Junio de 2018
Estas características y mejoras de la plataforma de Databricks se publicaron en junio de 2018.
Integración de RStudio
19 de junio de 2018: versión 2.74
Azure Databricks se integra ahora con RStudio Server, el conocido IDE para R. Con esta nueva y eficaz integración, puede hacer lo siguiente:
- Iniciar la interfaz de usuario de RStudio directamente desde Azure Databricks.
- Importar paquetes de SparkR y sparklyr dentro del IDE de RStudio.
- Acceder a grandes conjuntos de datos y explorarlos y transformarlos desde el IDE de RStudio mediante Apache Spark.
- Ejecutar y supervisar trabajos de Spark en un clúster de Azure Databricks.
- Administrar el código mediante el control de versiones.
- Usar las ediciones Open Source o Pro de RStudio Server en Azure Databricks.
La integración de RStudio requiere el plan Premium. Debe instalar la integración en un clúster de alta simultaneidad. Para obtener más información, consulte RStudio en Azure Databricks.
Purga del registro del clúster
19 de junio de 2018: versión 2.74
De manera predeterminada, los registros de clústeres se conservan durante 30 días. Ahora puede eliminarlos de forma permanente e inmediata si va a la pestaña "Workspace Storage" (Almacenamiento del área de trabajo) en la consola de administración. Consulta Purga del almacenamiento del área de trabajo.
Regiones nuevas
7 de junio de 2018
Azure Databricks ahora está disponible en las regiones siguientes:
- Este de Australia
- Sudeste de Australia
- Sur de Reino Unido
- Oeste de Reino Unido
Carpeta de la papelera
7 de junio de 2018: versión 2.73
Una nueva carpeta ![]() Trash contiene todos los cuadernos, las bibliotecas y las carpetas que ha eliminado. La carpeta "Trash" (Papelera) se purga automáticamente a los 30 días. Puede arrastrar un objeto eliminado de la carpeta "Trash" (Papelera) a otra carpeta para restaurarlo.
Trash contiene todos los cuadernos, las bibliotecas y las carpetas que ha eliminado. La carpeta "Trash" (Papelera) se purga automáticamente a los 30 días. Puede arrastrar un objeto eliminado de la carpeta "Trash" (Papelera) a otra carpeta para restaurarlo.
Para más información, consulte Eliminación de un objeto.
Periodo de retención de registro reducido
7 de junio de 2018: versión 2.73
Los registros de clústeres ahora se conservan durante 30 días. Solían conservarse indefinidamente.
Respuestas de la API en formato GZIP
7 de junio de 2018: versión 2.73
Las solicitudes enviadas con el encabezado Accept-Encoding: gzip devuelven respuestas en formato GZIP.
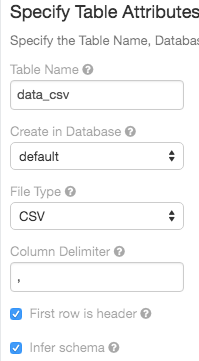
Interfaz de usuario de la importación de tablas
7 de junio de 2018: versión 2.73
La interfaz de usuario de creación de tablas ahora admite una opción para deducir el esquema de los archivos CSV: