Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se muestra cómo implementar modelos mediante APIs de modelos fundacionales con un rendimiento aprovisionado. Databricks recomienda la capacidad de procesamiento aprovisionada para cargas de trabajo de producción y ofrece inferencia optimizada para los modelos fundamentales con garantías de rendimiento.
¿Qué es el rendimiento aprovisionado?
El rendimiento aprovisionado hace referencia al número de tokens que se pueden enviar a un punto de conexión al mismo tiempo. Los puntos de conexión de rendimiento aprovisionado son puntos de conexión dedicados que se configuran en términos de un rango de tokens por segundo que puede enviar al punto de conexión.
Para obtener más información, consulte los siguientes recursos:
- ¿Qué significan los rangos de tokens por segundo en el rendimiento aprovisionado?
- Realice sus propias pruebas comparativas de endpoints de LLM
Consulte Rendimiento aprovisionado para obtener una lista de arquitecturas de modelos admitidas para los puntos finales de rendimiento aprovisionado.
Requisitos
Consulte Requisitos. Para implementar modelos de base optimizados, consulte Implementación de modelos de base optimizados.
[Recomendado] Implementación de modelos básicos desde el catálogo de Unity
Importante
Esta característica está en versión preliminar pública.
Databricks recomienda usar los modelos de base que están preinstalados en el catálogo de Unity. Puede encontrar estos modelos en el catálogo system en el esquema ai (system.ai).
Para implementar un modelo de base:
- Vaya a
system.aien el Explorador de catálogos. - Haga clic en el nombre del modelo que se va a implementar.
- En la página del modelo, haga clic en el botón Servir este modelo.
- Aparece la página Crear punto de conexión de servicio. Consulte Creación del punto de conexión de rendimiento aprovisionado mediante la interfaz de usuario.
Nota:
Para implementar un modelo de Meta Llama desde system.ai en el catálogo de Unity, debe elegir la versión correspondiente de Instruct. Las versiones base de los modelos Meta Llama no se admiten para la implementación desde system.ai en el catálogo de Unity. Consulte Límites de rendimiento aprovisionados.
Implementación de modelos de base desde Databricks Marketplace
Como alternativa, puede instalar modelos de base en Unity Catalog desde Databricks Marketplace.
Puede buscar una familia de modelos y, desde la página del modelo, puede seleccionar Obtener acceso y proporcionar credenciales de inicio de sesión para instalar el modelo en el catálogo de Unity.
Una vez que el modelo esté instalado en Unity Catalog, puede crear un punto de conexión de servicio de modelos mediante la interfaz de usuario de Serving.
Implementación de modelos básicos optimizados
Si no puede usar los modelos en el esquema system.ai o instalar modelos desde el Marketplace de Databricks, puede implementar un modelo base ajustado si lo registra en el Catálogo de Unity. En esta sección y en las secciones siguientes se muestra cómo configurar el código para registrar un modelo de MLflow en Unity Catalog y crear el punto de conexión de rendimiento aprovisionado mediante la interfaz de usuario o la API REST.
Consulte Límites de rendimiento aprovisionado para conocer los modelos de Meta Llama 3.1, 3.2 y 3.3 afinados y su disponibilidad regional.
Requisitos
- La implementación de modelos de base optimizados solo es compatible con MLflow 2.11 o superior. Databricks Runtime 15.0 ML y versiones posteriores instalan previamente la versión de MLflow compatible.
- Databricks recomienda usar modelos en el Catálogo de Unity para una carga y descarga más rápidas de modelos grandes.
Definir el catálogo, el esquema y el nombre del modelo
Para implementar un modelo de base optimizado, defina el catálogo de Unity de destino, el esquema y el nombre del modelo que prefiera.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Registra tu modelo
Para habilitar el rendimiento aprovisionado para el punto de conexión del modelo, es necesario registrar el modelo mediante el tipo transformers de MLflow y especificar el argumento task con la interfaz de tipo de modelo adecuada de las siguientes opciones:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
Estos argumentos especifican la firma de API que se usa para el punto de conexión de servicio del modelo. Consulte la documentación de MLflow para obtener más información sobre estas tareas y los esquemas de entrada y salida correspondientes.
A continuación se muestra un ejemplo de cómo registrar un modelo de lenguaje de finalización de texto registrado mediante MLflow:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
Nota:
Si usa MLflow anterior a la versión 2.12, debe especificar la tarea en el parámetro metadata de la misma función mlflow.transformer.log_model() en lugar de eso.
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
El rendimiento aprovisionado también admite los modelos de incrustación de GTE base y grande. A continuación se muestra un ejemplo de cómo registrar el modelo Alibaba-NLP/gte-large-en-v1.5 para que se pueda servir con el rendimiento aprovisionado:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
Una vez que el modelo se haya registrado en Unity Catalog, continúe en Creación del punto de conexión de rendimiento aprovisionado mediante la interfaz de usuario para crear un punto de conexión de servicio de modelo con rendimiento aprovisionado.
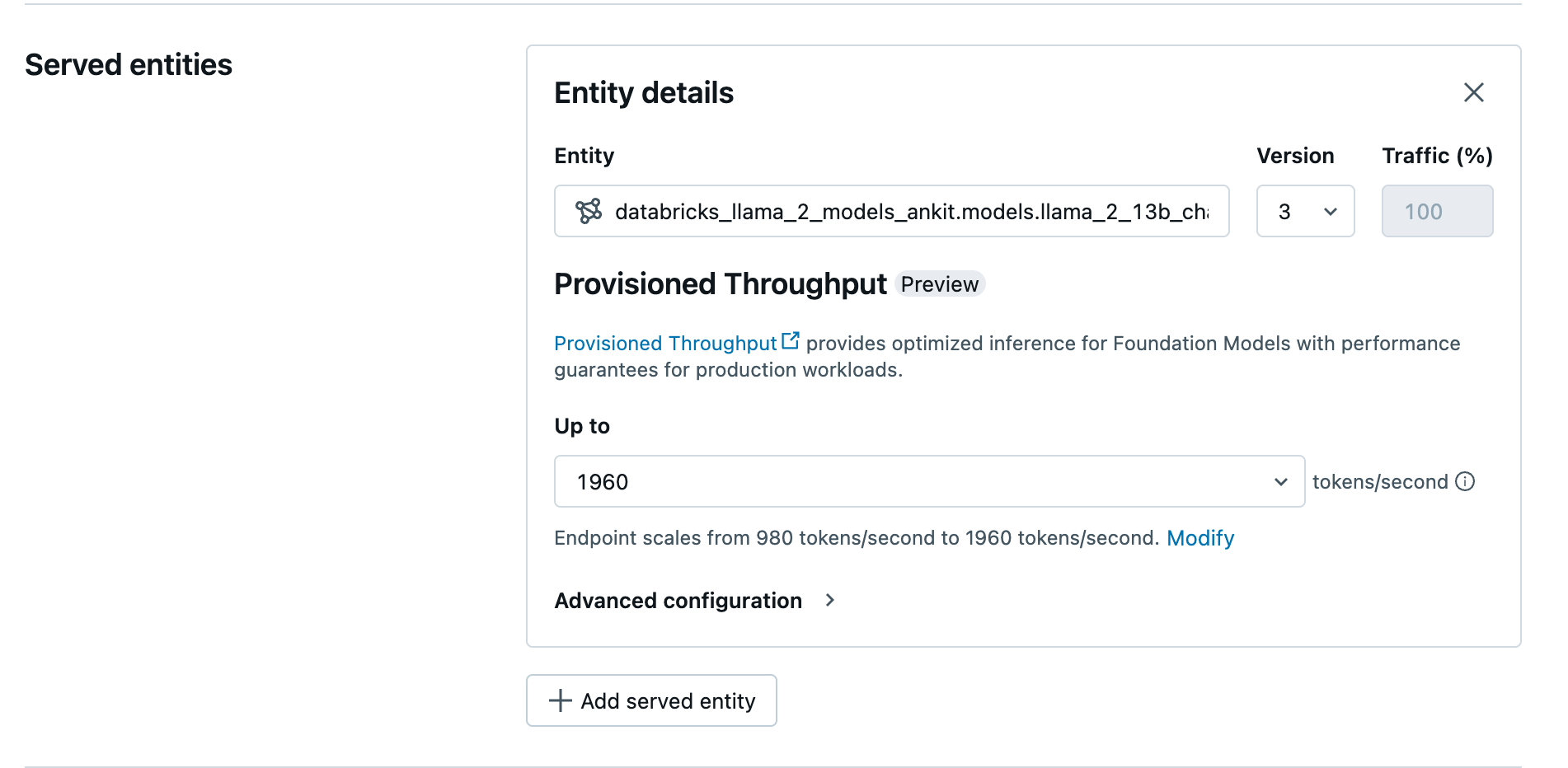
Creación del punto de conexión de rendimiento aprovisionado mediante la interfaz de usuario
Después de que el modelo registrado esté en Unity Catalog, cree un punto de conexión de servicio con rendimiento aprovisionado con los pasos siguientes:
- Vaya a la interfaz de usuario de servicio en el área de trabajo.
- Seleccione Crear punto de conexión de servicio.
- En el campo de la entidad , seleccione su modelo del Catálogo de Unity. Si los modelos son válidos, la interfaz de usuario de la entidad atendida muestra la pantalla de Rendimiento aprovisionado.
- En la lista desplegable Hasta, puede configurar el rendimiento máximo de tokens por segundo para el punto de conexión.
- Los puntos de conexión con rendimiento aprovisionados se escalan automáticamente, por lo que puede seleccionar Modificar para ver los tokens mínimos por segundo hasta los que el punto de conexión puede reducirse verticalmente.
Creación del punto de conexión con rendimiento aprovisionado mediante la API de REST
Para implementar su modelo en modo de rendimiento aprovisionado mediante la API REST, debe especificar los campos min_provisioned_throughput y max_provisioned_throughput en su solicitud. Si prefiere Python, también puede crear un punto de conexión mediante el SDK de implementación de MLflow.
Para identificar el intervalo adecuado de rendimiento aprovisionado para el modelo, consulte Obtención del rendimiento aprovisionado en incrementos.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Probabilidad logarítmica para las tareas de finalización de chat
Para las tareas de finalización del chat, puede usar el parámetro logprobs para proporcionar la probabilidad logarítmica de un token que se muestrea como parte del proceso de generación de modelos de lenguaje extenso. Puede usar logprobs para una variedad de escenarios, como la clasificación, la evaluación de la incertidumbre del modelo y la ejecución de métricas de evaluación. Vea la tarea de chat de para obtener más información sobre parámetros.
Obtener rendimiento aprovisionado en incrementos
El rendimiento aprovisionado está disponible en incrementos de tokens por segundo con incrementos específicos que varían según el modelo. Para identificar el intervalo adecuado para sus necesidades, Databricks recomienda usar la API de información de optimización de modelos dentro de la plataforma.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
A continuación se muestra una respuesta de ejemplo de la API:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Ejemplos de cuadernos
En los cuadernos siguientes se muestran ejemplos de cómo crear una API de Foundation Model de rendimiento aprovisionado:
Servicio de rendimiento aprovisionado para el cuaderno de modelos GTE
Servicio de rendimiento aprovisionado para el cuaderno de modelos BGE
En el siguiente cuaderno se muestra cómo puede descargar y registrar el modelo DeepSeek R1 distilled Llama en Unity Catalog, para que pueda implementarlo utilizando un punto de conexión de rendimiento aprovisionado a través de las API de Foundation Model.
Servicio de rendimiento provisionado para el cuaderno del modelo DeepSeek R1 distilled Llama
Limitaciones
- Es posible que se produzca un error en la implementación del modelo debido a problemas de capacidad de GPU, lo que produce un tiempo de espera durante la creación o actualización del punto de conexión. Póngase en contacto con el equipo de la cuenta de Databricks para ayudar a resolverlo.
- El escalado automático de las API de Foundation Models es más lento que el servicio de modelos de CPU. Databricks recomienda sobreaprovisionar para evitar tiempos de espera en las solicitudes.
- GTE v1.5 (inglés) no genera incrustaciones normalizadas.