Introducción a RAG en el desarrollo de IA
Este artículo es una introducción a la generación aumentada por recuperación (RAG): qué es, cómo funciona y los conceptos clave.
¿Qué es la generación aumentada por recuperación?
RAG es una técnica que permite que un modelo de lenguaje grande (LLM) genere respuestas enriquecidas aumentando la indicación de un usuario con datos auxiliares recuperados de un origen de información externo. Al incorporar esta información recuperada, RAG permite al LLM generar respuestas más precisas y de mayor calidad en comparación con no aumentar la indicación con contexto adicional.
Por ejemplo, supongamos que va a crear un bot de chat de preguntas y respuestas para ayudar a los empleados a responder a preguntas sobre los documentos de propiedad de su empresa. Un LLM independiente no podrá responder con precisión a preguntas sobre el contenido de estos documentos si no se ha entrenado específicamente en ellos. El LLM podría rechazar responder debido a una falta de información o, incluso peor, podría generar una respuesta incorrecta.
RAG soluciona este problema al recuperar primero la información pertinente de los documentos de la empresa en función de la consulta de un usuario y, a continuación, proporcionar la información recuperada al LLM como contexto adicional. Esto permite al LLM generar una respuesta más precisa al extraer los detalles específicos que se encuentran en los documentos pertinentes. En esencia, RAG permite al LLM "consultar" la información recuperada para formular su respuesta.
Componentes principales de una aplicación RAG
Una aplicación RAG es un ejemplo de un sistema de inteligencia artificial compuesto: se expande sobre las funcionalidades de lenguaje del modelo y lo combina con otras herramientas y procedimientos.
Cuando se usa un LLM independiente, un usuario envía una solicitud, como una pregunta, al LLM y este responde con una respuesta basada únicamente en sus datos de entrenamiento.
En su forma más básica, los pasos siguientes se realizan en una aplicación RAG:
- Recuperación: la solicitud del usuario se usa para consultar algún origen de información externo. Esto puede significar consultar un almacén vectorial, realizar una búsqueda de palabras clave en algún texto o consultar una base de datos SQL. El objetivo del paso de recuperación es obtener datos auxiliares que ayuden al LLM a proporcionar una respuesta útil.
- Aumento: los datos auxiliares del paso de recuperación se combinan con la solicitud del usuario, a menudo usando una plantilla con formato e instrucciones adicionales para el LLM, para crear una indicación.
- Generación: la indicación resultante se pasa al LLM y este genera una respuesta a la solicitud del usuario.
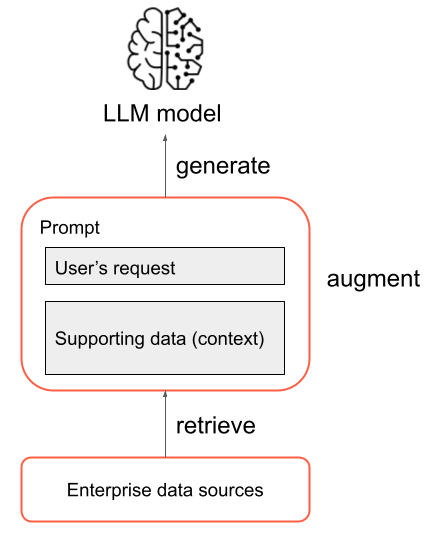
Se trata de una visión general simplificada del proceso RAG, pero es importante tener en cuenta que la implementación de una aplicación RAG conlleva muchas tareas complejas. Procesar previamente los datos de origen para que sean adecuados para su uso en RAG, recuperar datos de forma eficaz, dar formato a la indicación aumentada y evaluar las respuestas generadas requieren una cuidadosa consideración y esfuerzo. Estos temas se tratarán con más detalle en secciones posteriores de esta guía.
¿Por qué usar RAG?
En la tabla siguiente se describen las ventajas de usar RAG frente a un LLM independiente:
| Con un LLM solo | Uso de LLM con RAG |
|---|---|
| Sin conocimiento de la propiedad: los LLM se entrenan con carácter general sobre los datos disponibles públicamente, por lo que no pueden responder con precisión a preguntas sobre los datos internos o propiedad de una empresa. | Las aplicaciones RAG pueden incorporar datos de propiedad: una aplicación RAG puede proporcionar documentos de propiedad, como memos, correos electrónicos y documentos de diseño a un LLM, lo que le permite responder a preguntas sobre esos documentos. |
| El conocimiento no se actualiza en tiempo real: los LLM no tienen acceso a información sobre los eventos que se produjeron después de que se entrenaron. Por ejemplo, un LLM independiente no puede decir nada sobre los movimientos de las acciones de hoy. | Las aplicaciones RAG pueden acceder a datos en tiempo real: una aplicación RAG puede proporcionar el LLM información oportuna de un origen de datos actualizado, lo que le permite proporcionar respuestas útiles sobre los eventos pasados de su fecha límite de entrenamiento. |
| Falta de citas: los LLM no pueden citar fuentes específicas de información al responder, lo que deja al usuario incapaz de comprobar si la respuesta es ciertamente correcta o una alucinación. | RAG puede citar orígenes: cuando se usa como parte de una aplicación RAG, se puede pedir a un LLM que cite sus orígenes. |
| Falta de controles de acceso a datos (ACL): los LLM por sí solos no pueden proporcionar respuestas diferentes a distintos usuarios en función de permisos de usuario específicos. | RAG permite la seguridad de los datos o ACL: el paso de recuperación se puede diseñar para encontrar solo la información para la que el usuario tiene credenciales de acceso, lo que permite que una aplicación RAG recupere de forma selectiva información personal o de propiedad. |
Tipos de RAG
La arquitectura RAG puede funcionar con dos tipos de datos auxiliares:
| Datos estructurados | Datos no estructurados | |
|---|---|---|
| Definición | Datos tabulares organizados en filas y columnas con un esquema específico, por ejemplo, tablas de una base de datos. | Datos sin una estructura u organización específicas, por ejemplo, documentos que incluyen texto e imágenes o contenido multimedia, como audio o vídeos. |
| Orígenes de datos de ejemplo | - Registros de clientes en un sistema BI o de almacenamiento de datos - Datos de transacciones de una base de datos SQL - Datos de las API de aplicación (como SAP, Salesforce, etc.) |
- Registros de clientes en un sistema BI o de almacenamiento de datos - Datos de transacciones de una base de datos SQL - Datos de las API de aplicación (como SAP, Salesforce, etc.) - Documentos PDF - Documentos de Google o Microsoft Office - Wikis - Imágenes - Vídeos |
Su elección de datos para RAG depende de su caso de uso. El resto de la guía paso a paso se centra en RAG para datos no estructurados.