Procese características a petición utilizando funciones definidas por el usuario de Python
En este artículo se describe cómo crear y usar características a petición en Azure Databricks.
Para usar características a petición, el área de trabajo debe estar habilitada para Catálogo de Unity y debe usar Databricks Runtime 13.3 LTS ML o superior.
¿Qué son las características a petición?
“A petición” se refiere a las características cuyos valores no se conocen con antelación, pero se calculan en el momento de la inferencia. En Azure Databricks, se usa funciones definidas por el usuario (UDF) de Python para especificar cómo calcular las características a petición. Estas funciones se rigen por el catálogo de Unity y se pueden descubrir mediante Explorador de catálogos.
Requisitos
- Para usar una función definida por el usuario (UDF) para crear un conjunto de entrenamiento o para crear un punto de conexión de Feature Serving, debe tener el privilegio
USE CATALOGen el catálogosystemde Unity Catalog.
Flujo de trabajo
Para calcular las características a petición, especifique una función definida por el usuario (UDF) de Python que describe cómo calcular los valores de características.
- Durante el entrenamiento, proporcione esta función y sus enlaces de entrada en el
feature_lookupsparámetro de la APIcreate_training_set. - Debe registrar el modelo entrenado mediante el método del Almacén de características
log_model. Esto garantiza que el modelo evalúa automáticamente las características a petición cuando se usa para la inferencia. - Para la puntuación por lotes, la API de
score_batchcalcula y devuelve automáticamente todos los valores de características, incluidas las características a petición. - Al servir un modelo con Mosaic AI Model Serving, el modelo usa automáticamente la UDF de Python para calcular las características a petición de cada solicitud de puntuación.
Crear una UDF de Python
Puede crear una UDF de Python en un cuaderno o en Databricks SQL.
Por ejemplo, al ejecutar el código siguiente en una celda de cuaderno, se crea el example_feature de UDF de Python en el catálogo main y el esquema default.
%sql
CREATE FUNCTION main.default.example_feature(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
Después de ejecutar el código, puede navegar por el espacio de nombres de tres niveles en Explorador de catálogos para ver la definición de la función:
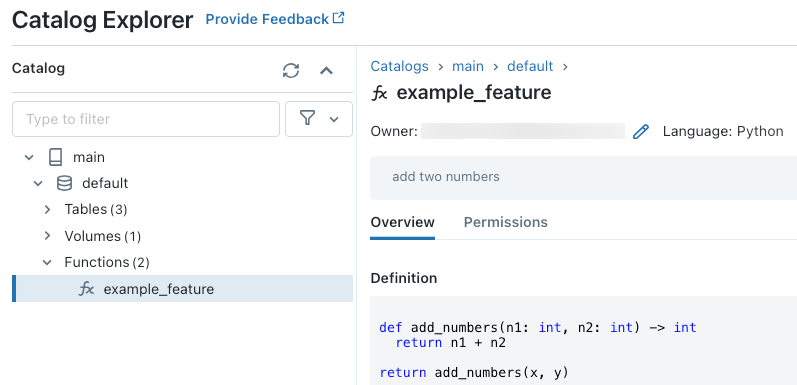
Para obtener más información sobre cómo crear UDF de Python, consulte Registrar una UDF de Python en Unity Catalog y el manual del lenguaje SQL.
Cómo controlar los valores de características que faltan
Cuando una UDF de Python depende del resultado de una FeatureLookup, el valor devuelto si no se encuentra la clave de búsqueda solicitada depende del entorno. Cuando se usa score_batch, el valor devuelto es None. Cuando se usa el servicio en línea, el valor devuelto es float("nan").
El siguiente código es un ejemplo de cómo controlar ambos casos.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
Entrenamiento de un modelo mediante características a petición
Para entrenar el modelo, use un FeatureFunction, que se pasa a la API de create_training_set en el parámetro feature_lookups.
En el código de ejemplo siguiente se usa el UDF de Python main.default.example_feature que se definió en la sección anterior.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Registrar el modelo y registrarlo en el catálogo de Unity
Los modelos empaquetados con metadatos de características se pueden registrar en el catálogo de Unity. Las tablas de características que se usan para crear el modelo deben almacenarse en el Catálogo de Unity.
Para asegurarse de que el modelo evalúa automáticamente las características a petición cuando se usa para la inferencia, debe establecer el URI del Registro y, a continuación, registrar el modelo, como se indica a continuación:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
Si la UDF de Python que define las características a petición importa los paquetes de Python, debe especificar estos paquetes mediante el argumento extra_pip_requirements. Por ejemplo:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Limitación
Las características a petición pueden generar todos los tipos de datos de compatibles con feature Store excepto MapType y ArrayType.
Ejemplos de cuaderno: características a petición
En el cuaderno siguiente se muestra un ejemplo de cómo entrenar y puntuar un modelo que usa una característica a petición.
Cuaderno básico de demostración de características a petición
En el siguiente cuaderno se muestra un ejemplo de un modelo de recomendación de restaurantes. La ubicación del restaurante se busca desde una tabla en línea de Databricks. La ubicación actual del usuario se envía como parte de la solicitud de puntuación. El modelo usa una característica a petición para calcular la distancia en tiempo real del usuario al restaurante. A continuación, esa distancia se usa como entrada para el modelo.