Registro y carga de modelos de MLflow
Un modelo de MLflow es un formato estándar para empaquetar modelos de Machine Learning que se pueden usar en una variedad de herramientas de bajada; por ejemplo, inferencia por lotes en Apache Spark o servicio en tiempo real a través de una API REST. El formato define una convención que permite guardar un modelo en distintos tipos (python-function, pytorch, sklearn, entre otros), que se pueden entender mediante diferentes plataformas de servicios e inferencias de modelos.
Para aprender cómo registrar y puntuar un modelo de transmisión, consulte Cómo guardar y cargar un modelo de transmisión.
Registro y carga de modelos
Al registrar un modelo, MLflow registra los archivos requirements.txt y conda.yaml automáticamente. Puede usar estos archivos para volver a crear el entorno de desarrollo del modelo y volver a instalar las dependencias mediante virtualenv (recomendado) o conda.
Importante
Anaconda Inc. actualizó sus términos del servicio para los canales de anaconda.org. Según los nuevos términos del servicio, puede necesitar una licencia comercial si depende del empaquetado y la distribución de Anaconda. Consulte las preguntas más frecuentes sobre Anaconda Commercial Edition para obtener más información. El uso de cualquier canal de Anaconda se rige por sus términos del servicio.
Los modelos de MLflow registrados antes de la versión 1.18 (Databricks Runtime 8.3 ML o versiones anteriores) se registraron de forma predeterminada con el canal de Conda defaults (https://repo.anaconda.com/pkgs/) como dependencia. Debido a este cambio de licencia, Databricks ha detenido el uso del canal defaults para los modelos registrados mediante MLflow v1.18 y versiones posteriores. El canal predeterminado registrado es ahora conda-forge, que apunta a la comunidad administrada https://conda-forge.org/.
Si registró un modelo antes de MLflow v1.18 sin excluir el canal defaults del entorno de Conda para el modelo, es posible que ese modelo tenga una dependencia en el defaults canal que no haya previsto.
Para confirmar manualmente si un modelo tiene esta dependencia, puede examinar el valor channel en el archivo conda.yaml que se empaqueta con el modelo registrado. Por ejemplo, un modelo conda.yaml con una dependencia de canal defaults puede tener este aspecto:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Dado que Databricks no puede determinar si el uso del repositorio de Anaconda para interactuar con los modelos está permitido en su relación con Anaconda, Databricks no obliga a sus clientes a realizar ningún cambio. Si el uso del repositorio de Anaconda.com mediante el uso de Databricks está permitido en los términos de Anaconda, no es necesario realizar ninguna acción.
Si desea cambiar el canal usado en el entorno de un modelo, puede volver a registrar el modelo en el registro de modelos con un nuevo conda.yaml. Para ello, especifique el canal en el parámetro conda_env de log_model().
Para más información sobre la log_model() API, consulte la documentación de MLflow para el tipo de modelo con el que está trabajando, por ejemplo, log_model para scikit-learn.
Para más información sobre los archivos conda.yaml, consulte la documentación de MLflow.
Comandos de API
Para registrar un modelo en el servidor de seguimiento de MLflow, utilice mlflow.<model-type>.log_model(model, ...).
Para cargar un modelo anteriormente registrado para inferencia o desarrollo posterior, utilice mlflow.<model-type>.load_model(modelpath), donde modelpath es uno de los elementos siguientes:
- una ruta de acceso relativa de ejecución (como
runs:/{run_id}/{model-path}) - una ruta de acceso de volúmenes del catálogo de Unity (por ejemplo
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}, ) - una ruta de almacenamiento de artefactos administrados por MLflow a partir de
dbfs:/databricks/mlflow-tracking/ - una ruta de acceso de modelo registrado (como
models:/{model_name}/{model_stage})
Para una lista completa de las opciones para cargar modelos de MLflow, consulte la sección de referencia de artefactos en la documentación de MLflow.
En el caso de los modelos de MLflow para Python, una opción adicional es usar mlflow.pyfunc.load_model() para cargar el modelo como una función genérica de Python.
Puede usar el fragmento de código siguiente para cargar el modelo y puntuar los puntos de datos.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
Como alternativa, puede exportar el modelo como UDF de Apache Spark a fin de utilizarlo para la puntuación en un clúster de Spark, ya sea como trabajo por lotes o como un trabajo de Spark Streaming en tiempo real.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Dependencias del modelo de registro
Para cargar con precisión un modelo, debe asegurarse de que las dependencias del modelo se carguen con las versiones correctas en el entorno del cuaderno. En Databricks Runtime 10.5 ML y versiones posteriores, MLflow le advierte si se detecta una discrepancia entre el entorno actual y las dependencias del modelo.
La funcionalidad adicional para simplificar la restauración de dependencias del modelo se incluye en Databricks Runtime 11.0 ML y versiones posteriores. En Databricks Runtime 11.0 ML o posteriores, para los pyfunctipos de modelos, puede llamar a mlflow.pyfunc.get_model_dependencies para recuperar y descargar las dependencias del modelo. Esta función devuelve una ruta de acceso al archivo de dependencias que puede instalar mediante %pip install <file-path>. Al cargar un modelo como una UDF de PySpark, especifique env_manager="virtualenv" en la llamada a mlflow.pyfunc.spark_udf. Esto restaura las dependencias del modelo en el contexto de la UDF de PySpark y no afecta al entorno externo.
También puede usar esta funcionalidad en Databricks Runtime 10.5 o posterior mediante la instalación manual de MLflow versión 1.25.0 o posterior:
%pip install "mlflow>=1.25.0"
Para obtener más información sobre cómo registrar artefactos y dependencias del modelo (Python y no Python), consulte Dependencias del modelo de registro.
Obtenga información sobre cómo registrar las dependencias del modelo y los artefactos personalizados para el modelo:
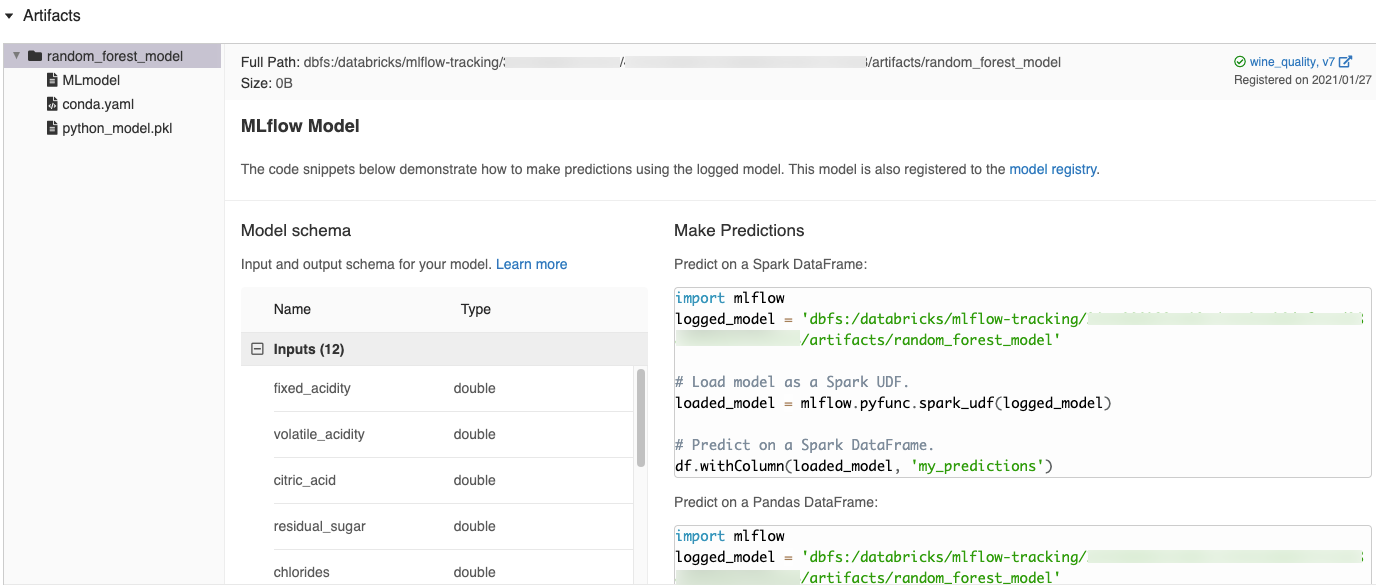
Fragmentos de código generados automáticamente en la interfaz de usuario de MLflow
Al registrar un modelo en un cuaderno de Azure Databricks, Azure Databricks genera automáticamente fragmentos de código que puede copiar y utilizar para cargar y ejecutar el modelo. Para ver estos fragmentos de código:
- Vaya a la pantalla Ejecuciones para la ejecución que generó el modelo. (Consulte Visualización del experimento de cuaderno para saber cómo ver la pantalla Ejecuciones).
- Desplácese a la sección Artefactos.
- Haga clic en el modelo registrado. Se abre un panel a la derecha en la que se muestra código que puede usar para cargar el modelo registrado y hacer predicciones e DataFrames de Pandas o Spark.
Ejemplos
Para ejemplos de cómo registrar modelos, consulte los que aparecen en Seguimiento de ejemplos de ejecuciones de entrenamiento de aprendizaje automático.
Registro de modelos en el Registro de modelos
Puede registrar modelos en el Registro de modelos de MLflow, un almacén de modelos centralizado que proporciona una interfaz de usuario y un conjunto de API para administrar el ciclo de vida completo de los modelos de MLflow. Para ver instrucciones sobre cómo usar el Registro de modelos para administrar los modelos en el catálogo de Unity de Databricks, consulte Administrar el ciclo de vida del modelo en el catálogo de Unity. Para usar el Registro de modelos de área de trabajo, consulte Administración del ciclo de vida del modelo mediante el Registro de modelos de área de trabajo (heredado).
Para registrar un modelo mediante la API, utilice mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}").
Guardar modelos en volúmenes del catálogo de Unity
Para guardar localmente un modelo, utilice mlflow.<model-type>.save_model(model, modelpath). modelpath debe ser una ruta de acceso de volúmenes del catálogo de Unity. Por ejemplo, si usa una ubicación dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models de volúmenes del catálogo de Unity para almacenar el trabajo del proyecto, debe usar la ruta /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_modelsde acceso del modelo :
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
En el caso de los modelos de MLlib, utilice canalizaciones de aprendizaje automático.
Descarga de artefactos del modelo
Puede descargar los artefactos de modelo registrado (como métricas, trazados y archivos del modelo) de un modelo registrado con varias API.
Ejemplo de API de Python:
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
model_uri = MlflowClient.get_model_version_download_uri(model_name, model_version)
ModelsArtifactRepository(model_uri).download_artifacts(artifact_path="")
Ejemplo de API de Java:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
Ejemplo de comando de la CLI:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Implementación de modelos para servicios en línea
Nota
Antes de implementar el modelo, resulta beneficioso asegurarse de que el modelo puede ser puesto en servicio. Consulte la documentación de MLflow sobre cómo puede usar mlflow.models.predict para validar modelos antes de la implementación.
Use Mosaic AI Model Serving para hospedar modelos de aprendizaje automático registrados en el registro de modelos del Unity Catalog como puntos de acceso REST. Estos puntos de conexión se actualizan automáticamente en función de la disponibilidad de las versiones del modelo.