Seguimiento de MLflow para agentes
Importante
Esta característica está en versión preliminar pública.
En este artículo se describe el seguimiento de MLflow en Databricks y cómo usarlo para agregar observabilidad a las aplicaciones de inteligencia artificial generativa.
¿En qué consiste el seguimiento de MLflow?
Seguimiento de MLflow captura información detallada sobre la ejecución de aplicaciones de IA generativa. El seguimiento registra entradas, salidas y metadatos asociados a cada paso intermedio de una solicitud para que pueda identificar el origen de errores y el comportamiento inesperado. Por ejemplo, si el modelo presenta alucinaciones, puede inspeccionar rápidamente cada paso que llevó a la alucinación.
El seguimiento de MLflow se integra con las herramientas y la infraestructura de Databricks, lo que permite almacenar y mostrar seguimientos en cuadernos de Databricks o la interfaz de usuario del experimento de MLflow.
¿Por qué conviene usar el seguimiento de MLflow?
El seguimiento de MLflow proporciona varias ventajas:
- Revise una visualización de seguimiento interactiva y use la herramienta de investigación para diagnosticar problemas.
- Compruebe que las plantillas de aviso y los límites de protección produzcan resultados razonables.
- Analice la latencia de diferentes marcos, modelos y tamaños de fragmento.
- Calcule los costos de la aplicación mediante la medición del uso de tokens en diferentes modelos.
- Establezca conjuntos de datos "maestros" de referencia para evaluar el rendimiento de distintas versiones.
- Almacene seguimientos de los puntos de conexión del modelo de producción para depurar problemas y realizar revisiones y evaluaciones sin conexión.
Adición de seguimientos a su agente
El seguimiento de MLflow admite tres métodos para agregar seguimientos a las aplicaciones de IA generativas. Para ver detalles de referencia de API, consulte la documentación de MLflow.
| API | Caso de uso recomendado | Descripción |
|---|---|---|
| Registro automático de MLflow | Desarrollo con bibliotecas integradas de GenAI | El registro automático registra automáticamente los seguimientos de marcos de código abierto compatibles, como LangChain, LlamaIndex y OpenAI. |
| API fluidas | Agente personalizado con Pyfunc | API de código bajo para agregar seguimientos sin preocuparse por administrar la estructura de árbol del seguimiento. MLflow determina automáticamente las relaciones de intervalo primario-secundario adecuadas mediante la pila de Python. |
| API de cliente de MLflow | Casos de uso avanzados, como multiproceso | MLflowClient proporciona API granulares y seguras para hilos en casos de uso avanzados. Debes administrar manualmente la relación de elementos primarios y secundarios de intervalos. Esto te proporciona un mejor control sobre el ciclo de vida de seguimiento, especialmente para los casos de uso multiproceso. |
Instalación de seguimiento de MLflow
El Seguimiento de MLflow está disponible en las versiones 2.13.0 y posteriores de MLflow, que están preinstaladas en <DBR< 15.4 LTS ML y versiones posteriores. Si es necesario, instale MLflow con el código siguiente:
%pip install mlflow>=2.13.0 -qqqU
%restart_python
Como alternativa, puede instalar la versión más reciente de databricks-agents, que incluye una versión de MLflow compatible:
%pip install databricks-agents
Uso del registro automático para agregar seguimientos a los agentes
Si la biblioteca de GenAI admite el seguimiento, como LangChain o OpenAI, habilite el registro automático agregando mlflow.<library>.autolog() al código. Por ejemplo:
mlflow.langchain.autolog()
Nota:
A partir de Databricks Runtime 15.4 LTS ML, el seguimiento de MLflow está habilitado de forma predeterminada en cuadernos. Para deshabilitar el seguimiento, por ejemplo, con LangChain, puede ejecutar mlflow.langchain.autolog(log_traces=False) en el cuaderno.
MLflow admite bibliotecas adicionales para el registro automático de seguimiento. Para obtener una lista completa de las bibliotecas integradas, consulte la documentación de Seguimiento de MLflow.
Uso de las API de Fluent para agregar manualmente seguimientos al agente
Las API de Fluent en MLflow crean automáticamente jerarquías de seguimiento en función del flujo de ejecución del código.
Decoración de la función
Usa el decorador @mlflow.trace a fin de crear un intervalo para el ámbito de la función decorada.
El objeto de intervalo de MLflow organiza los pasos de seguimiento. Spans captura información sobre operaciones o pasos individuales, como llamadas API o consultas de almacén de vectores, dentro de un flujo de trabajo.
El intervalo se inicia cuando se invoca la función y finaliza cuando devuelve. MLflow registra la entrada y salida de la función y las excepciones generadas a partir de la función.
Por ejemplo, el código siguiente crea un intervalo denominado my_function que captura los argumentos de entrada x y y y la salida.
@mlflow.trace(name="agent", span_type="TYPE", attributes={"key": "value"})
def my_function(x, y):
return x + y
Uso del administrador de contextos de seguimiento
Si desea crear un intervalo para un bloque arbitrario de código, no solo una función, puede usar mlflow.start_span() como administrador de contextos que encapsula el bloque de código. El intervalo se inicia cuando se entra al contexto y finaliza cuando se sale del contexto. Las entradas y salidas de intervalo deben proporcionarse manualmente mediante los métodos de establecimiento del objeto de intervalo que se obtiene del administrador de contextos.
with mlflow.start_span("my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
Ajuste de una función externa
Para rastrear las funciones de biblioteca externa, envuelva la función con mlflow.trace.
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
traced_accuracy_score = mlflow.trace(accuracy_score)
traced_accuracy_score(y_true, y_pred)
Ejemplo de Fluent API
En el ejemplo siguiente se muestra cómo usar las API de Fluent mlflow.trace y mlflow.start_span para realizar un seguimiento del quickstart-agent:
import mlflow
from mlflow.deployments import get_deploy_client
class QAChain(mlflow.pyfunc.PythonModel):
def __init__(self):
self.client = get_deploy_client("databricks")
@mlflow.trace(name="quickstart-agent")
def predict(self, model_input, system_prompt, params):
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": model_input[0]["query"]
}
]
traced_predict = mlflow.trace(self.client.predict)
output = traced_predict(
endpoint=params["model_name"],
inputs={
"temperature": params["temperature"],
"max_tokens": params["max_tokens"],
"messages": messages,
},
)
with mlflow.start_span(name="_final_answer") as span:
# Initiate another span generation
span.set_inputs({"query": model_input[0]["query"]})
answer = output["choices"][0]["message"]["content"]
span.set_outputs({"generated_text": answer})
# Attributes computed at runtime can be set using the set_attributes() method.
span.set_attributes({
"model_name": params["model_name"],
"prompt_tokens": output["usage"]["prompt_tokens"],
"completion_tokens": output["usage"]["completion_tokens"],
"total_tokens": output["usage"]["total_tokens"]
})
return answer
Después de agregar la traza, ejecute la función. A continuación se continúa el ejemplo con la función predict() en la sección anterior. Las trazas se muestran automáticamente al ejecutar el método de invocación, predict().
SYSTEM_PROMPT = """
You are an assistant for Databricks users. You answer Python, coding, SQL, data engineering, spark, data science, DW and platform, API, or infrastructure administration questions related to Databricks. If the question is unrelated to one of these topics, kindly decline to answer. If you don't know the answer, say that you don't know; don't try to make up an answer. Keep the answer as concise as possible. Use the following pieces of context to answer the question at the end:
"""
model = QAChain()
prediction = model.predict(
[
{"query": "What is in MLflow 5.0"},
],
SYSTEM_PROMPT,
{
# Using Databricks Foundation Model for easier testing, feel free to replace it.
"model_name": "databricks-dbrx-instruct",
"temperature": 0.1,
"max_tokens": 1000,
}
)
API de cliente de MLflow
MlflowClient expone API granulares seguras para subprocesos para iniciar y finalizar seguimientos, administrar intervalos y establecer campos de intervalo. Proporciona control completo del ciclo de vida y la estructura de la traza. Estas API son útiles cuando las API de Fluent no son suficientes para tus requisitos, como aplicaciones multiproceso y devoluciones de llamada.
A continuación se indican los pasos para crear un seguimiento completo mediante el cliente de MLflow.
Cree una instancia de MLflowClient mediante
client = MlflowClient().Inicie un seguimiento mediante el método
client.start_trace(). Esto inicia el contexto de seguimiento, inicia un intervalo raíz absoluto y devuelve un objeto de intervalo raíz. Este método debe ejecutarse antes de la API destart_span().- Establezca los atributos, las entradas y las salidas del seguimiento en
client.start_trace().
Nota:
No hay un equivalente al método
start_trace()en las API de Fluent. Esto se debe a que las API de Fluent inicializan automáticamente el contexto de seguimiento y determinan si es el intervalo raíz basado en el estado administrado.- Establezca los atributos, las entradas y las salidas del seguimiento en
La API start_trace() devuelve un intervalo. Obtenga el ID de la solicitud, que es un identificador único del seguimiento y también se denomina
trace_id, así como el ID del tramo devuelto utilizandospan.request_idyspan.span_id.Inicie un intervalo secundario mediante
client.start_span(request_id, parent_id=span_id)para establecer los atributos, las entradas y las salidas del intervalo.- Este método requiere
request_idyparent_idasociar el intervalo con la posición correcta en la jerarquía de seguimiento. Devuelve otro objeto span.
- Este método requiere
Finaliza el intervalo secundario llamando a
client.end_span(request_id, span_id).Repite los pasos 3 a 5 para los intervalos secundarios que quieras crear.
Después de la finalización de todos los intervalos secundarios, llama a
client.end_trace(request_id)para cerrar el seguimiento y registrarlo.
from mlflow.client import MlflowClient
mlflow_client = MlflowClient()
root_span = mlflow_client.start_trace(
name="simple-rag-agent",
inputs={
"query": "Demo",
"model_name": "DBRX",
"temperature": 0,
"max_tokens": 200
}
)
request_id = root_span.request_id
# Retrieve documents that are similar to the query
similarity_search_input = dict(query_text="demo", num_results=3)
span_ss = mlflow_client.start_span(
"search",
# Specify request_id and parent_id to create the span at the right position in the trace
request_id=request_id,
parent_id=root_span.span_id,
inputs=similarity_search_input
)
retrieved = ["Test Result"]
# You must explicitly end the span
mlflow_client.end_span(request_id, span_id=span_ss.span_id, outputs=retrieved)
root_span.end_trace(request_id, outputs={"output": retrieved})
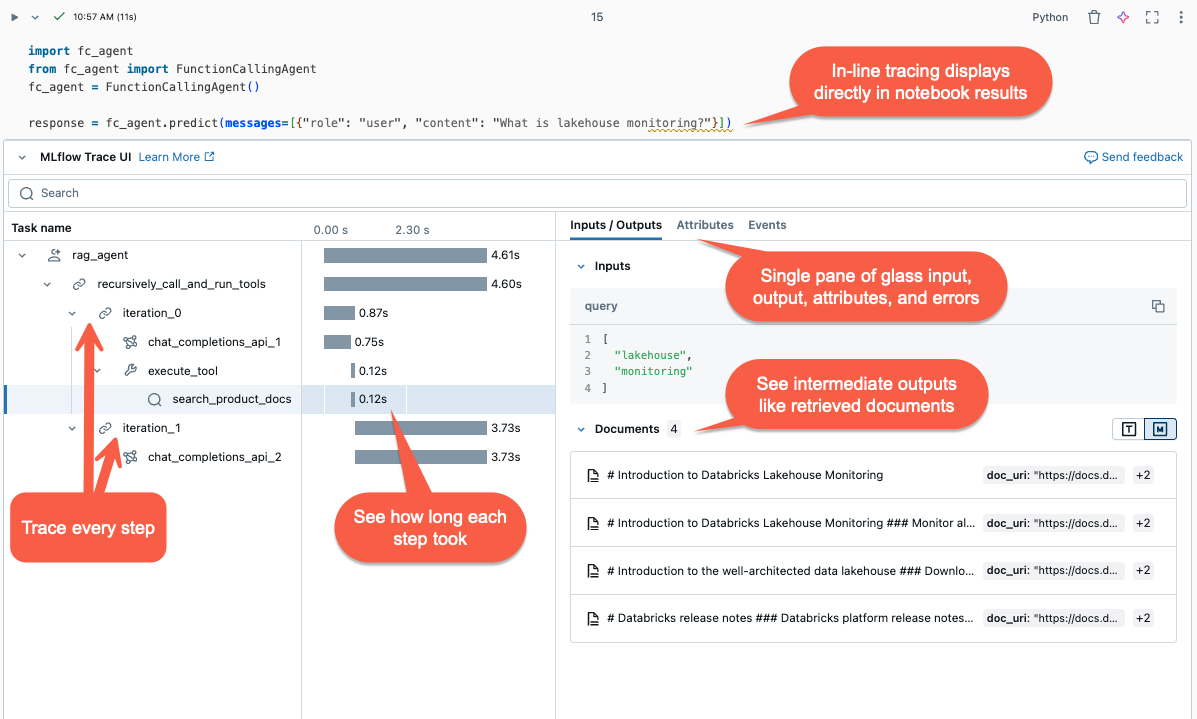
Revisar seguimientos
Para revisar los seguimientos después de ejecutar el agente, use una de las siguientes opciones:
- La visualización de seguimiento se representa en línea en la salida de la celda.
- Los seguimientos se registran en el experimento de MLflow. Puedes revisar y buscar la lista completa de seguimientos históricos en la pestaña Seguimientos de la página Experimento. Cuando el agente se ejecuta bajo una ejecución activa de MLflow, los seguimientos aparecen en la página Ejecutar.
- Recupere los seguimientos mediante programación con la API search_traces().
Uso del seguimiento de MLflow en producción
El seguimiento de MLflow también se integra con Mosaic AI Model Serving, lo que le permite depurar problemas de forma eficaz, supervisar el rendimiento y crear un conjunto de datos dorado para la evaluación sin conexión. Cuando el seguimiento de MLflow está habilitado para el punto de conexión de servicio, los seguimientos se registran en una tabla de inferencia debajo de la columna response.
Puede visualizar los seguimientos que se registran en las tablas de inferencia consultando la tabla y mostrando los resultados en un cuaderno. Usa display(<the request logs table>) en tu cuaderno y selecciona las filas individuales de los registros que deseas visualizar.
Para habilitar el seguimiento de MLflow para el punto de conexión de servicio, debe establecer la variable de entorno ENABLE_MLFLOW_TRACING en la configuración del punto de conexión en True. Para obtener información sobre cómo implementar un punto de conexión con variables de entorno personalizado, consulte Adición de variables de entorno de texto sin formato. Si ha implementado el agente mediante la API de deploy(), los seguimientos se registran automáticamente en una tabla de inferencia. Consulte Implementación de un agente para una aplicación de IA generativa.
Nota:
La escritura de seguimientos en una tabla de inferencia se realiza de forma asíncrona, por lo que no agrega la misma sobrecarga que en el entorno del cuaderno durante el desarrollo. Sin embargo, podría introducir cierta sobrecarga en la velocidad de respuesta del punto de conexión, especialmente cuando el tamaño de seguimiento de cada solicitud de inferencia es grande. Databricks no garantiza ningún acuerdo de nivel de servicio (SLA) para el impacto real de latencia en el punto de conexión del modelo, ya que depende en gran medida del entorno y de la implementación del modelo. Databricks recomienda probar el rendimiento del punto de conexión y obtener información sobre la sobrecarga de seguimiento antes de realizar la implementación en una aplicación de producción.
En la siguiente tabla se proporciona una indicación aproximada del impacto en la latencia de inferencia para diferentes tamaños de seguimiento.
| Tamaño de seguimiento por solicitud | Impacto en la latencia (ms) |
|---|---|
| ~10 KB | ~ 1 ms |
| ~ 1 MB | 50 ~ 100 ms |
| 10 MB | 150 ms ~ |
Limitaciones
- El seguimiento de MLflow está disponible en cuadernos de Databricks, trabajos de cuadernos y servicio de modelos.
Es posible que el registro automático de LangChain no admita todas las API de predicción de LangChain. Para obtener la lista completa de las API admitidas, consulte la Documentación de MLflow.