data Lake Storage Gen2 está disponible con carácter general
15 de febrero de 2019
Azure Data Lake Storage Gen2 (ADLS Gen2), la solución de lago de datos de próxima generación para el análisis de macrodatos, ya está disponible con carácter general, al igual que el conector ADLS Gen2 para Azure Databricks. También nos complace anunciar que ADLS Gen2 admite Databricks Delta cuando se ejecutan clústeres en Databricks Runtime 5.2 y versiones posteriores.
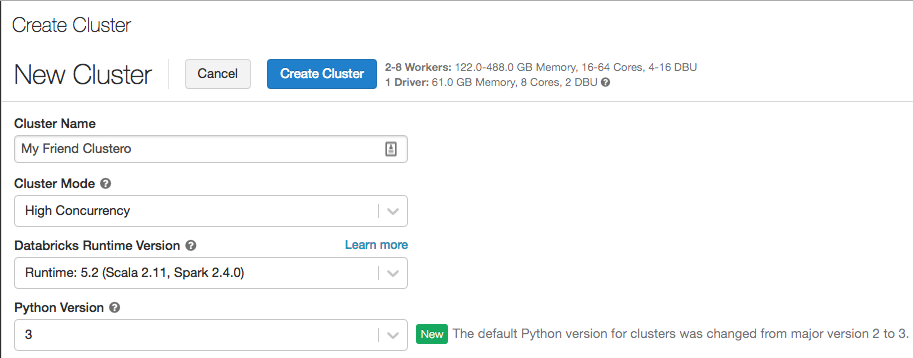
Python 3 ahora es el valor predeterminado cuando se crean clústeres
12-19 de febrero de 2019: versión 2.91
La versión predeterminada de Python para los clústeres creados con la interfaz de usuario ha cambiado de Python 2 a Python 3. El valor predeterminado para los clústeres creados con la API REST sigue siendo Python 2.
Los clústeres que ya existen no cambiarán sus versiones de Python. Pero si ha tenido el hábito de usar el valor predeterminado de Python 2 al crear nuevos clústeres, deberá empezar a prestar atención a la selección de la versión de Python.
Delta Lake está disponible con carácter general
1 de febrero de 2019
Ahora todo el mundo puede beneficiarse de la eficaz capa de almacenamiento transaccional y las lecturas superrápidas de Databricks Delta: a partir del 1 de febrero, Delta Lake está disponible con carácter general en todas las versiones admitidas de Databricks Runtime. Para obtener más información sobre Delta, consulte ¿Qué es Delta Lake?