Cree su primer flujo de trabajo con un trabajo de Azure Databricks
En este artículo, se muestra un trabajo de Azure Databricks que organiza las tareas para leer y procesar un conjunto de datos de ejemplo. En esta guía de inicio rápido:
- Crear un cuaderno y agregar código para recuperar un conjunto de datos de ejemplo que contenga nombres populares de bebés por año
- Guarde el conjunto de datos de muestra en Unity Catalog.
- Crear un cuaderno y agregar código para leer el conjunto de datos desde Unity Catalog, filtrarlo por año y mostrar los resultados.
- Crear un trabajo y configurar dos tareas mediante los cuadernos.
- Ejecutar el trabajo y ver los resultados
Requisitos
Si su área de trabajo está habilitada para Unity Catalog y Serverless Jobs está habilitado, por defecto, el trabajo se ejecuta en Serverless compute. No necesita permiso de creación de clústeres para ejecutar el trabajo con proceso sin servidor.
De lo contrario, deberá tener permiso de creación de clústeres para crear procesos de trabajo o permisos para recursos informáticos polivalentes.
Debe tener un volumen en Unity Catalog. En este artículo se usa un volumen denominado my-volume en un esquema denominado default dentro de un catálogo denominado main. Además, debe tener los permisos siguientes en Unity Catalog:
READ VOLUMEyWRITE VOLUME, oALL PRIVILEGES, para el volumenmy-volume.USE SCHEMAoALL PRIVILEGESpara el esquemadefault.USE CATALOGoALL PRIVILEGESpara el catálogomain.
Para establecer estos permisos, consulte el administrador de Databricks o los privilegios de Unity Catalog y objetos protegibles.
Creación de los cuadernos
Recuperación y guardado de datos
Para crear un cuaderno para recuperar el conjunto de datos de ejemplo y guardarlo en Unity Catalog:
Vaya a la página de aterrizaje de Azure Databricks y haga clic en
 Nuevo en la barra lateral y seleccione Notebook. Databricks crea y abre un nuevo cuaderno en blanco en la carpeta predeterminada. El idioma predeterminado es el idioma que ha usado de manera más reciente y el cuaderno se adjunta automáticamente al recurso de proceso que ha usado de manera más reciente.
Nuevo en la barra lateral y seleccione Notebook. Databricks crea y abre un nuevo cuaderno en blanco en la carpeta predeterminada. El idioma predeterminado es el idioma que ha usado de manera más reciente y el cuaderno se adjunta automáticamente al recurso de proceso que ha usado de manera más reciente.Si es necesario, cambie el lenguaje predeterminado a Python.
Copie el código de Python siguiente y péguelo en la primera celda del cuaderno.
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
Lectura y visualización de datos filtrados
Para crear un cuaderno para leer y presentar los datos para filtrarlos:
Vaya a la página de aterrizaje de Azure Databricks y haga clic en
Nuevo en la barra lateral y seleccione Notebook. Databricks crea y abre un nuevo cuaderno en blanco en la carpeta predeterminada. El idioma predeterminado es el idioma que ha usado de manera más reciente y el cuaderno se adjunta automáticamente al recurso de proceso que ha usado de manera más reciente.Si es necesario, cambie el lenguaje predeterminado a Python.
Copie el código de Python siguiente y péguelo en la primera celda del cuaderno.
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
Creación de un trabajo
Haga clic en
 Flujos de trabajo en la barra lateral.
Flujos de trabajo en la barra lateral.Haga clic en el
 .
.La pestaña Tasks (Tareas) se muestra con el cuadro de diálogo Create task (Crear tarea).
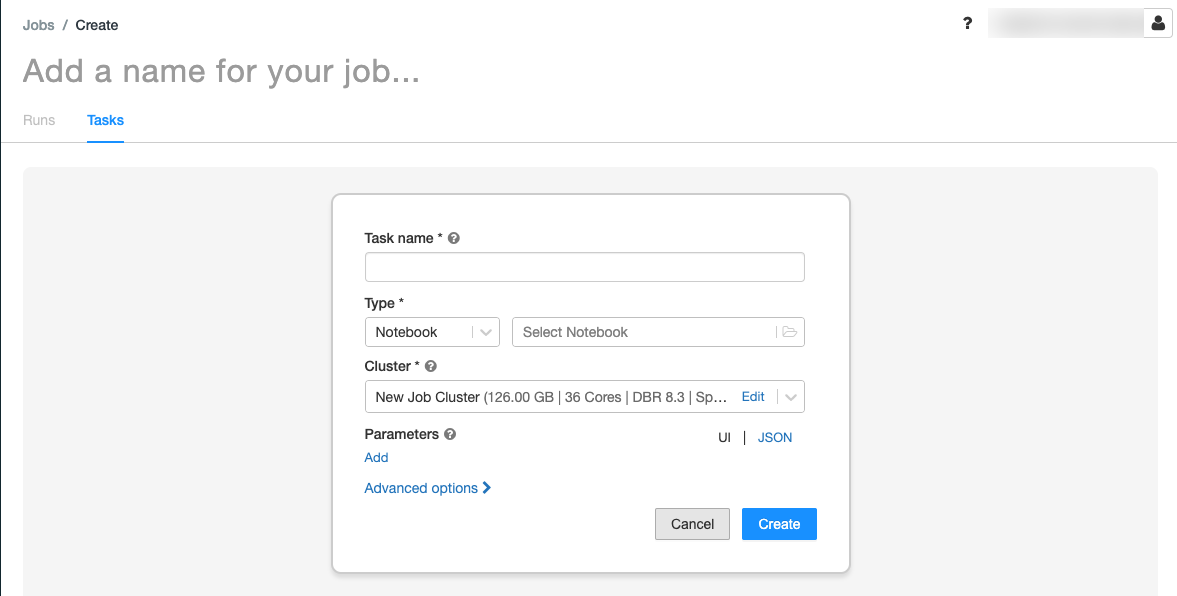
Reemplace Add a name for your job… (Agregar un nombre para el trabajo…) por el nombre del trabajo.
En el campo Task name (Nombre de tarea), escriba un nombre para la tarea; por ejemplo, retrieve-baby-names.
En el menú desplegable Tipo, seleccione Notebook.
Use el explorador de archivos para buscar el primer cuaderno que creó, haga clic en el nombre del cuaderno y haga clic en Confirm (Confirmar).
Haga clic en Create task (Crear tarea).
Haga clic en el
 debajo de la tarea que acaba de crear para agregar otra tarea.
debajo de la tarea que acaba de crear para agregar otra tarea.En el campo Task name (Nombre de tarea), escriba un nombre para la tarea; por ejemplo, filter-baby-names.
En el menú desplegable Tipo, seleccione Notebook.
Use el explorador de archivos para buscar el segundo cuaderno que creó, haga clic en el nombre del cuaderno y haga clic en Confirm (Confirmar).
Haga clic en Add (Agregar) en Parameters (Parámetros). En el campo Key (Clave), escriba
year. En el campo Value (Valor), escriba2014.Haga clic en Create task (Crear tarea).
Ejecutar el trabajo
Para ejecutar el trabajo inmediatamente, haga clic en el  en la esquina superior derecha. También puede ejecutar el trabajo haciendo clic en la pestaña Runs (Ejecuciones) y haciendo clic en Run now (Ejecutar ahora) en la tabla Active Runs (Ejecuciones activas).
en la esquina superior derecha. También puede ejecutar el trabajo haciendo clic en la pestaña Runs (Ejecuciones) y haciendo clic en Run now (Ejecutar ahora) en la tabla Active Runs (Ejecuciones activas).
Visualización de los detalles de ejecución
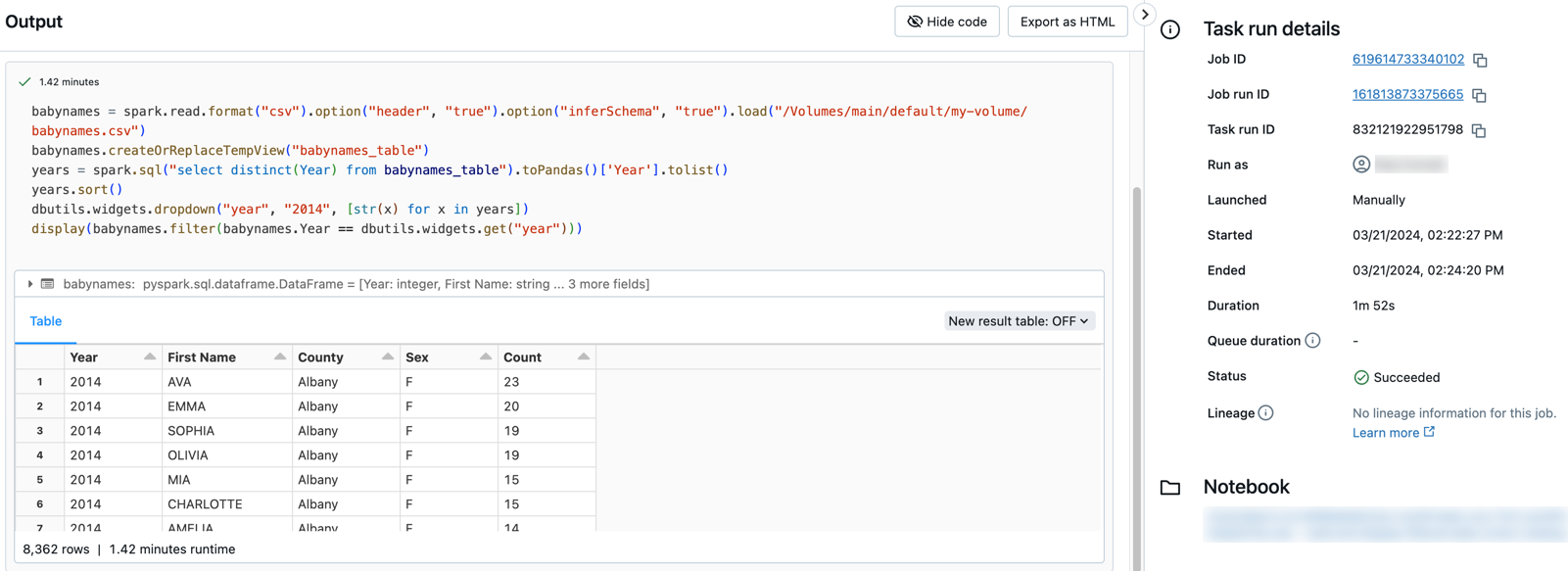
Haga clic en la pestaña Runs y haga clic en el vínculo para la ejecución en la tabla Active Runs o en la tabla Completed Runs (past 60 days).
Haga clic en cualquiera de las tareas para ver la salida y los detalles. Por ejemplo, haga clic en la tarea filter-baby-names para ver la salida y los detalles de la ejecución de la tarea de filtro:
Ejecución con otros parámetros
Para volver a ejecutar el trabajo y filtrar los nombres de bebés para otro año:
- Haga clic en el
 junto a Run now (Ejecutar ahora) y seleccione Run now with different parameters (Ejecutar ahora con parámetros diferentes) o haga clic en Run now with different parameters (Ejecutar ahora con parámetros diferentes) en la tabla Active Runs (Ejecuciones activas).
junto a Run now (Ejecutar ahora) y seleccione Run now with different parameters (Ejecutar ahora con parámetros diferentes) o haga clic en Run now with different parameters (Ejecutar ahora con parámetros diferentes) en la tabla Active Runs (Ejecuciones activas). - En el campo Value (Valor), escriba
2015. - Haga clic en Ejecutar.