Brechas entre los trabajos de Spark
Se ven brechas en la escala de tiempo de los trabajos, como las siguiente:
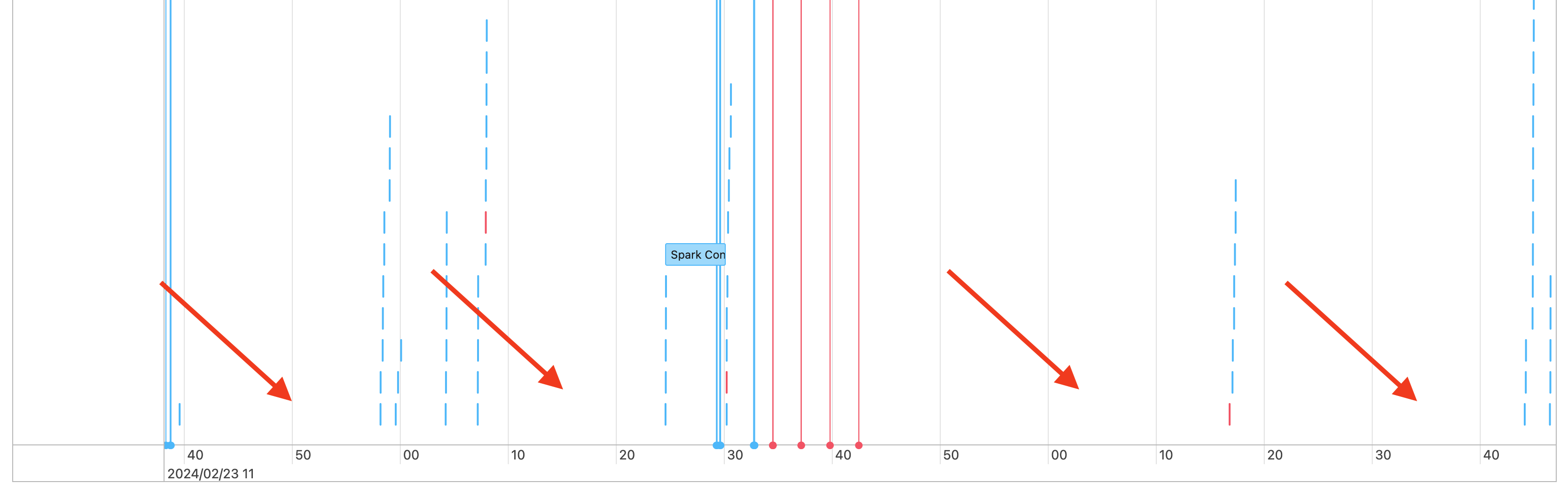
Existen varias razones por las que esto puede estar sucediendo. Si las brechas constituyen una gran proporción del tiempo invertido en la carga de trabajo, debe averiguar qué está causando estas brechas y si es un comportamiento esperado o no. Hay algunas situaciones que podrían estar ocurriendo durante las brechas:
- No hay trabajo que hacer
- El controlador está compilando un plan de ejecución complejo
- Ejecución de código que no es de Spark
- Se sobrecargó el controlador
- El clúster no funciona correctamente
No hay trabajo
En all-purpose compute, no tener ningún trabajo que hacer es la explicación más probable de las brechas. Dado que el clúster se está ejecutando y los usuarios están enviando consultas, se esperan brechas. Estas brechas son el tiempo entre los envíos de consultas.
Plan de ejecución complejo
Por ejemplo, si usa withColumn() en un bucle, se crea un plan muy caro para procesar. Las brechas podrían el tiempo que el controlador está pasando simplemente compilando y procesando el plan. Si este es el caso, intente simplificar el código. Use selectExpr() para combinar varias llamadas de withColumn() en una expresión o convierta el código en SQL. Puede insertar SQL en el código de Python mediante Python para manipular la consulta con funciones de cadena. Esto suele corregir este tipo de problema.
Ejecución de código que no es de Spark
El código de Spark se escribe en SQL o usa una API de Spark como PySpark. Cualquier ejecución de código que no sea de Spark se mostrará en la escala de tiempo como brechas. Por ejemplo, podría tener un bucle en Python que llama a funciones nativas de Python. Este código no se está ejecutando en Spark y puede aparecer como una brecha en la escala de tiempo. Si no está seguro de si el código está ejecutando Spark, intente ejecutarlo de forma interactiva en un cuaderno. Si el código usa Spark, verá trabajos de Spark en la celda:

También puede expandir la lista desplegable Trabajos de Spark en la celda para ver si los trabajos se están ejecutando activamente (en caso de que Spark esté inactivo). Si no usa Spark, no verá los trabajos de Spark en la celda, o verá que ninguno está activo. Si no puede ejecutar el código de forma interactiva, puede intentar iniciar sesión en el código y ver si puede hacer coincidir las brechas con las secciones del código por marca de tiempo, pero eso puede ser complicado.
Si ve brechas en la escala de tiempo causadas por la ejecución de código que no es de Spark, esto significa que los trabajadores están inactivos y probablemente desperdician dinero durante las brechas. Tal vez esto sea intencional e inevitable, pero si puede escribir este código para usar Spark, usará completamente el clúster. Comience con este tutorial para aprender a trabajar con Spark.
Se sobrecargó el controlador
Para determinar si el controlador está sobrecargado, debe examinar las métricas del clúster.
Si el clúster está en DBR 13.0 o posterior, haga clic en Métricas como se resalta en esta captura de pantalla:
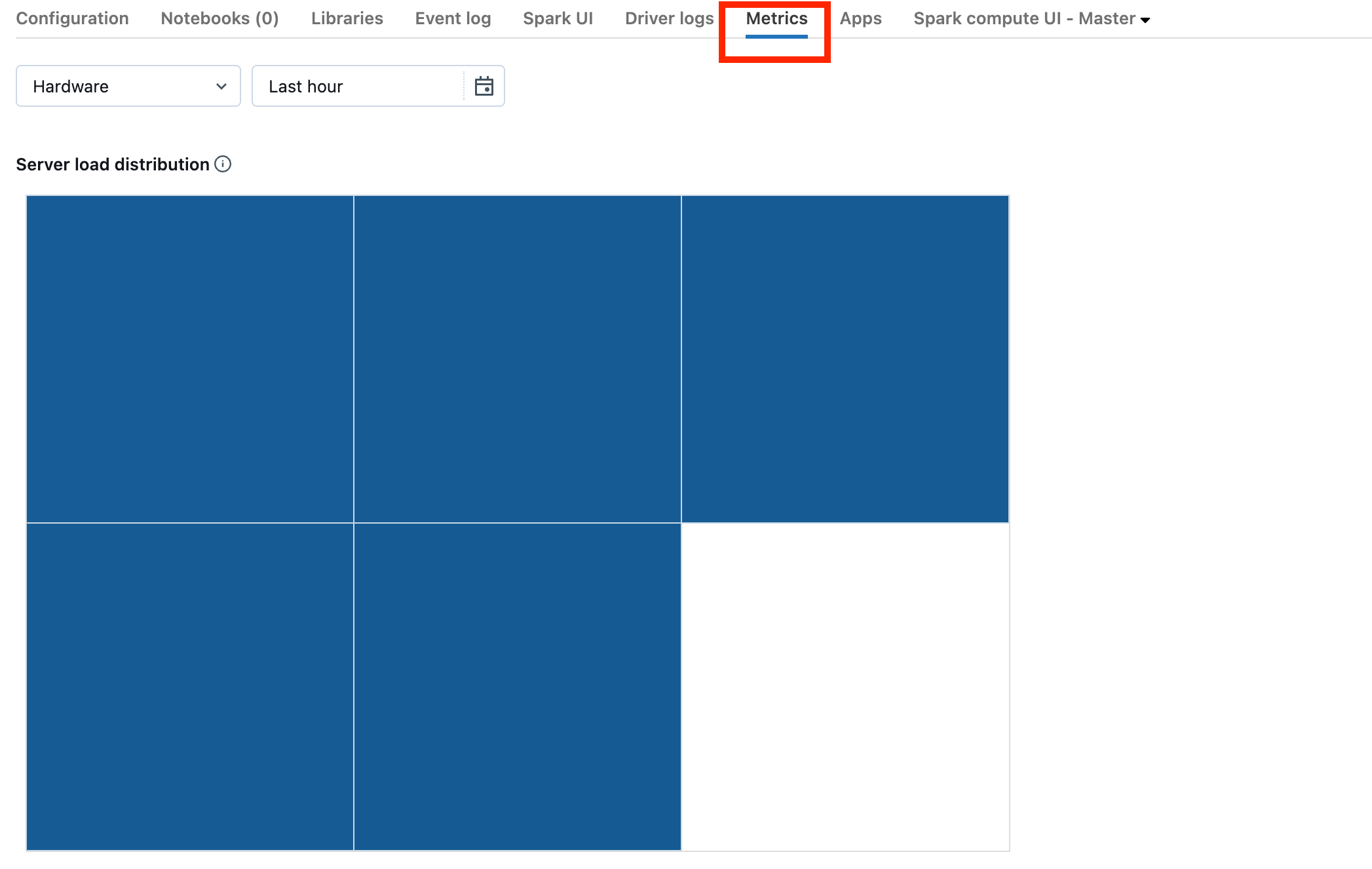
Observe la visualización de distribución de carga del servidor. Debe examinar si el controlador está muy cargado. Esta visualización tiene un bloque de color para cada máquina del clúster. Rojo significa muy cargado y azul significa que no está cargado en absoluto.
En la captura de pantalla anterior, se muestra un clúster básicamente inactivo. Si el controlador está sobrecargado, tendría un aspecto similar al siguiente:
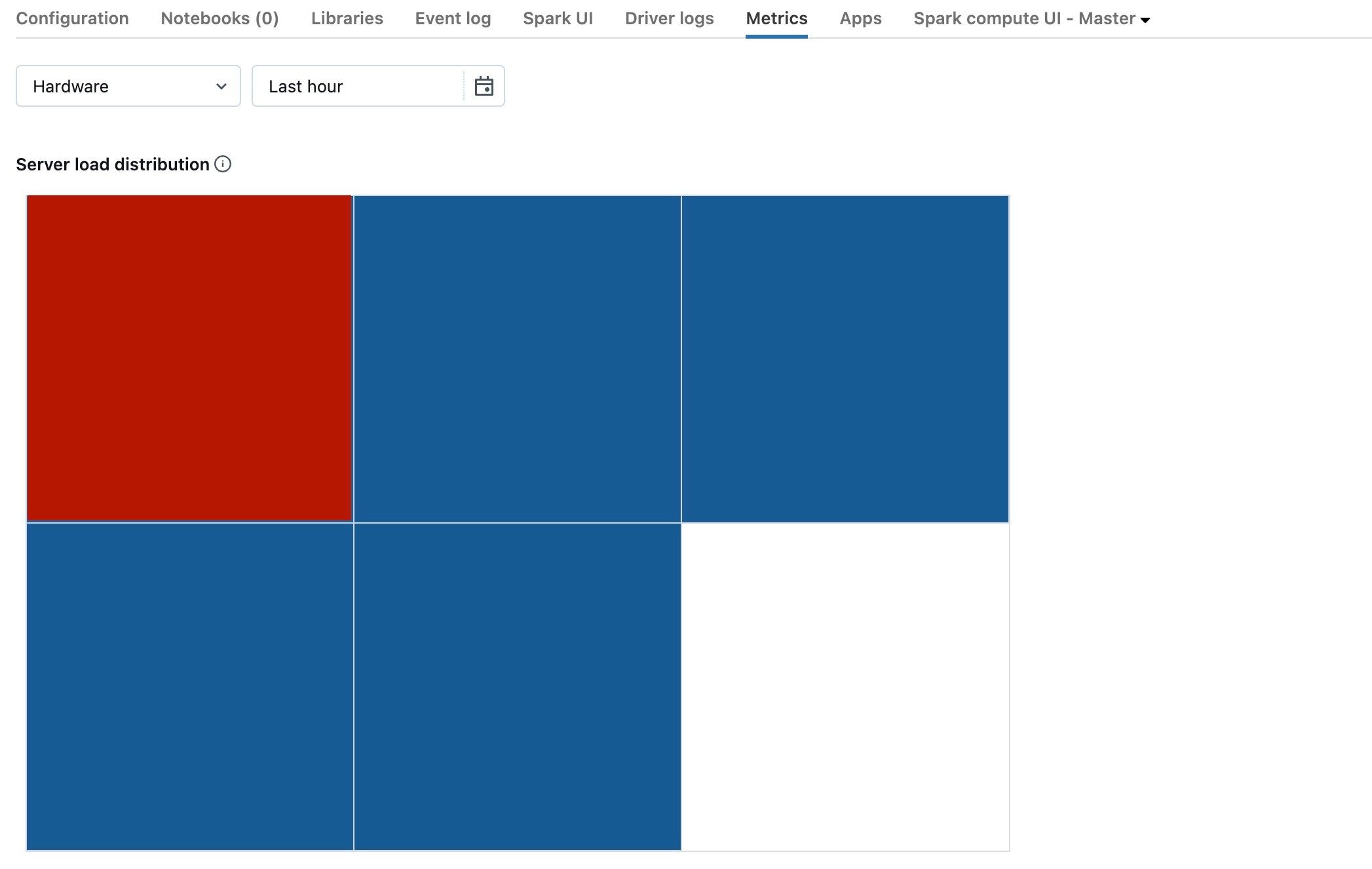
Podemos ver que un cuadrado es rojo, mientras que los otros son azules. Mueva el mouse sobre el cuadrado rojo para asegurarse de que el bloque rojo represente al controlador.
Para corregir un controlador sobrecargado, consulte Controlador de Spark sobrecargado.
El clúster no funciona correctamente
Es poco frecuente que haya clústeres que no funcionan correctamente, pero si este es el caso, puede ser difícil determinar lo que ha ocurrido. Tal vez deba simplemente reiniciar el clúster para ver si esto resuelve el problema. También puede examinar los registros para ver si hay algo sospechoso. La pestañaRegistro de eventos y Registros de controlador, resaltadas en la captura de pantalla siguiente, serán los lugares para examinar:
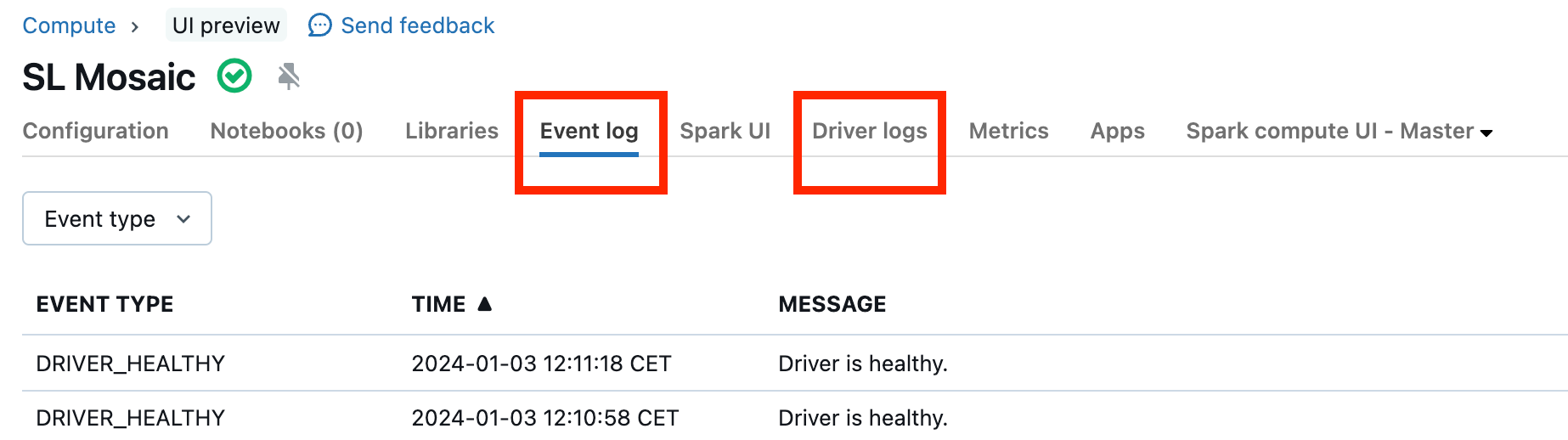
Es posible que desee habilitar Entrega de registros de clúster para acceder a los registros de los trabajadores. También puede cambiar el nivel de registro, pero es posible que tenga que ponerse en contacto con el equipo de la cuenta de Databricks para obtener ayuda.