Databricks Runtime para Machine Learning
Databricks Runtime para Machine Learning (Databricks Runtime ML) automatiza la creación de un clúster con una infraestructura de aprendizaje profundo y aprendizaje automático precompilada, incluidas las bibliotecas de ML y DL más comunes. Puede ver la lista completa de bibliotecas de cada versión de Databricks Runtime ML en las notas de la versión.
Nota:
Para acceder a los datos del Catálogo de Unity para flujos de trabajo de aprendizaje automático, el modo de acceso del clúster debe ser un solo usuario (asignado). Los clústeres compartidos no son compatibles con Databricks Runtime para Machine Learning. Además, Databricks Runtime ML no se admite en clústeres de TableACLs o clústeres con spark.databricks.pyspark.enableProcessIsolation config establecido en true.
Creación de un clúster mediante Databricks Runtime ML
Al crear un clúster, seleccione una versión de Databricks Runtime ML en el menú desplegable de la versión de Databricks Runtime. Están disponibles los entornos de ejecución de ML habilitados tanto para CPU como para GPU.
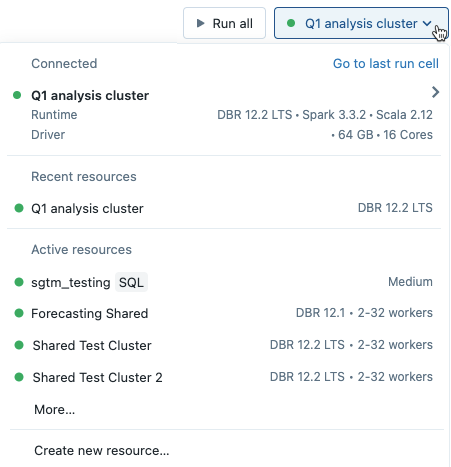
Si selecciona un clúster en el menú desplegable del cuaderno, la versión de Databricks Runtime aparece a la derecha del nombre del clúster:
Si selecciona un entorno de ejecución de ML habilitado para GPU, se le pedirá que seleccione un tipo de controlador y un tipo de trabajo compatibles. Los tipos de instancia incompatibles aparecen atenuados en el menú desplegable. Los tipos de instancia habilitados para GPU se muestran en la etiqueta Acelerada por GPU. Para obtener información sobre cómo crear clústeres de GPU de Azure Databricks, consulte Proceso habilitado para GPU. Databricks Runtime ML incluye controladores de hardware para GPU y bibliotecas de NVIDIA, como CUDA.
Photon y Databricks Runtime ML
Al crear un clúster de CPU que ejecute Databricks Runtime 15.2 ML o superior, puede optar por habilitar Photon. Photon mejora el rendimiento de las aplicaciones que usan Spark SQL, Spark DataFrames, ingeniería de características, GraphFrames y xgboost4j. No se espera que mejore el rendimiento de las aplicaciones mediante RDD de Spark, UDF de Pandas y lenguajes que no sean JVM, como Python. Por lo tanto, los paquetes de Python como XGBoost, PyTorch y TensorFlow no verán una mejora con Photon.
Las API de RDD de Spark y MLlib de Spark tienen una compatibilidad limitada con Photon. Al procesar grandes conjuntos de datos mediante RDD de Spark o MLlib de Spark, podría experimentar problemas de memoria de Spark. Consulte Problemas de memoria de Spark.
Bibliotecas incluidas en Databricks Runtime ML
Databricks Runtime ML incluye varias bibliotecas populares de ML. Las bibliotecas se actualizan con cada versión para incluir nuevas características y correcciones.
Databricks ha designado un subconjunto de las bibliotecas admitidas como bibliotecas de nivel superior. Para estas bibliotecas, Databricks proporciona una cadencia de actualización más rápida a las versiones de paquete más recientes con cada versión del entorno de ejecución (sin conflictos de dependencia). Databricks también proporciona compatibilidad avanzada, pruebas y optimizaciones insertadas para bibliotecas de nivel superior.
Para obtener una lista completa de las bibliotecas de primer nivel y de otras bibliotecas proporcionadas, consulte las notas de la versión para Databricks Runtime ML.
Puede instalar bibliotecas con el fin de crear un entorno personalizado para el cuaderno o clúster.
- Para que una biblioteca esté disponible para todos los cuadernos que se ejecutan en un clúster, cree una biblioteca de clústeres. Puede instalar scripts de inicialización para instalar bibliotecas en clústeres después de la creación.
- Para instalar una biblioteca que solo está disponible para una sesión de cuaderno específica, use bibliotecas de Python con ámbito de cuaderno.