Febrero de 2018
Las versiones se publican por fases. Es posible que su cuenta de Azure Databricks no se actualice hasta una semana después de la fecha de lanzamiento inicial.
El nuevo gráfico de líneas es compatible con datos de series temporales
27 de febrero- 6 de marzo de 2018: versión 2.66
Un nuevo gráfico de líneas es totalmente compatible con los datos de serie temporal y resuelve las limitaciones con nuestra opción de gráfico de líneas anterior. El gráfico de líneas antiguo está en desuso y se recomienda que los usuarios migren las visualizaciones que usan el gráfico de líneas antiguo al nuevo.
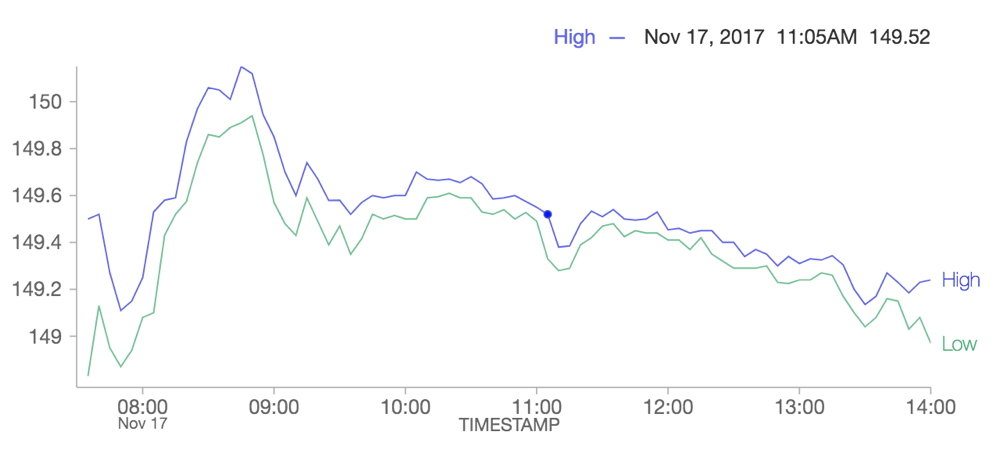
Consulte Migración de gráficos de líneas heredados para obtener más información.
Más mejoras en la visualización
27 de febrero- 6 de marzo de 2018: versión 2.66
Ahora puede ordenar columnas en la salida de la tabla y usar más de 10 elementos de leyenda en un gráfico.
Eliminación de ejecuciones de trabajos mediante la API de trabajo
27 de febrero- 6 de marzo de 2018: versión 2.66
Ahora puede usar Job API para eliminar ejecuciones de trabajos mediante el nuevo punto de conexión jobs/runs/delete.
Consulte Eliminación de ejecuciones para más información.
Actualización de la biblioteca de matemática KaTeX
27 de febrero- 6 de marzo de 2018: versión 2.66
La versión de KatTeX que usa Azure Databricks para la representación de ecuaciones matemáticas se actualizó de 0.5.1 a 0.9.0-beta1.
Esta actualización presenta cambios que pueden interrumpir las expresiones escritas en 0.5.1:
\xLongequales ahora\xlongequal(n.º 997)[text]colorLos colores HTML deben tener el formato correcto. (#827)\llapy\rlapahora representan el contenido en modo matemático. Use\mathllap(nuevo) y\mathrlap(nuevo) para proporcionar el comportamiento anterior.\colory\textcolorahora se comportan como lo hacen en KaTeX (#619)
Consulte las notas de la versión de KaTeX para más información.
Lanzamiento de CLI de Databricks: 0.5.0
27 de febrero de 2018: databricks-cli 0.5.0
La CLI de Databricks ahora admite comandos que tienen como destino las bibliotecas API.
La CLI admite ahora varios perfiles de conexión. Los perfiles de conexión se pueden utilizar para configurar la CLI para hablar con varias implementaciones de Azure Databricks.
Consulte la CLI de Databricks (heredada) para obtener más información.
Biblioteca de la API de DBUtils
Del 13 al 20 de febrero de 2018: versión 2.65
Azure Databricks proporciona una variedad de API de utilidad que le permiten trabajar fácilmente con DBFS, flujos de trabajo de cuadernos y widgets. La biblioteca dbutils-api acelera el desarrollo de aplicaciones al permitirle compilar y ejecutar pruebas unitarias localmente en estas API de utilidad antes de implementar la aplicación en un clúster de Azure Databricks.
Consulte la biblioteca de API de utilidades de Databricks para más información.
Filtrar solo por los trabajos propios
Del 13 al 20 de febrero de 2018: versión 2.65
Los nuevos filtros de la lista de trabajos permiten mostrar solo los trabajos que posee y solo los trabajos a los que tiene acceso.
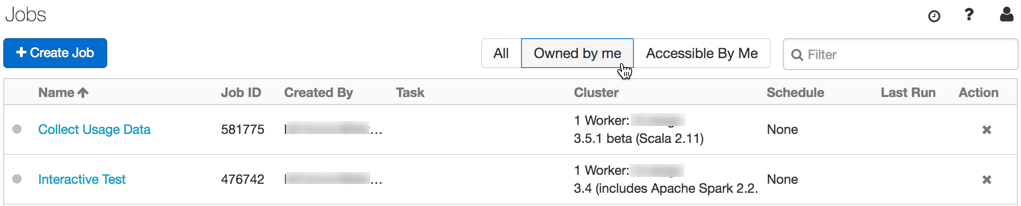
Consulte Introducción a la orquestación en Databricks para obtener más información.
Uso de spark-submit desde la página de creación de trabajos
Del 13 al 20 de febrero de 2018: versión 2.65
Ahora puede configurar los parámetros spark-submit desde la página Crear trabajo, así como a través de la API REST o la CLI.

Consulte Introducción a la orquestación en Databricks para obtener más información.
Selección de Python 3 desde la página de creación de clúster
Del 13 al 20 de febrero de 2018: versión 2.65
Ahora puede especificar la versión 2 o 3 de Python en la nueva lista desplegable de versiones de Python al crear un clúster. Si no realiza una selección, Python 2 es el valor predeterminado. También puede, como antes, crear clústeres de Python 3 mediante la API REST.
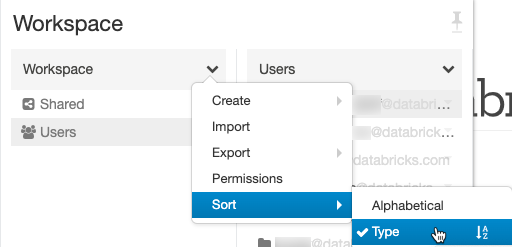
Mejoras de la interfaz de usuario del área de trabajo
Del 13 al 20 de febrero de 2018: versión 2.65
Hemos agregado la capacidad de ordenar archivos por tipo (carpetas, cuadernos, bibliotecas) en el explorador de archivos del área de trabajo y la carpeta principal siempre aparece en la parte superior de la lista Usuarios.
Función de autocompletar para comandos SQL y nombres de base de datos
Del 13 al 20 de febrero de 2018: versión 2.65
Las celdas SQL de los cuadernos ahora proporcionan la capacidad de autocompletar los comandos SQL y los nombres de base de datos.
Los grupos sin servidor ahora son compatibles con R
Del 1 al 8 de febrero de 2018: versión 2.64
Ahora puede usar R en grupos sin servidor.
XGBoost está disponible como paquete de Spark
Del 1 al 8 de febrero de 2018: versión 2.64
La biblioteca de integración de Spark de XGBoost ahora se puede instalar en Azure Databricks como un paquete de Spark desde la interfaz de usuario de biblioteca o la API REST. Anteriormente, XGBoost requería la instalación desde el origen a través de scripts init y, por tanto, un tiempo de inicio del clúster más largo. Consulte Uso de XGBoost en Azure Databricks para más información.
Control de acceso a tablas para SQL y Python (versión beta)
Del 1 al 8 de febrero de 2018: versión 2.64
El año pasado, introdujimos el control de acceso a objetos de datos para usuarios de SQL. Hoy nos complace anunciar la versión beta pública del control de acceso a tablas (ACL de tabla) para los usuarios SQL y Python. Con el control de acceso a tablas, puede restringir el acceso a objetos protegibles como tablas, bases de datos, vistas o funciones. También puede proporcionar un control de acceso específico (a filas y columnas que coincidan con condiciones específicas, por ejemplo) estableciendo permisos en vistas derivadas que contienen consultas arbitrarias.
Nota:
- Esta característica está en versión beta pública.
- Esta característica requiere Databricks Runtime 3.5 y posteriores.
Consulta Privilegios y objetos protegibles en el metastore de Hive (heredado) para obtener más información.